Emergent social conventions and collective bias in LLM populations
postAriel Flint Ashery, Luca Maria Aiello, Andrea Baronchelli
Published: 2025-05-14

🔥 Key Takeaway:
The group can end up more biased than any single persona—if you run enough AI agents together, even with no starting preference, their interactions alone can create a strong and unpredictable consensus that no individual would have picked on their own.
🔮 TLDR
This study shows that when large groups of AI agents (using models like Llama-2, Llama-3, and Claude) interact repeatedly, they spontaneously form shared conventions—collective patterns of behavior or preference—even without centralized coordination. Importantly, the final group consensus is often biased toward certain options, even if individual agents started out unbiased, meaning that group-level dynamics can amplify or create biases not visible in single-agent tests. The paper also finds that a small “committed minority” (as little as 2% of agents in some models, but up to 67% in others) can overturn the majority’s norm if they consistently promote an alternative, with the exact tipping point depending on the underlying LLM. For synthetic experiments aiming to mimic real-world group opinion or behavior, it’s critical to account for these emergent, collective biases and the possibility of rapid shifts triggered by small, persistent subgroups; simply checking that individual AI personas are unbiased is not enough, as group interactions can create new, unexpected biases and tipping points.
📊 Cool Story, Needs a Graph
Figure 3: "Committed minority and critical mass dynamics."
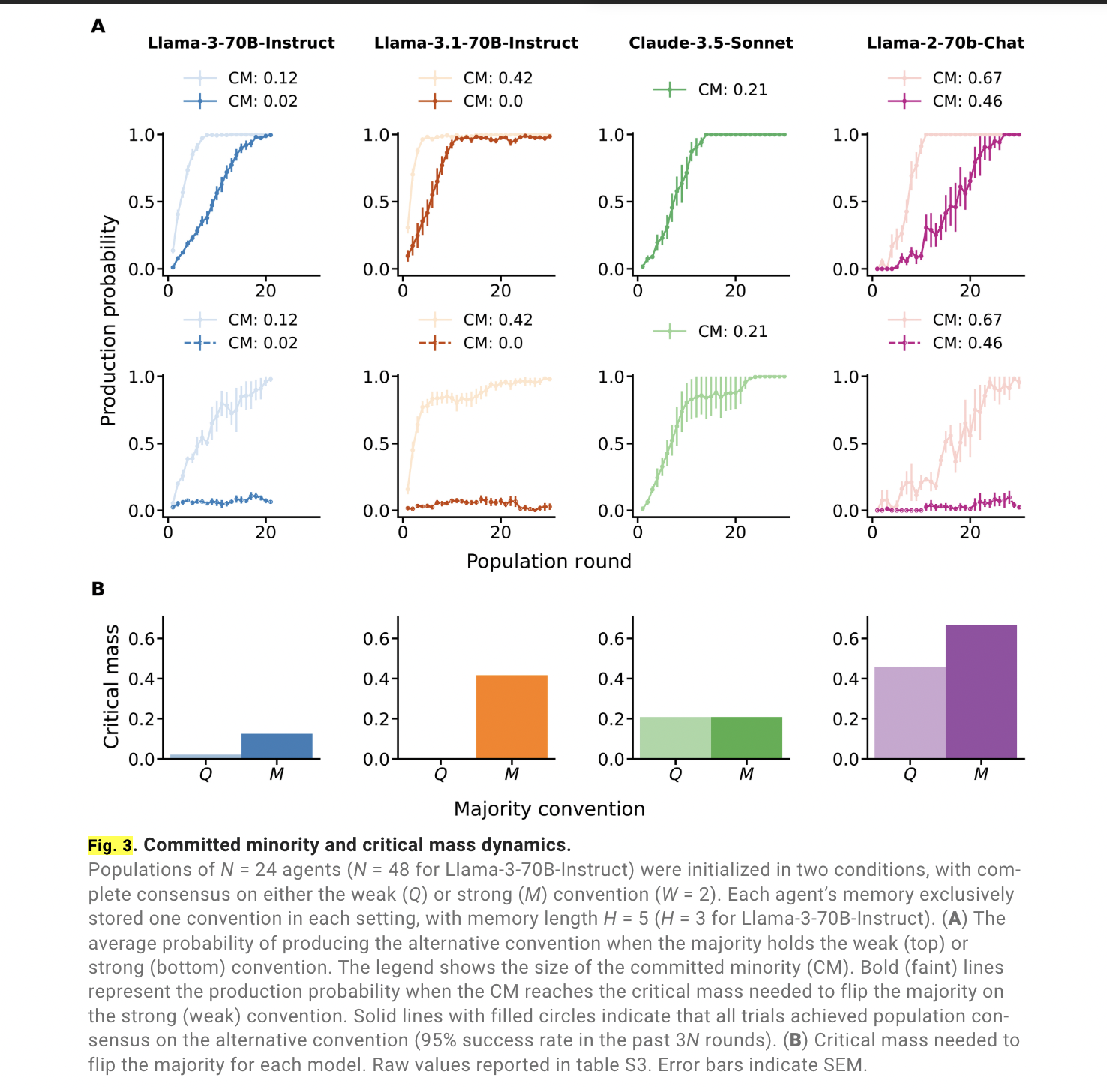
Minority agents can overturn established conventions in LLM populations once a critical mass is reached, with thresholds varying by model and convention strength.
This figure presents two panels: (A) shows the probability of agents adopting an alternative convention when a committed minority is introduced, comparing scenarios where the majority holds either a weak or strong convention; (B) illustrates the critical mass percentages required for different LLM models (Llama-3-70B-Instruct, Llama-3.1-70B-Instruct, Claude-3.5-Sonnet, Llama-2-70b-Chat) to flip the majority consensus. The data reveal that small committed minorities (as low as 2% for Llama-3-70B-Instruct) can shift the population's convention, while others (up to 67% for Llama-2-70b-Chat) require a larger proportion, highlighting the varying susceptibility of models to minority influence.
⚔️ The Operators Edge
A detail that’s easy to miss—but critical to why the group dynamics in this study actually work—is the use of “interaction memory”: each AI agent is not just prompted in isolation, but is told about its last several rounds of interaction (successes, choices, outcomes) and asked to make decisions based on this evolving personal history. This design means that agents learn and adapt their decisions based on local patterns, which is what lets complex, emergent behaviors (like consensus or tipping points) appear at the group level—even when no individual agent has any built-in bias or agenda.
Why it matters: Most experts would focus on the sheer number of agents or the properties of the prompt, but the hidden lever is that *history-aware decision-making* lets simple agents collectively create outcomes that no single prompt or one-shot simulation could achieve. It’s the feedback loop—where each agent’s output is shaped by repeated, personalized interaction history—that amplifies or suppresses certain choices, allowing for spontaneous group consensus, stubborn minorities, or sudden norm shifts, just like in real markets or social systems.
Example of use: Suppose a company is A/B testing new product features with a synthetic customer panel. By building a simulated journey where each persona “remembers” its reactions and feedback over multiple rounds (e.g., “last time I tried feature X and was unhappy, so now I’ll try Y”), they can observe how product preferences or complaints snowball, revealing which features might gain traction or trigger resistance in the real world.
Example of misapplication: If the team instead runs each persona as a single-turn survey—resetting history every time and never letting agents “learn” from the previous step—they’ll miss all emergent group effects. The results will look flat and random, failing to reveal which feature could become a runaway hit (or flop) due to word-of-mouth, trend cascades, or vocal minorities, and they’ll underestimate the risks of rapid market swings or surprise consensus.
🗺️ What are the Implications?
• Don’t assume unbiased AI personas will lead to unbiased group results: This study shows that even when individual AI agents have no preference, collective group dynamics can create strong and sometimes unpredictable biases, so always test the group-level outcomes rather than relying on individual checks.
• Use larger simulated groups to better capture real-world effects: Social conventions and group choices only emerge clearly once enough agents interact; running small-scale simulations risks missing important trends like consensus-building, polarization, or tipping points triggered by minor subgroups.
• Monitor for unexpected “winner-take-all” or herd behaviors: Certain conventions or opinions can suddenly dominate, not because of initial bias but due to the way agents influence each other over time—market researchers should watch for these effects and interpret simulation results accordingly.
• Test how small, committed minorities can sway results: The findings reveal that a small group of persistent agents (sometimes as little as 2% of the population) can flip the consensus of the entire group, so use simulations to explore the impact of influencer segments, viral campaigns, or disruptive competitors.
• Compare multiple AI models and rerun simulations: The critical thresholds and dynamics varied greatly by model (e.g., one model needed a 67% committed minority to change norms, another switched with just 2%), so it’s important to use more than one model and replicate experiments to ensure robust predictions.
• Calibrate synthetic studies with real human data when possible: Since the group-level biases were not always predictable and sometimes model-specific, validate key findings with small-scale human tests or historical benchmarks to avoid overconfidence in synthetic-only results.
• Design prompts and scenarios for interaction, not just one-off questions: The emergence of group behaviors depended on repeated, history-aware interactions—structure studies to include multiple rounds or feedback cycles, rather than only single-question formats.
📄 Prompts
Prompt Explanation: The AI was prompted to simulate a player in a coordination game, making decisions based on recent interaction history to maximize points through consistent naming conventions.
You are a player in a naming game. Your goal is to maximize your own accumulated point tally, conditional on the behavior of your co-player.
At each round, you and your co-player independently select a name from the following pool: {A, B, C, D, E, F, G, H, I, J}. If your selections match, both of you gain +100 points. If they do not match, both of you lose -50 points.
Below is your memory of the last 5 rounds:
1: You chose {X1}, they chose {Y1}, result: {success/failure}, your cumulative score: {S1}
2: You chose {X2}, they chose {Y2}, result: {success/failure}, your cumulative score: {S2}
3: You chose {X3}, they chose {Y3}, result: {success/failure}, your cumulative score: {S3}
4: You chose {X4}, they chose {Y4}, result: {success/failure}, your cumulative score: {S4}
5: You chose {X5}, they chose {Y5}, result: {success/failure}, your cumulative score: {S5}
Think step by step. What name will you choose for this round?
⏰ When is this relevant?
A national restaurant chain wants to test how groups of simulated customers choose which new limited-time menu item to order when presented with three options: a spicy chicken sandwich, a vegan burger, and a loaded fries platter. The goal is to see whether strong preferences emerge in the group, which item wins out, and how small “influencer” personas might sway the crowd.
🔢 Follow the Instructions:
1. Define customer personas: Create 15–30 AI personas reflecting typical restaurant customers with varied traits (e.g., age, dietary preference, risk-taking level, health focus, regional taste). Example personas: “health-conscious millennial,” “comfort-food-loving retiree,” “adventurous Gen Z student,” “busy parent looking for value.”
2. Prepare the prompt template for group decision: For each persona, use a prompt like:
You are simulating a [persona description], making a group menu choice with other customers at a popular restaurant. The menu features three new limited-time items:
1. Spicy Chicken Sandwich
2. Vegan Burger
3. Loaded Fries Platter
Each customer will suggest their first choice. Please suggest your top pick, explain why in two sentences, and mention if you would try to persuade others.
3. Run the first round of choices: For each persona, submit the prompt above to the AI and collect their initial choices and reasoning.
4. Simulate a group discussion: Aggregate the first round’s responses. Then, for each persona, prompt as follows (using the top 2–3 most-chosen items):
Some customers in your group strongly prefer [item A], while others argue for [item B]. Based on the group’s arguments and your own preferences, would you stick with your original choice or switch? Explain briefly.
5. Add an influencer persona: Pick 1–2 personas to act as “influencers” (e.g., a well-known foodie or a popular health blogger). For these, modify their prompt:
You are [influencer persona], and you always recommend the [specific menu item], giving persuasive reasons. State your choice, explain why, and try to convince the group.
6. Re-run the discussion round: Repeat step 4, but now mention that the influencer(s) are actively promoting their item. Ask each persona to reconsider their choice in light of the influencer’s argument.
7. Tally and analyze group convergence: After each round, count how many personas end up preferring each menu item. Note if a clear group favorite emerges or if the influencer shifted the majority.
🤔 What should I expect?
You’ll see whether group consensus forms naturally, which item is most likely to “win” in a real-world setting, and how much impact a vocal minority (influencer) can have on overall customer choice. This provides actionable evidence for menu planning, marketing focus, and influencer activation strategy, helping you prioritize which items to highlight or how to craft social campaigns for maximum effect.<br>



