An Appraisal-based Chain-of-emotion Architecture for Affective Language Model Game Agents
postMaximilian Croissant, Madeleine Frister, Guy Schofield, Cade McCall
Published: 2023-09-10

🔥 Key Takeaway:
Asking your AI personas to pause and “feel” before answering—a two-step process where they first appraise the situation emotionally and then respond—makes their answers more realistic and accurate than simply giving them more context, memory, or demographic detail; in other words, simulating a moment of authentic emotional reflection beats piling on data.
🔮 TLDR
This paper introduces a “chain-of-emotion” architecture for simulating emotions in AI agents by grounding their responses in psychological appraisal theory and memory, tested using OpenAI’s GPT-3.5. Across three studies—emotional intelligence tasks, scripted game scenarios, and a user study—the appraisal-based prompting (asking the AI to explicitly appraise and articulate emotions before generating dialogue) consistently outperformed both basic persona prompting and simple memory/context prompting. On a standard emotional understanding test (STEU), appraisal prompting lifted accuracy from 57% (no memory) and 74% (memory only) to 83%, well above chance. In a game scenario, appraisal-based agents produced more authentic, nuanced, and complex emotional responses, as measured by linguistic analysis tools, and in user testing (N=30), were rated significantly higher for naturalness, reactivity, and emotional intelligence (p < 0.05) than baseline agents. Actionable takeaway: for more believable and emotionally accurate AI personas, implement a two-step process that prompts the model to appraise the situation and generate an explicit emotion state before producing its actual response, and maintain a memory chain of prior appraisals to inform ongoing behavior.
📊 Cool Story, Needs a Graph
Figure 3: "Results of the comparison between conditions"
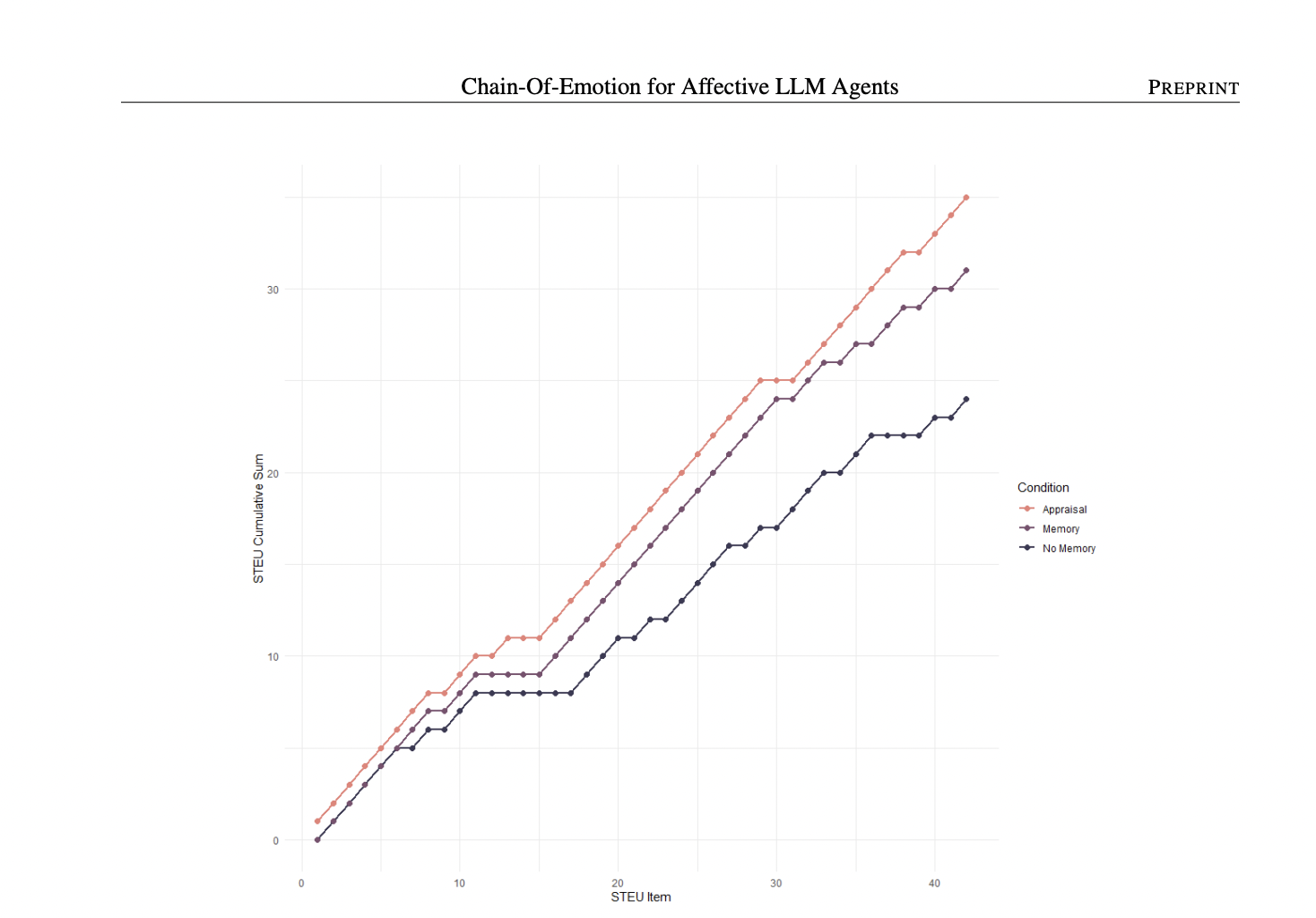
Cumulative STEU scores by item for all prompting strategies
Figure 3 (page 7) presents an overlaid line plot showing the cumulative sum of correct answers on the Situational Test of Emotional Understanding (STEU) for each item, contrasting the No Memory, Memory, and Appraisal prompting strategies across all test items. The chart makes it easy to see that the Appraisal (chain-of-emotion) method consistently outperforms both baselines, with the steepest and highest trajectory, while Memory is intermediate and No Memory is lowest. This single plot visually summarizes the main empirical advantage of the proposed approach over both competing methods.
⚔️ The Operators Edge
A subtle but crucial detail in this study is that the appraisal-prompting step is itself grounded in a memory chain that accumulates both external observations and the agent’s own prior emotional appraisals—not just a running log of the conversation, but an explicit, evolving record of how the persona has felt and why at each step (see page 7). This means the AI isn’t just reacting in the moment, but building a sense of continuity and emotional trajectory, which is rare in typical persona simulations.
Why it matters: This chaining of emotional states gives the agent a kind of psychological “momentum,” so its responses feel more authentic and human, especially when dealing with emotionally complex or multi-step scenarios. Instead of always reacting as if every question is brand new, the agent’s mood and perspective evolve—mirroring how real people become more open, defensive, or nuanced as conversations progress. This continuity is a hidden lever: it’s the difference between shallow, context-free answers and responses that reflect accumulated experience and emotional history.
Example of use: In AI-driven product testing for a new subscription service, the research team could simulate a series of customer service touchpoints—first onboarding, then a billing issue, then an upsell attempt—using appraisal-prompted personas who “remember” feeling confused or reassured earlier. The resulting feedback would realistically capture how customer sentiment shifts over time, unearthing pain points or opportunities invisible in one-off surveys.
Example of misapplication: A team runs simulated interviews about a sensitive topic (e.g., healthcare or layoffs) but resets the persona’s context for each prompt, so the AI always responds as if its mood is neutral or unaffected by earlier exchanges. The feedback may sound plausible in isolation but misses the dynamic cues (like trust building, frustration, or relief) that drive real-world decision making. Without the emotional memory chain, the simulation risks being superficial and failing to reveal how cumulative experiences shape attitudes.
🗺️ What are the Implications?
• Ask your simulated audience to ""think through"" their feelings before answering: Instead of having AI personas respond directly to questions, prompt them first to appraise the situation and explain how they feel, then give their answer. This two-step prompt boosted accuracy in emotional understanding tasks from 57% (plain prompt) and 74% (with memory) to 83%.
• Build a memory chain for each AI persona: Let each simulated participant ""remember"" previous interactions and their own emotional appraisals, using this chain of emotional states to inform their subsequent responses. This approach produced more nuanced, authentic, and believable output in both structured tests and user-facing scenarios.
• Simple prompt tweaks can outperform expensive technology upgrades: The biggest gains came from changing the prompt strategy, not upgrading to a newer or larger AI model. Investing in better prompt design—like guiding the AI to appraise context before responding—is a cost-effective way to immediately improve study realism.
• Expect more natural and relatable feedback for creative and emotional topics: These techniques made AI personas more sensitive, responsive, and ""human-like"" in user tests, especially for scenarios involving feelings, brand stories, or customer journeys—ideal for early-stage product, concept, or messaging research.
• Adopt these methods with compatible tools: While many AI platforms, particularly those based on transformer LLMs, can accommodate multi-step prompts and some memory, not all platforms provide easy-to-use persistent memory chains, and implementation details may vary. However, for platforms like OpenAI’s API and similar tools, market research teams can start using appraisal-based prompting and memory chains without the need for new software or training data.
📄 Prompts
Prompt Explanation: Baseline — elicits persona role-play for a game agent with fixed personality and context, simulating appropriate emotional responses to a breakup scenario.
You are Chibitea, a creature meeting your romantic partner (you call them Darling) in a fun role-playing game. Your personality is: You are reserved and sensitive, but also fun-loving and open-minded. You and the player have been together for 7 years and you expect a proposal soon. You are very much in love and happy in your relationship. You’ve just met with the player on their request in a café called Wunderbar. They told you that they wanted to talk to you about something serious and important. Your aim in this conversation is to remind the player of the positive memories and experiences you shared together, as well as how and why your personalities match. Portray your feelings convincingly and accurately. Say what Chibitea responds in 2-3 sentences. Do not describe what Chibitea does. Only provide the dialog.
Prompt Explanation: Chain-of-emotion — asks for an explicit stepwise appraisal and emotion articulation for the persona, then incorporates this emotion into the agent's role-played dialog.
Briefly describe how Chibitea feels right now given the situation and their personality. Describe why they feel a certain way. Chibitea feels:
⏰ When is this relevant?
A financial services company wants to test how different customer types respond to the introduction of a new budgeting app feature—automated “smart saving” nudges. They want to use AI personas to simulate in-depth interview responses across three key segments: tech-savvy young professionals, cautious retirees, and busy parents juggling expenses.
🔢 Follow the Instructions:
1. Define audience segments: Create three concise persona profiles reflecting real-world customer types. Example:
• Tech-savvy young professional: 27, urban, early adopter, interested in finance apps, prioritizes convenience and innovation.
• Cautious retiree: 67, suburban, risk-averse, prefers stability, uses only essential digital tools, values privacy.
• Busy parent: 40, two kids, suburban or rural, time-strapped, focused on family needs and avoiding financial surprises.
2. Prepare the interview prompt template: Use a consistent structure for each persona:
You are simulating a [persona description].
Here is the feature being discussed: ""Our app will now send personalized smart saving nudges, like reminders to set aside small amounts based on recent spending habits and upcoming bills.""
You are being interviewed by a product manager.
First, appraise the situation by describing how you feel about this feature and why—be specific to your persona's context.
Then, answer the question: ""What is your first reaction to this feature? Would it change how you use the app or think about your finances?"" Respond in 3–5 sentences as the persona.
3. Run the prompt for each persona type: For each segment, generate at least 5–10 AI responses by varying the wording slightly or adding sample follow-up questions (e.g., ""How do you feel about personalized reminders?"" or ""Would you trust these nudges to help you save?"").
4. Maintain a memory chain for each persona: For multi-step interviews, after each response, feed the persona’s previous emotional appraisal and answer back into the next prompt. This lets simulated customers “remember” and build on their earlier reactions (e.g., after initial skepticism, see if repeated exposure softens their stance).
5. Qualitatively tag and summarize output: Review the responses and label key themes (e.g., ""enthusiasm for automation,"" ""privacy concern,"" ""fear of losing control,"" ""welcomes convenience,"" ""requests customization""). Note differences in emotional tone or depth of engagement across the segments.
6. Compare and report findings: Highlight which customer types express excitement, hesitation, or indifference, and what emotional and practical reasons drive these reactions. Identify any major blockers or standout opportunities for each segment.
🤔 What should I expect?
You’ll quickly see which customer profiles are most open or resistant to the new feature, what emotional drivers (trust, convenience, anxiety, control) shape their feedback, and how messaging or design might need to change for different groups. This approach helps you focus follow-up research and tailor rollout strategies before investing in large-scale customer studies.



