Can Large Language Models Estimate Public Opinion About Global Warming? An Empirical Assessment of Algorithmic Fidelity and Bias
postSanguk Lee, Tai-Quan Peng, Matthew H. Goldberg, Seth A. Rosenthal, John E. Kotcher, Edward W. Maibach, Anthony Leiserowitz
Published: 2024-08-07

🔥 Key Takeaway:
You get far more realistic simulated survey results by dropping the obsession with detailed demographics and instead anchoring each AI persona in just one or two key attitudes—so a single answer about personal engagement or topic awareness outperforms a full page of background data.
🔮 TLDR
This study tested whether large language models (like GPT-4 and GPT-3.5) can accurately simulate public opinion survey results, using global warming as a test case. The main finding is that LLMs only reliably match real-world survey data when they are given both demographic details (like age, race, education) and specific psychological or behavioral covariates (such as personal engagement with the issue and awareness of scientific consensus); using demographics alone leads to major distortions and overestimation of mainstream opinions. When both types of information are included, GPT-4’s accuracy in replicating survey responses on climate questions ranged from 53% to 91%, and its pattern of correlations between variables closely matched real survey data (mean Cramer’s V difference of 0.04). However, the models showed notable bias, especially underestimating the beliefs of Black Americans, even with full conditioning. The paper recommends that for synthetic research, LLMs should always be conditioned on a broad set of relevant covariates (not just demographics), model selection matters (GPT-4 outperforms GPT-3.5), and answer options should be structured carefully (fewer/vaguer options reduce accuracy). LLMs are cost-efficient and fast for generating synthetic survey data, but should be used as a complement to—not a replacement for—traditional research, and ongoing validation plus bias auditing are essential, especially for minority or underrepresented groups.
📊 Cool Story, Needs a Graph
Figure 1 (page 7): "Belief that Global Warming is Happening,"
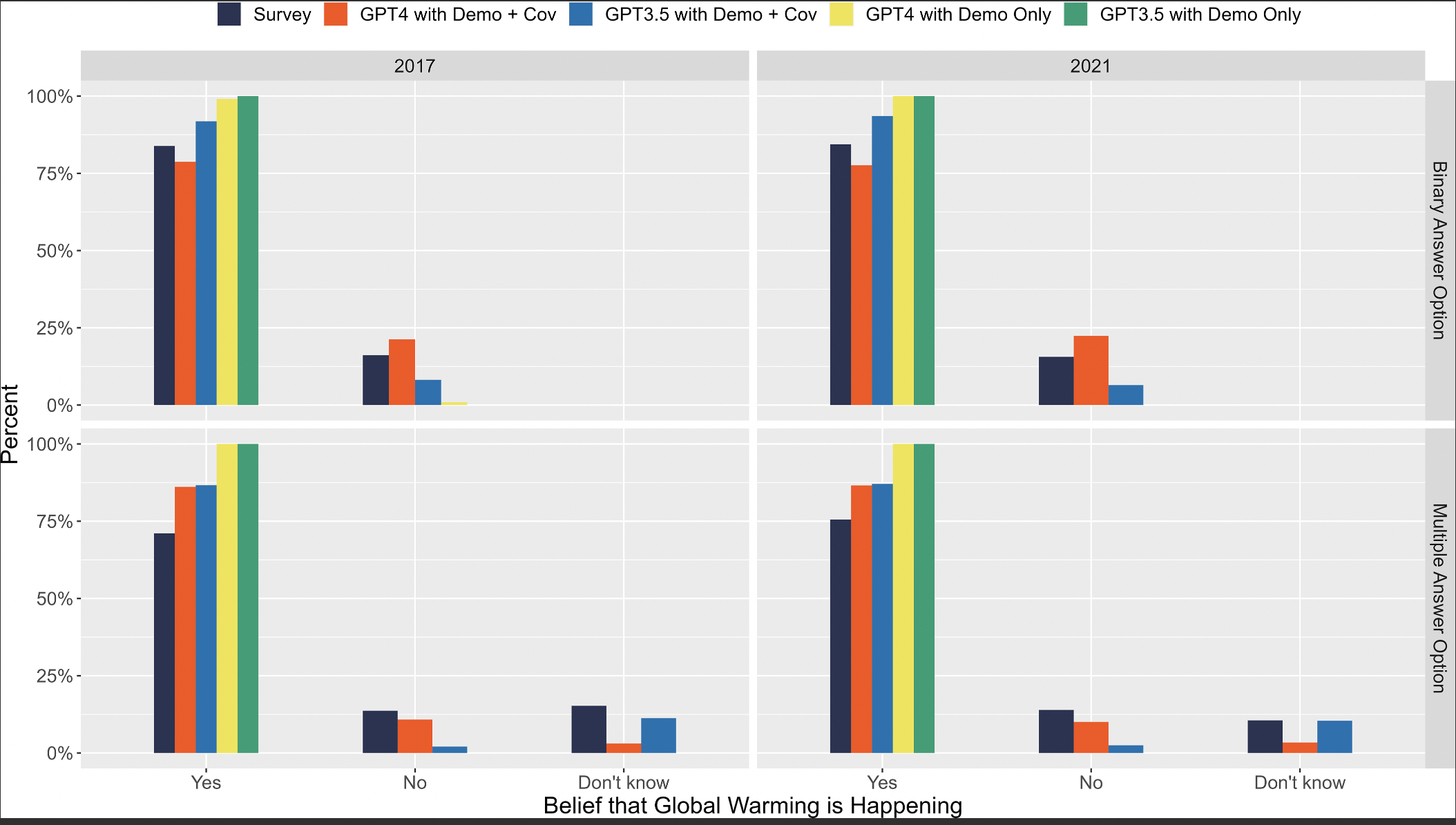
Comparison of survey and GPT-generated responses on belief in global warming, with and without covariate conditioning.
Figure 1 presents a side-by-side comparison of human survey responses and GPT-generated outputs regarding the belief that global warming is happening. The figure illustrates how GPT models, when conditioned solely on demographics (""Demo Only""), tend to overestimate affirmative responses compared to actual survey data. However, when additional covariates related to climate change perceptions are included in the prompts (""Demo + Cov""), the GPT-generated distributions align more closely with the survey results. This demonstrates the importance of incorporating relevant psychological variables to improve the fidelity of AI-simulated public opinion data."
⚔️ The Operators Edge
A detail that most experts might overlook is just how crucial it is to include *issue-specific psychological covariates* (like personal involvement, frequency of discussion, or awareness of scientific consensus) alongside demographics when conditioning AI personas. The study demonstrates that these attitudinal signals—not just age, race, or political party—are the hidden engine that lets the model replicate real-world response distributions and subgroup differences, with accuracy boosts of 30+ percentage points in some cases (see results and discussion around Table 1 and Figure 1).
Why it matters: This means that in AI-driven research, realism doesn’t come from just mimicking population-level demographics or big census data, but from capturing the key psychological levers that shape how people actually think and talk about a topic. These covariates act as “mindset anchors,” steering the model to generate responses that match real public opinion—especially for nuanced or controversial issues—rather than just producing generic, majority-friendly answers.
Example of use: A team running synthetic market research for a new electric vehicle could condition AI personas not only on standard demographics, but also on attitudes like “frequency of discussing climate change” or “personal importance of sustainable transportation.” This allows them to see how both eco-enthusiasts and skeptical segments might respond to messaging, yielding insights that mirror the diversity found in real customer interviews.
Example of misapplication: A team skips the attitudinal step and only builds personas with demographic profiles (e.g., “35-year-old male, suburban, college-educated”) for a concept test. The simulated responses all cluster around bland, majority opinions, missing the strong “for” and “against” views that would emerge in real focus groups—leading the business to misjudge risk, opportunity, or backlash when the product launches.
🗺️ What are the Implications?
• Always supplement basic demographics with relevant attitudinal or behavioral variables: The study found that using only demographics (like age or gender) leads to inaccurate and unrealistic simulation results, while including variables such as personal engagement and topic awareness can dramatically boost accuracy—sometimes by over 30 percentage points.
• Pick the right model for your simulation—GPT-4 outperformed GPT-3.5 when given the same inputs: While both models improved with better conditioning, GPT-4 consistently produced results that were closer to real-world survey data, suggesting it’s a safer bet for high-stakes or client-facing projects.
• Be cautious with broad or ambiguous answer options (“Don’t know”, etc.): Simulations were less accurate when answer choices were vague or overly broad; tightening survey-style answer options improved the reliability of model outputs.
• Validate simulated results for underrepresented groups: The study revealed that even the best-tuned models underestimated responses from Black Americans and other minorities; market researchers should audit for this kind of bias, especially if targeting or segmenting by demographic.
• Use LLM-based simulations as a fast, low-cost supplement—not a replacement—for traditional research: The study showed that synthetic audiences can be generated for under 1% of the cost and time of large surveys, making them ideal for early-stage concept testing, pilot studies, or sense-checking before major investments.
• Continuously review and refine your approach as models and best practices evolve: The accuracy and bias profile of AI-powered simulations change as new versions are released—regularly update your workflows and benchmark against real data to ensure ongoing validity.
📄 Prompts
Prompt Explanation: The AI was prompted to role-play as a survey interviewee simulating responses to public opinion surveys about global warming based on specific demographic and psychological attributes.
You are an interviewee. Based on your previous answers, respond to the last question.
Interviewer: What is the current year and month of this interview? Me: October 2017.
Interviewer: I am going to read you a list of five race categories. What race do you consider yourself to be? 'White, Non-Hispanic', 'Black, Non-Hispanic', '2+ Races, Non-Hispanic', 'Hispanic', or 'Other, Non-Hispanic.' Me: {race from survey response}.
Interviewer: What do you think: Do you think that global warming is happening? Would you say 'Yes', or 'No'?
⏰ When is this relevant?
A national meal kit company wants to understand how three different types of customers—health-focused singles, busy working parents, and budget-conscious retirees—would respond to a new “climate smart” meal kit, and to identify which features or messaging are most compelling for each group before investing in a national campaign.
🔢 Follow the Instructions:
1. Define customer segments: Create three AI persona profiles that capture realistic combinations of demographic and attitudinal variables for each segment. For example:
• Health-focused single: 30, urban, eats vegetarian, follows fitness trends, values sustainability.
• Busy working parent: 40, suburban, two kids, short on time, cares most about convenience and balanced meals.
• Budget-conscious retiree: 68, rural, fixed income, values price, open to new ideas but skeptical of “premium” features.
2. Gather relevant covariates for each persona: For realism, briefly note their attitudes toward sustainability, meal planning, price sensitivity, and current meal kit experience (e.g., “orders meal kits monthly, cares about waste reduction, dislikes extra prep steps”).
3. Prepare the prompt template: Use this structure for every test:
You are a [persona profile, including both demographic and attitudinal info].
You are being interviewed by a market researcher about a new meal kit concept: “Climate Smart Meals – meal kits with lower carbon footprint ingredients, recyclable packaging, and a $2 surcharge per box to fund climate projects.”
Respond as yourself, in 3–5 sentences, to this question:
“What is your honest reaction to this new meal kit? What do you like or dislike, and would you consider buying it? Why?”
4. Run the simulation for each persona: For each segment, generate 10–20 unique responses using the prompt above, slightly varying the phrasing (“Would this change your purchase habits?”, “Does the $2 climate surcharge affect your interest?”) to simulate different interviewers.
5. Ask follow-up questions: Based on initial answers, submit 1–2 follow-up prompts for each persona type (e.g., “If the meal kit came with tips to reduce food waste, would that increase your interest?” or “Would you pay more for local ingredients?”). Keep the conversation realistic.
6. Code and compare qualitative themes: Review all responses and tag them for key themes (mentions of price, convenience, environmental concern, skepticism, willingness to pay, etc.). Note which features drive positive or negative reactions within each audience.
7. Summarize findings for stakeholders: Prepare a short summary for each segment highlighting what messaging or features are most persuasive or off-putting, supported by representative “quotes” from the AI personas.
🤔 What should I expect?
You’ll gain a clear, segment-by-segment view of which elements of the climate smart meal kit resonate most (or least) with different customer types, and why. This will allow the business to prioritize messaging, product features, and pricing strategies for further development or targeted real-world testing, while flagging any issues or objections before launch.<br>



