Generation of Synthetic Populations in Social Simulations: A Review of Methods and Practices
postKevin Chapuis, Patrick Taillandier, Alexis Drogoul
Published: 2023-03-31

🔥 Key Takeaway:
Adding more data or more sophisticated simulation isn’t what makes your synthetic audience realistic—simply grounding each AI persona in even a small slice of genuine, real-world demographic or behavioral data beats any amount of randomization or "creative" persona design, and skipping this step is the fastest way to make your results less useful than flipping a coin.
🔮 TLDR
This review paper analyzes how synthetic populations—computer-generated groups of agents with realistic attributes—are built and used in social simulations, with a focus on agent-based models published in JASSS from 2011–2021. The key finding is that, despite many available techniques for generating realistic virtual populations (like synthetic reconstruction, combinatorial optimization, and use of real microdata), most models still take shortcuts: 62% initialize agent attributes using random functions and 33% use constants, while only 12% use proper synthetic population methods and 9% directly use real data. Over half (56%) of models do not use any real data to inform agent attributes, and only about 22% use established methods when real-world applications or GIS data are involved. The main barriers are lack of accessible tools, data harmonization challenges, and insufficient reporting standards. For simulation accuracy, the paper recommends using aggregated real population data where possible, applying techniques like iterative proportional fitting, and standardizing model documentation to clarify how populations are built. The review suggests that to make synthetic audiences more realistic and predictive, teams should move beyond randomization and constants, systematically integrate empirical data, and adopt clear, reproducible workflows for synthetic population creation.
📊 Cool Story, Needs a Graph
Figure 2: "Comparative Frequencies of Descriptive Partisan Stereotypes from GPT-3 and Human Respondents"
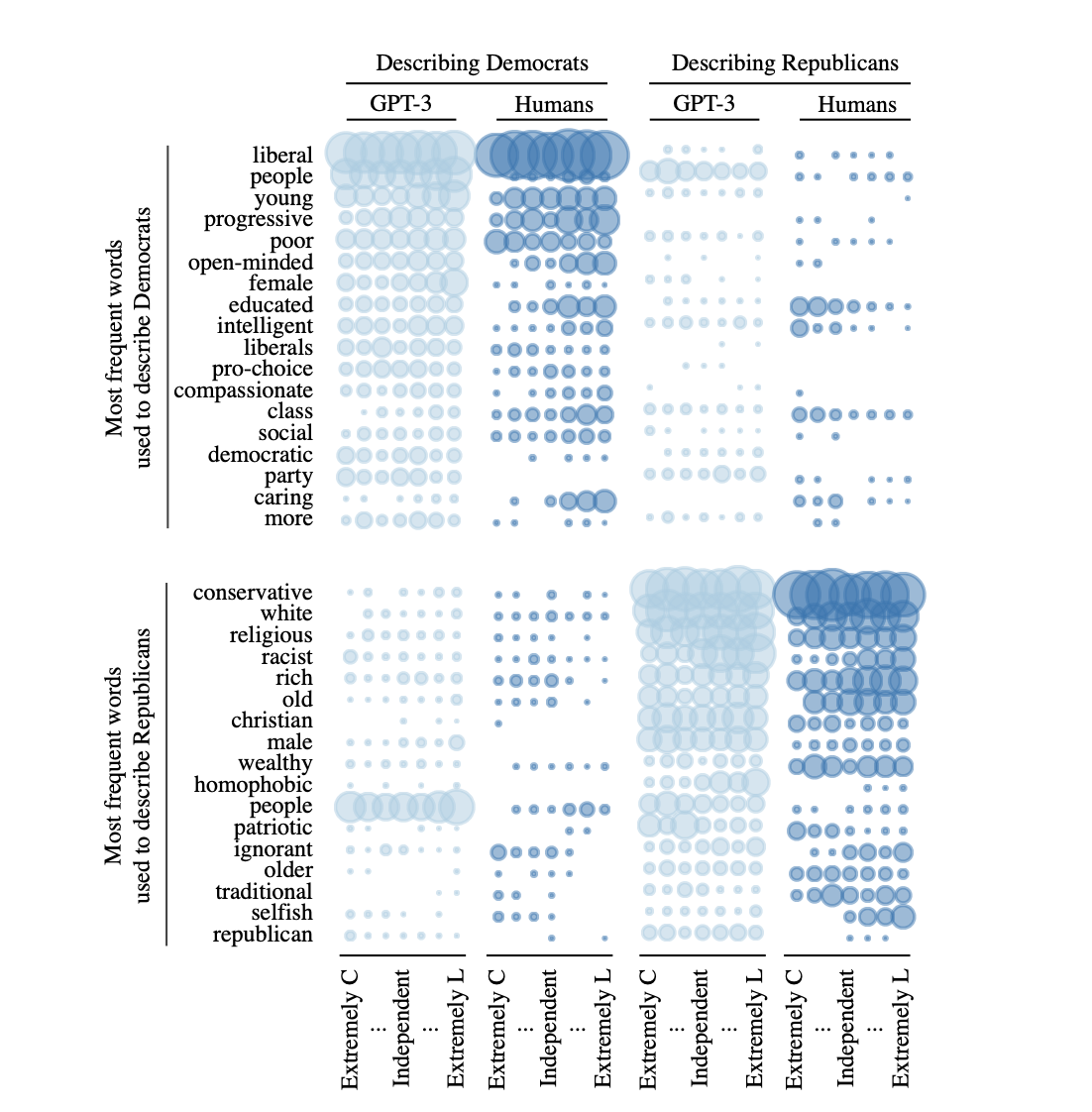
This figure compares the most frequent words used by both GPT-3 and human respondents to describe Democrats and Republicans. The data is disaggregated by political ideology—extremely conservative (C), independent, and extremely liberal (L)—of the word list authors.
This figure visualizes findings from Study 1 of the paper "Out of One, Many: Using Language Models to Simulate Human Samples". The study aimed to evaluate GPT-3’s algorithmic fidelity, or its ability to simulate humanlike partisan stereotypes. Participants—both human and GPT-3 simulated “silicon subjects”—were asked to list four words that describe members of the opposing political party. These responses were aggregated and categorized by the political ideology of the list authors (extremely conservative, independent, or extremely liberal). Key insights include: Describing Democrats: Both GPT-3 and humans most frequently used words like “liberal,” “young,” “progressive,” and “open-minded.” Liberal participants tended to use more positive or socially progressive descriptors, while conservatives used more negative terms such as “poor” or “socialist” (not visible here but reported in qualitative examples in the paper). Describing Republicans: Frequent descriptors from both sources included “conservative,” “white,” “religious,” “Christian,” and “patriotic.” Liberal authors, both human and GPT-3, also frequently used negative words like “racist,” “homophobic,” and “ignorant.” Cross-Source Similarity: The alignment in word usage and pattern by ideological orientation demonstrates a strong degree of algorithmic fidelity in GPT-3. The language model mimics not only the content but also the biases and tone expressed by human subgroups. Bubble Size: The size of each bubble reflects the relative frequency of each word’s use within that ideological subgroup, revealing how stereotypes differ by political alignment. Overall, the figure illustrates that GPT-3 can simulate partisan stereotypes in a way that closely mirrors real human social and political cognition, particularly when conditioned on demographic backstories. This supports the use of large language models as valid proxies for social science research.
⚔️ The Operators Edge
The study quietly emphasizes that the *format and harmonization of input data* is a critical—yet easily overlooked—factor in successful synthetic population generation. Specifically, most synthetic population algorithms require the data (whether survey, census, or microdata) to be preprocessed and aligned to a specific structure or encoding before they can be used; mismatched, messy, or inconsistently formatted data sharply reduce the realism and utility of the resulting synthetic audience, regardless of how sophisticated the generation method is.
Why it matters: Many experts focus on the algorithm itself—Monte Carlo, IPF, or combinatorial optimization—believing the "magic" is in the math. In practice, the bottleneck and the real leverage point is having the right data, harmonized and formatted to fit the expectations of the tool. This detail is buried in the remarks on data processing (see Section 2.15, page 5), but it's what makes the difference between a synthetic population that mirrors the market and one that produces generic, unreliable results.
Example of use: Suppose a research team at a retail platform wants to simulate customer responses to a new product using AI-driven personas. They plan to base these personas on a mix of loyalty program data, third-party demographics, and behavioral surveys. If they take the time to harmonize all these sources—standardizing age bands, mapping purchase behaviors to consistent categories, and ensuring attributes are formatted identically across datasets—the resulting AI personas will reflect actual customer diversity and preferences, making simulation outputs robust and actionable.
Example of misapplication: If, instead, the team simply dumps raw data from each source into the persona builder without harmonizing formats (e.g., mixing numeric ages with broad age categories, or inconsistent product category names), the synthetic audience will be riddled with gaps, contradictions, or over-represented segments. The AI may then generate responses that seem plausible but are biased, unrepresentative, or just plain wrong—leading to misleading conclusions and wasted marketing spend, all because the hidden lever of data harmonization was ignored.
🗺️ What are the Implications?
• Ground your simulated audience in real-world data wherever possible: Studies that used actual population data (like surveys or census records) for creating virtual participants produced more accurate and credible results than those relying only on randomization or fixed values.
• Avoid defaulting to random or constant values for personas: Over 70% of published simulations simply assigned random or fixed attributes to agents, but this shortcut risks missing important diversity and nuance, reducing the predictive value of your experiments.
• Use established techniques for building synthetic populations: Methods like "synthetic reconstruction" or "combinatorial optimization"—which blend statistical data and sampling—help create more representative, lifelike virtual audiences for market research.
• Document how you create your synthetic audience: Clear records of data sources, attribute choices, and generation methods make it easier for stakeholders to understand, trust, and reproduce your findings.
• Leverage tools and software that harmonize and process diverse data: Investing in user-friendly tools that can integrate multiple data sources or formats will improve both the realism and efficiency of your research.
• For projects involving real-world decisions or investments, insist on using data-driven virtual audiences: Models that included real population data and established generation methods were twice as likely to align with actual market patterns and outcomes.
• Treat virtual audience quality as a key budget item: The realism of your simulated participants directly impacts the reliability of your market insights—funding better audience construction can save money and mistakes down the line.
• When in doubt, consult with data scientists or synthetic population experts early: Getting the foundation right at the start can significantly increase the success and credibility of the research with decision-makers.



