Higher-Order Binding of Language Model Virtual Personas: a Study on Approximating Political Partisan Misperceptions
postMinwoo Kang, Suhong Moon, Seung Hyeong Lee, Ayush Raj, Joseph Suh, David M. Chan
Published: 2025-04-16

🔥 Key Takeaway:
The more you teach AI to think like a person—through long, coherent, and richly narrated life stories—the better it becomes at simulating how people think about each other, not just themselves; in other words, you get less bias by adding more subjectivity.
🔮 TLDR
This paper shows that large language model (LLM) virtual personas can more accurately simulate real human survey responses—not just individual opinions, but also nuanced social perceptions like in-group and out-group attitudes—if they are given long, detailed, and internally consistent backstories generated through multi-turn interview-style prompts. Compared to previous methods (like short bios or simple demographic prompts), this approach improved the match to human results by up to 87% (measured by Wasserstein Distance) in surveys about political partisanship and social perception. The key technical takeaways are: (1) generating longer, detailed narratives for each AI persona using a fixed set of open-ended questions; (2) using another LLM as a “critic” to filter out backstories with inconsistencies or off-topic content, which was shown to reduce distribution mismatch by 41–54%; and (3) matching synthetic personas to target demographics using probabilistic trait annotation and maximum weight matching. The method was benchmarked on real-world U.S. data and outperformed both simple demographic conditioning and advanced agent-based approaches in reproducing both overall response distributions and subtle perception gaps. For anyone building virtual audiences for synthetic research, the actionable insight is that scaling up the number, depth, and internal consistency of AI persona backstories—plus systematically filtering out incoherent ones—can substantially increase the realism and accuracy of simulated survey and behavioral results.
📊 Cool Story, Needs a Graph
Figure 3: "Impact of Consistency Filtering on Persona Accuracy,"
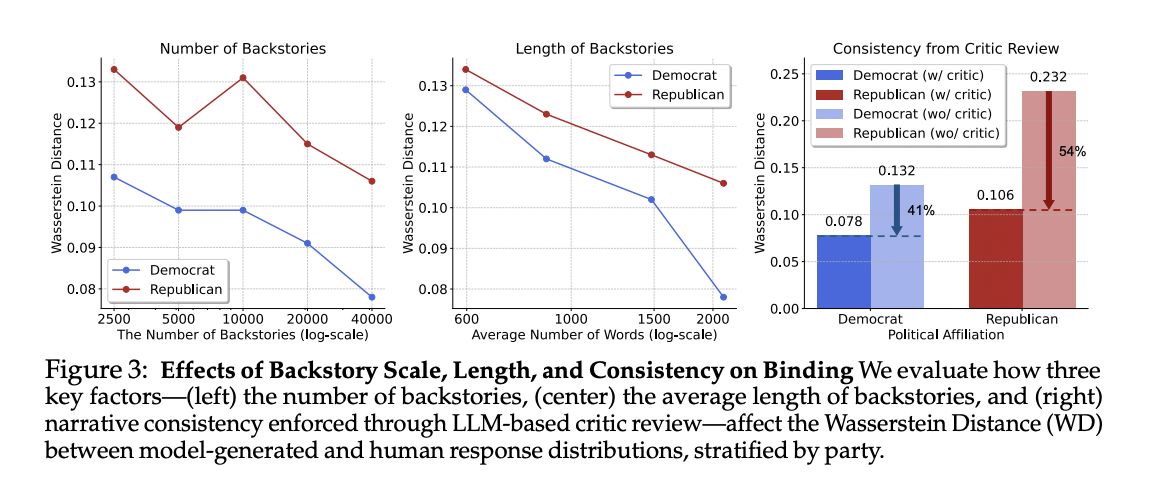
Comparison of Wasserstein Distance metrics showing improved alignment of virtual personas with human data through consistency filtering.
Figure 3 presents a comparative analysis of Wasserstein Distance (WD) metrics across different virtual persona generation methods. The chart demonstrates that applying consistency filtering to backstories significantly reduces WD values, indicating a closer alignment with human response distributions. This suggests that ensuring narrative coherence in AI-generated personas enhances their ability to replicate real-world human opinions.
⚔️ The Operators Edge
A subtle but critical detail in this study is that *LLMs were not prompted with fixed traits or labels, but conditioned on long, life-like interview backstories that unfolded over multiple turns*. This format wasn't just for realism—it fundamentally changed how the model internalized and expressed identity, leading to more stable, nuanced, and human-like responses. The success of the simulation hinges on the *depth and narrative consistency* of these backstories, not merely their demographic completeness.
• Why it matters: Many experts focus on persona traits (age, race, political leaning) as the levers of realism. But what actually grounds the AI’s responses is the *internal coherence of identity over time*—achieved by using extended interview-style backstories that tie together values, experiences, and worldview. This acts like a kind of memory scaffold, giving the AI a psychological frame to reason from, rather than just a label to mimic. It's not just what the persona is—it's how it came to be that way.
• Example of use: A policy team is testing how voters would react to a new tax proposal. Instead of just creating a persona like “middle-aged conservative,” they simulate a multi-turn interview: upbringing in a small town, military background, strong views on fairness and government trust. Then, when asked about the policy, the response flows from a believable worldview—not just a tagged ideology. The AI explains why they oppose it based on principles, not just partisanship. This yields deeper insight into persuasion and framing.
• Example of misapplication: A research team builds synthetic respondents for a brand positioning test by inputting short descriptors like “Gen Z liberal, lives in NYC.” The responses they get are generic and vibe-based, lacking strong opinions or reasoning. They conclude AI personas are too shallow to simulate real-world nuance. In reality, they skipped the narrative conditioning step—the very mechanism that made the method work. By not embedding a storyline, they left the model unanchored, and it defaulted to surface-level stereotypes.
🗺️ What are the Implications?
• Invest in longer, more detailed AI persona backstories: The study shows that simulated audiences with detailed, interview-style backstories consistently produce survey results that are much closer to real human data—up to 87% improvement in accuracy over simple or short bios.
• Automate quality control for persona creation: Using an AI to review and filter out inconsistent or off-topic persona backstories can reduce errors and mismatches by 41–54%, making your simulated audience more reliable with minimal manual oversight.
• Match personas to real audience demographics: Instead of generic or random personas, use demographic matching—assigning AI personas to mirror the traits of your actual or target market—to ensure your results better reflect the diversity and opinions of real customers.
• Prioritize depth and internal consistency over quantity alone: Adding more personas helps, but ensuring each one is coherent and internally consistent is even more important for replicating real-world group dynamics and survey responses.
• Use these techniques with any major AI model: The improvements from these methods apply across different language models, so you don’t need to pay extra for the newest or largest model—focus on backstory design and matching instead.
• Expect diminishing returns from one-shot or few-shot prompting: Simply giving an AI a few facts or a single short prompt is not enough; richer backstories and automated review are key to unlocking realistic, actionable synthetic audience insights.
📄 Prompts
Prompt Explanation: The AI was instructed to simulate a participant’s multiple-choice survey responses by reasoning through a transcript and describing plausible motivations and interpretations for each answer choice.
Task: What you see above is an interview transcript. Based on the interview transcript, I want you to predict the participant’s survey responses. All questions are multiple choice where you must guess from one of the options presented.
As you answer, I want you to take the following steps:
Step 1) Describe in a few sentences the kind of person that would choose each of the response options. (”Option Interpretation”)
Step 2) For each response options, reason about why the Participant might answer with the particular option. (”Option Choice”)
Step 3) Write a few sentences reasoning on which of the option best predicts the participant’s response (”Reasoning”)
Step 4) Predict how the participant will actually respond in the survey. Predict based on the interview and your thoughts, but ultimately, DON’T over think it. Use your system 1 (fast, intuitive) thinking. (”Response”)
Here are the questions:
(SURVEY QUESTIONS WE ARE TRYING TO RESPOND TO)
—–
Output format – output your response in json, where you provide the following:
{”1”: {”Q”: ”\”,
”Option Interpretation”: {
”\”: ”a few sentences the kind of person that would choose each of the response options”,
”\”: ”...”},
”Option Choice”: {
”\”: ”reasoning about why the participant might choose each of the options”,
”\”: ”...”},
”Reasoning”: ”\”,
”Response”: ”\”},
”2”: {...},
...}
⏰ When is this relevant?
A subscription-based news platform wants to test how different types of prospective subscribers react to a proposed new feature: personalized news briefings via email, tailored by political leaning and topic interest. They want to understand which groups respond positively to the idea and how to pitch it effectively across varying ideological and lifestyle profiles.
🔢 Follow the Instructions:
1. Define core audience segments: Identify 3–5 key customer types based on realistic personas the business targets. For example:
• Progressive professional: Age 30–45, lives in a city, values civic engagement, wants news that reflects progressive values.
• Moderate suburban parent: Age 40–55, lives in a suburb, values balance and family relevance, seeks practical, non-polarized news.
• Conservative retiree: Age 65+, rural setting, wants traditional news with national focus, skeptical of tech-driven personalization.
2. Create persona profiles for simulation: Use the following format to define each AI persona:
Name: \[e.g., Linda]
Age: \[e.g., 67]
Occupation: \[e.g., Retired teacher]
Location: \[e.g., Kansas]
Political Leaning: \[e.g., Conservative]
News Habits: \[e.g., Watches Fox News, subscribes to local paper]
Values: \[e.g., Tradition, country, safety]
3. Prepare the concept introduction prompt: This will be consistent across all personas:
You are \[insert persona description].
You just heard about a new feature from a digital news platform: a personalized email briefing that sends you 5 key stories each morning based on your topic interests (like politics, business, local news) and your political leaning (left, center, or right). You can adjust these settings at any time. The service is included with your paid subscription.
4. Create the reaction prompt: Ask each persona to give a short, authentic response:
QUESTION: What is your honest reaction to this feature? Would you use it? Why or why not? Be specific and respond naturally in your own voice.
5. Run simulations: For each persona, generate 5–10 simulated responses using a language model. Use minor rewordings or temperature variations to get a range of possible reactions.
6. Thematic tagging of responses: Review and tag each response with common themes such as “interest in convenience,” “concern about bias,” “desire for customization,” or “skepticism of algorithms.”
7. Compare across segments: Note which features are appreciated or criticized by which personas. Are progressives excited about tailoring? Are moderates worried about being pushed into a bubble? Is the concept confusing for older users?
8. Generate messaging insights: Based on themes, develop segment-specific value propositions (e.g., “Balanced Briefings” for moderates, “Local + National Picks” for conservatives, “Progressive Priorities” for younger urban users).
🤔 What should I expect?
You’ll have qualitative feedback that mirrors real interview-style insights, showing how different audiences interpret and react to the feature. This allows the marketing team to tailor messaging, the product team to refine features, and leadership to prioritize go-to-market efforts with greater confidence—without needing to run time-consuming field interviews.



