A Survey of 15 Years of Data-Driven Persona Development
postJoni Salminen, Kathleen Guan, Soon-Gyo Jung, Bernard J. Jansen
Published: 2021-04-12

🔥 Key Takeaway:
The more you automate persona creation and rely on pure data or algorithms, the more you actually need manual, subjective judgment to make the results useful—so the big win isn’t full automation, but mixing rigorous data-driven methods with hands-on human interpretation to get personas that are both scalable and truly actionable.
🔮 TLDR
This paper reviews 77 studies on data-driven persona development (DDPD) from 2005–2020 and finds that while automated, quantitative methods like clustering (especially k-means, used in 19.5% of papers) and matrix factorization are now common for generating personas from surveys, web, and behavioral data, these approaches still require significant manual steps and judgment calls (e.g., setting parameters, writing persona narratives), and lack standardization in evaluation or resource sharing. Combining quantitative and qualitative methods is recommended for both breadth and depth—40% of studies used mixed approaches. Key challenges include bias in both data and algorithms, difficulty generalizing personas across contexts or platforms, and a tendency to overlook minority or outlier groups, risking shallow or non-inclusive results. The field lacks shared datasets or code, and practical validation (i.e., testing if personas actually improve decision-making) is rare. Actionable recommendations for practitioners are: don’t rely solely on statistical outputs—combine clustering with qualitative checks; be wary of algorithmic and data biases; ensure minority perspectives are represented; and iteratively validate personas against real-world outcomes. The usefulness of DDPD depends on access to large, varied, well-structured datasets and organizational readiness; otherwise, traditional manual persona development may still be more practical.
📊 Cool Story, Needs a Graph
Figure 1:
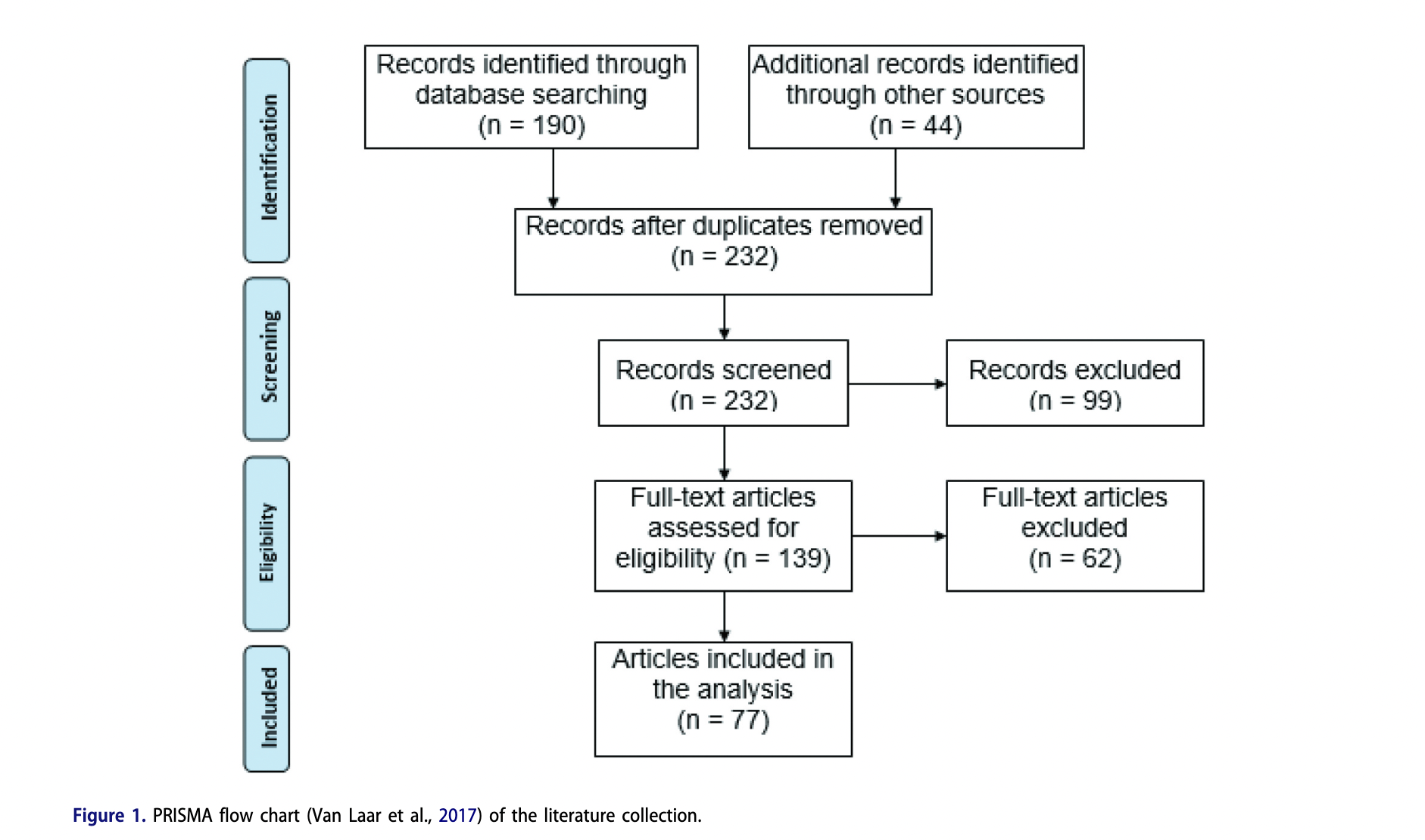
Visual representation of the iterative steps involved in creating data-driven personas.
This figure illustrates the comprehensive process of developing data-driven personas, starting from data collection, moving through data processing and analysis, and culminating in the creation and validation of personas. It emphasizes the iterative nature of the process, allowing for continuous refinement based on new data and feedback. The diagram also highlights the integration of both qualitative and quantitative data sources, ensuring a holistic approach to persona development.
🗺️ What are the Implications?
• Combine quantitative and qualitative methods for best results: Studies show that mixing data-driven approaches (like clustering or statistical modeling) with qualitative feedback (such as interviews or observations) produces richer, more realistic personas and market simulations.
• Don’t rely only on automation—human judgment is still needed: While algorithms can handle large datasets and speed up persona creation, the final outputs require manual interpretation and enrichment to avoid shallow or generic results.
• Check your data for gaps and biases before running experiments: Many market research failures come from using incomplete, skewed, or non-representative data sources. Validating and diversifying your inputs helps prevent misleading conclusions.
• Make sure to represent minority and outlier groups: Most automated methods focus on the “average” customer, but ignoring smaller segments risks missing new opportunities or sources of risk. Consider creating separate personas for minority groups or “fringe” users.
• Don’t just accept model outputs—ask critical questions: Treat the results of automated persona generation as hypotheses, not facts. Stakeholders should challenge how the data was processed, how personas were grouped, and whether the outputs match their own experience or customer knowledge.
• Validate simulated findings with real user feedback where possible: Even small-scale human interviews or quick user tests can catch errors or blind spots in synthetic market research, making your results more credible and actionable.
• Understand your organization’s “data readiness”: Data-driven approaches work best for companies with large, well-organized, and diverse customer data. If you lack sufficient digital data or only serve a narrow market, traditional qualitative research may be more effective and cost-efficient.
• Be aware of algorithmic bias and the “mystique of numbers”: More data and fancier algorithms don’t guarantee better accuracy. Funders and researchers should be cautious of overconfidence in quantitative results and always seek transparency about how personas and insights are generated.
⏰ When is this relevant?
A national grocery chain is planning to launch a new premium store brand for healthy snacks and wants to predict how different customer segments will respond to the new range, focusing on value, health claims, and packaging. They want quick, actionable insights from synthetic interviews with AI personas representing key shopper types, without running a full-scale survey.
🔢 Follow the Instructions:
1. Define audience segments: Identify 3–5 realistic customer segments based on internal data or typical grocery demographics. Example segments:
• Health-focused urban professionals (age 28–45, higher income, fitness-oriented)
• Budget-conscious families (parents 30–50, middle income, shopping for kids)
• Older traditional shoppers (age 55+, moderate income, loyal to classic brands)
2. Write persona briefs for each segment: For each segment, create a short persona description with relevant attributes. Example:
Name: Emily
Age: 35
Family: Married, 2 children
Shopping habits: Looks for value packs, reads nutrition labels, shops weekly in-store
Priorities: Healthy snacks for kids, price-sensitive, avoids artificial ingredients
3. Prepare a prompt template for interviews: Use this format for each AI persona:
You are [insert persona description].
You’re shopping for snacks and see a new premium store brand range with “no artificial ingredients,” “added protein,” and bright packaging, priced 20% above regular store brands.
A market researcher asks: “What is your first impression of these snacks? Would you consider buying them? Why or why not?”
Respond as this persona in 3–5 sentences, focusing on your honest reaction.
4. Run the prompts with the AI model: For each persona, generate 5–10 responses using the prompt above. Vary the question slightly to simulate interviewer style (e.g., “How does this product fit your usual snack choices?” or “What would make you try or avoid this?”).
5. Follow up for deeper insights: Ask a follow-up for each persona’s response, such as:
“What would make you choose this snack over your usual brand?”
“Does the price make a difference to your decision?”
“What do you think of the packaging and health claims?”
6. Tag and summarize key themes: Review all responses and highlight common decision drivers (e.g., mentions of price, trust in health claims, packaging appeal, family influence). Use tags like “concerned about price,” “excited by health benefits,” “doubts about new brand,” or “attracted by packaging.”
7. Compare across segments: Summarize which features or objections show up most in each group. Note where responses differ (e.g., health-focused professionals care about protein claims; budget families focus on price; older shoppers are skeptical of new brands).
🤔 What should I expect?
You’ll quickly see which customer segments are most open to the premium snack line, what messages matter most, and where resistance or confusion exists. This helps you refine marketing, set pricing strategies, and decide if and how to prioritize launch campaigns or follow-up research with real customers.



