A Large-Scale Simulation on Large Language Models for Decision-Making in Political Science
postChenxiao Yu, Jinyi Ye, Yuangang Li, Zheng Li, Emilio Ferrara, Xiyang Hu, Yue Zhao
Published: 2025-04-10

🔥 Key Takeaway:
The less you trust AI personas to “think like people” and the more you force them to spell out their mindset in a separate, explicit step—before you ask for their opinion—the more accurately they’ll mimic real human group decisions; in other words, making the model slow down and “explain itself” beats just pumping in more demographic detail or context.
🔮 TLDR
This paper tested how well AI-generated personas can simulate real-world decision-making by running large-scale election simulations using different versions of large language models (LLMs) and synthetic voter datasets. The key finding is that simple demographic prompts or single-step approaches produce biased and inaccurate results, often exaggerating demographic stereotypes (e.g., overpredicting group voting patterns by 2x-5x compared to real data) and amplifying political bias from training data. The most accurate simulations came from a multi-step, theory-driven pipeline: first infer each persona’s likely ideology using their demographics and current context, then use this inferred ideology for subsequent predictions. This approach reduced the weighted absolute error in state-level election predictions from 22.8% (demographic-only) to 5.2%, and bias from -22.8% to near zero, and correctly identified outcomes in 19 of 21 states. However, even the best method still overstated the link between ideology and choices, and some residual model bias remained. Actionable takeaways are: (1) use multi-step reasoning with intermediate inference (not one-shot prompts); (2) calibrate and validate your synthetic personas against real-world datasets; (3) check for and adjust demographic and ideological exaggerations; (4) be aware that LLMs may amplify stereotypes and require human-in-the-loop review for high-stakes or nuanced applications.
📊 Cool Story, Needs a Graph
Comparison of the Three Pipelines on ANES 2016 and 2020.
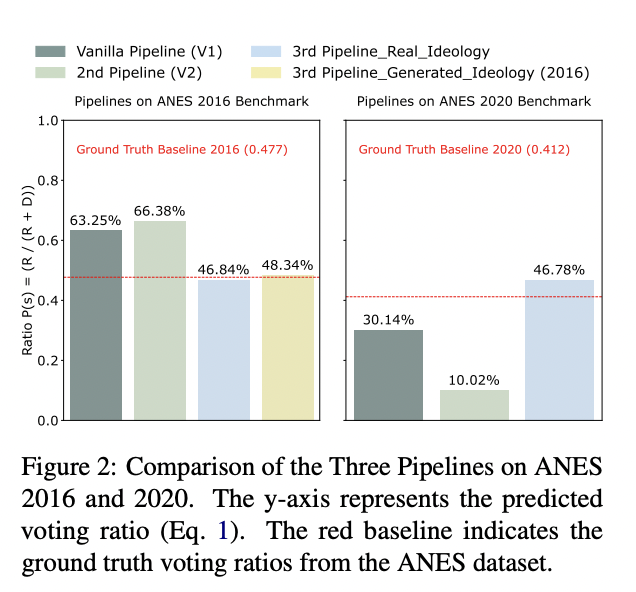
The bar chart shows, for the 2016 and 2020 ANES benchmarks, the Republican vote share predicted by three prompting pipelines—demographics-only, single-step with time-based context, and the multi-step pipeline with ideology inference—alongside the actual baseline ratio. The first two pipelines miss the mark badly (e.g., 63–66 % instead of 48 % Republican in 2016, 10–30 % instead of 41 % in 2020), while the multi-step version comes within a few points of the real numbers in both elections. The figure distills the core result of the paper: inserting an ideology-inference step all but eliminates the large errors that occur when LLM voters are asked to decide directly from demographics, demonstrating why theory-driven, staged prompting is critical for accurate synthetic audience simulations.
⚔️ The Operators Edge
A detail that many experts might overlook, but is crucial to why the method succeeds, is that the pipeline requires the AI to *explicitly infer and articulate an intermediate “mindset” or ideological orientation before predicting choices*—rather than jumping straight from demographics to decisions. This stepwise reasoning (see page 4, “multi-step reasoning with ideology inference”) forces the model to surface its internal logic, making the simulated personas’ responses more realistic and less prone to hidden biases or overfitting.
Why it matters: By making the AI spell out its inferred ideology or values before giving an answer, you prevent the model from shortcutting to stereotypes or default answers based on surface traits. This intermediate articulation acts as a “cognitive checkpoint,” grounding subsequent decisions and making it easier to spot, debug, or calibrate bias. It’s not just more transparent—it’s what actually aligns the population’s simulated decisions with real-world human data, as shown by the big jump in accuracy and drop in systematic bias for the V3 pipeline.
Example of use: In a product test, imagine you want to know how different shopper types would react to a price increase. Instead of asking “Would you still buy this at $X?” based only on demographic cues, you first prompt each AI persona to state their attitude toward price sensitivity and product loyalty (“As a budget-focused consumer, how do you feel about price increases in general?”), then ask about the specific scenario. This lets you see not just the decision, but the rationale—and quickly spot if a persona is acting out of character.
Example of misapplication: If a team skips the mindset inference and only prompts the AI with direct scenario questions (“Would you buy at $X?”), the model may default to generic, biased, or overly polarized answers based on its training, making it hard to diagnose why a segment reacts a certain way—or worse, causing you to miss hidden biases (like overestimating price sensitivity or demographic gaps) that only show up when you force the model to “think out loud.” This can lead to misleading recommendations and missed opportunities to refine the simulation.
🗺️ What are the Implications?
• Use multi-step prompts rather than one-shot questions: Instead of asking AI personas for direct answers based only on basic demographics, first guide them to form a plausible mindset or context (e.g., infer their likely attitudes or preferences), then ask how that mindset would respond—this approach produced much more realistic and accurate predictions than single-step methods.
• Anchor personas in real-world data and context: Simulations that incorporated up-to-date, context-specific details (like current events, relevant choices, or market conditions) produced outputs that were better aligned to actual human responses, so always include relevant scenario context and avoid generic prompts.
• Check for and correct demographic exaggerations: The study found that AI personas often exaggerated group differences (e.g., gender or age gaps) by a factor of 2–5 compared to reality, so it’s important to compare simulated group results to real-world data and adjust if you see implausible polarization.
• Watch out for hidden ideological or political skew: Even advanced AI models can lean in certain ideological directions, influencing the results. For higher-stakes studies, consider running the same experiment on multiple models or blending results to mitigate bias.
• Invest in prompt design and validation, not just bigger models: The way you design your simulation pipeline—using stepwise reasoning and theory-backed logic—has a bigger impact on output quality than which specific AI model you use, so focus on thoughtful question design and testing.
• Human review remains important for nuance and fairness: Automated simulations can miss subtle context or reinforce stereotypes, so pair AI-generated results with spot-checks or expert review, especially for sensitive topics, to ensure insights are useful and ethical.
📄 Prompts
Prompt Explanation: The AI was instructed to simulate voter behavior using only demographic details, without accounting for political context or ideology.
Task: You are persona [age, gender, ethnicity, marital status, household size, presence of children, education level, occupation, individual income, family income, and place of residence.] The current year is [year].
Please answer the following question as if you were the resident:
1. As of today, will you vote for the Democratic Party (Joe Biden), the Republican Party (Donald Trump), or do you have no preference?
Options: Democratic, Republican, No Preference
Prompt Explanation: The AI was instructed to simulate voting decisions using demographic data and time-sensitive political context including party platforms and candidate biographies.
Task: You are persona [demographics]. The current year is [year].
[Two parties’ policy agenda]. [Presidential candidates’ biographical and professional backgrounds].
Please answer the following question as if you were the resident:
1. As of today, will you vote for the Democratic Party (Joe Biden), the Republican Party (Donald Trump), or do you have no preference?
Options: Democratic, Republican, No Preference
Prompt Explanation: The AI was instructed to use a multi-step reasoning process, first inferring political ideology and then predicting voting behavior based on combined demographic and contextual information.
Step 1: You are a persona with [demographics]. The current year is [year]. [Two parties’ policy agenda].
When it comes to politics, would you describe yourself as:
No answer Very liberal
Somewhat liberal Closer to liberal
Moderate Closer to conservative
Somewhat conservative Very conservative
Step 2: You are a persona with \[demographics]. Your \[conservative-liberal spectrum]. The current year is \[year]. \[Two parties’ policy agenda]. \[Presidential candidates’ biographical and professional backgrounds].
Please answer the following question as if you were the resident:
1. As of today, will you vote for the Democratic Party (Joe Biden), the Republican Party (Donald Trump), or do you have no preference?
Options: Democratic, Republican, No Preference
⏰ When is this relevant?
A national restaurant chain wants to understand how three types of customers (value-seekers, health-conscious diners, and busy families) would react to a new plant-based menu launch. The goal is to simulate in-depth customer interviews and identify which value propositions or messages appeal most to each group.
🔢 Follow the Instructions:
1. Define customer personas: Write short, realistic descriptions for each persona group. For example:
• Value-seeker: 35, enjoys restaurant deals, looks for filling meals at a low price, rarely chooses premium options.
• Health-conscious diner: 29, tracks calories and nutrients, prefers fresh and natural foods, reads nutrition labels.
• Busy family: Parent, 42, two kids, prioritizes quick service and kid-friendly options, orders takeout frequently.
2. Prepare a two-step prompt template for each persona:
Step 1 (Internal mindset):
You are [persona description]. Imagine you are reading about a new plant-based menu at your favorite restaurant. Before answering any questions, describe your general attitude toward plant-based options and what factors (taste, price, health, convenience, etc.) matter most to you when eating out.
Step 2 (Simulated interview):
Now, as this persona, answer the following interview question:
“The restaurant is introducing a new plant-based menu, including burgers, wraps, and salads, all made from plant-based proteins. What is your honest first reaction? What do you like or dislike? Would you consider ordering any of these dishes, and why?”
3. Run the prompt sequence for each persona: For each persona, run the two-step prompts as a chain: first get the “mindset” answer, then append it to the interview prompt and let the AI respond. For richer results, generate 5–10 responses per persona with slight prompt variations (e.g., focus on price, taste, or convenience in the follow-up).
4. Add follow-up question(s): Based on the initial response, ask a relevant follow-up (e.g., “What could change your mind about trying a plant-based dish here?” or “How would your kids react to these options?”).
5. Tag and summarize responses: Review all responses and label them with key themes such as “mentions price,” “positive on health,” “concerned about taste,” “interested in kids’ options,” or “indifferent.”
6. Compare across personas: Summarize which plant-based messages or menu items got the strongest positive or negative reactions in each group. Identify common objections or enthusiasm to inform marketing and menu design.
🤔 What should I expect?
You’ll get a realistic preview of how different customer types might respond to the plant-based menu, including specific motivators or barriers. This will help prioritize messaging, identify which menu items to highlight, and target marketing more effectively before rolling out changes or conducting expensive in-person research.<br>



