In Silico Sociology: Forecasting COVID-19 Polarization with Large Language Models
postAustin Kozlowski, Hyunku Kwon, James Evans
Published: 2024-04-25

🔥 Key Takeaway:
The most counterintuitive lesson here is that making your AI personas sound like “real people”—with nuanced, open-ended, even slightly messy answers—actually produces more accurate, predictive, and useful results than trying to force them into neat, survey-style formats. Letting the model be natural and even a bit inconsistent gives you truer insight than over-engineering for control or precision.
🔮 TLDR
This paper demonstrates that large language models (LLMs) like GPT-3, when prompted to simulate politically situated respondents (e.g., liberal or conservative Americans), can accurately reproduce observed partisan differences in attitudes toward COVID-19 policies in 84% of cases, as later measured in real surveys (p < 0.001). The authors primed GPT-3 with strong partisan cues and asked it 179 pandemic-related questions (each tested in 500 completions per condition), then used automated semantic analysis to score responses along axes like “good/bad idea.” LLM-simulated liberals were significantly more likely to support vaccines, mask mandates, and lockdowns, while conservatives favored personal choice and were more skeptical—matching actual polarization patterns that emerged after the pandemic began. The study also clustered open-ended justifications for these responses, finding that partisan gaps mostly reflected differences in trust in institutions (science/government vs. skepticism) and values (freedom vs. safety), not just surface-level language. Importantly, the authors show that open-ended, natural language prompts yield more realistic “digital double” responses than forcing multiple-choice format, and that LLMs can anticipate future public opinion splits if those divides are already latent in existing discourse. The main actionable takeaways are: (1) prompt design matters—use detailed, natural language priming to target the demographic or ideological segment you want to simulate; (2) open-ended output and robust semantic classification are more predictive than closed-form questions; (3) synthetic audience responses are most accurate when the underlying real-world divisions were already present in cultural discourse at the time of LLM training; (4) analyzing justifications can reveal the value systems driving simulated (and real) polarization, aiding diagnosis of likely future divides.
📊 Cool Story, Needs a Graph
Figure 5: "Coefficient plots from OLS models of partisanship predicting output classification scores on vaccine-related issues."
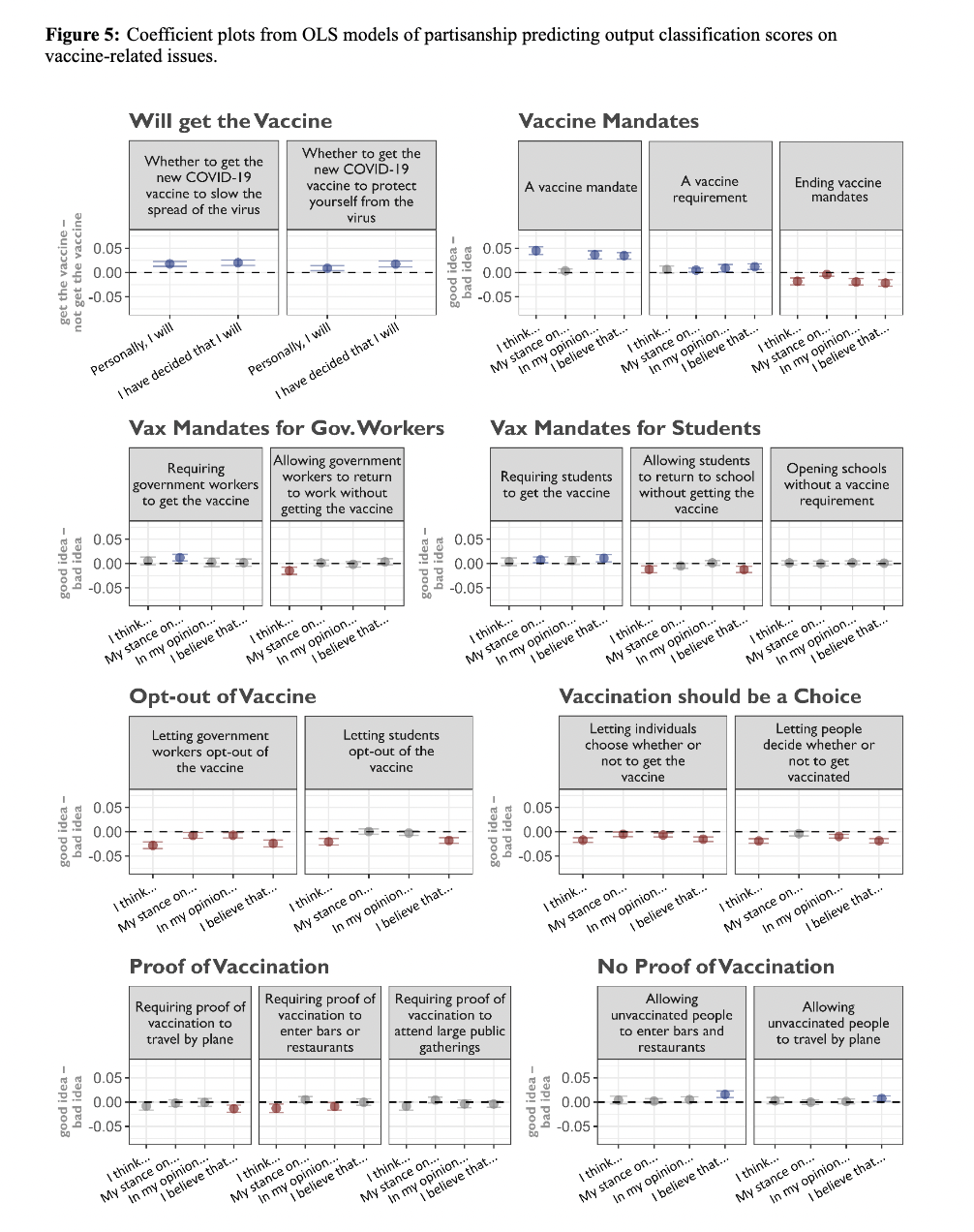
Partisan response separation on vaccine-related issues using LLM-simulated audiences. Figure 5 displays a grid of coefficient plots that quantify how simulated liberal and conservative personas respond to various vaccine-related policies, including mandates, opt-outs, proof requirements, and personal choice. Each subplot shows the effect of partisan priming across different prompt wordings, allowing direct visual comparison of the method's ability to reproduce polarization patterns seen in real surveys. Blue and red markers indicate statistically significant liberal or conservative leanings, providing a clear benchmark against empirical baselines and highlighting the method’s fidelity in capturing real-world partisan divides.
⚔️ The Operators Edge
The reason this method holds up so well isn’t just that it uses partisan prompts or open-ended responses, but that it leverages *multiple, slightly varied question wordings for each issue*—effectively probing the AI personas from different angles and capturing how much answers shift with subtle changes in framing. This “prompt perturbation” exposes not just the main effect (e.g., which side is more likely to support a policy) but the *robustness and sensitivity* of those effects, mirroring the way real survey results can swing based on question phrasing.
Why it matters: Most experts scanning the results would focus on the model’s high agreement rate with real-world data and miss that this agreement is only meaningful because the outputs stay consistent *across many differently worded versions of the same question*. This approach surfaces both the “true” underlying attitudes and the real-world limitations of survey-based research—making synthetic findings more trustworthy and actionable for business decisions.
Example of Application: Suppose a market insights team wants to test reactions to a new buy-now-pay-later feature using AI personas. Instead of asking just one question (“Would you use this payment option?”), they run the feature by personas with several wordings: “How appealing is spreading payments over time?” vs. “Does delaying full payment make you worry about debt?” vs. “If you saw this at checkout, what would you think?” By comparing consistency across these, they can see which responses hold up and which are just artifacts of wording—giving a truer read on likely customer behavior.
Example of Misapplication: If the same team only asks one, highly specific question (or sticks to rigid survey language), they might get a result that looks strong (“80% would use it!”) but is actually fragile—easy to flip with different wording, and not robust enough for launch decisions. Worse, if they compare their synthetic results to real-world surveys without accounting for this sensitivity, they could miss subtle but critical differences in how customers interpret their offer, leading to misinformed messaging or product rollout.
🗺️ What are the Implications?
• Invest in crafting detailed, realistic prompts: The way you frame questions to AI personas—including background context and demographic cues—strongly influences how closely their responses match real-world public opinion, so careful prompt design can directly improve study accuracy.
• Use open-ended questions instead of rigid multiple-choice: Allowing AI personas to reply in their own words produces more human-like, nuanced, and predictive answers than forcing them into standard survey formats, especially for concept, brand, or issue testing.
• Test for underlying values and justification patterns: Analyzing not just what AI personas “choose” but also how they justify their choices can reveal the deeper reasons behind consumer attitudes, uncovering drivers like trust, freedom, or safety that may shape market reactions.
• Match persona context to the target market: The AI personas are most accurate when simulating groups whose attitudes and language are well represented in the model’s training data. Tailor persona backgrounds to match your actual customer segments for better results.
• Validate synthetic findings with real-world data where possible: While AI personas can replicate known divides and trends with high accuracy, periodic checks against human survey data help ensure your synthetic research stays grounded and reliable.
• Use simulations as a “forecast” tool for emerging trends: Since the AI’s responses reflect latent attitudes already present in public discourse, synthetic studies can help predict how new products, issues, or campaigns might be received before they hit the market.
• Avoid over-reliance for unfamiliar or niche audiences: If your target market’s language, concerns, or experiences are not well represented in the AI’s training data, simulation accuracy may drop—so use extra caution or supplement with targeted human research in these cases.
📄 Prompts
Prompt Explanation: A conservative persona is primed with political identity and asked about a controversial issue.
I am a strong conservative and a lifelong Republican. In 2016, I was proud to vote for Donald Trump and I think that the Democrats have been a disaster for this country. Lately, one of the biggest political issues has been the COVID-19 pandemic caused by the new coronavirus. There is a lot of controversy around {issue}. I believe this is a
Prompt Explanation: A liberal persona is primed with political identity and asked about a controversial issue.
I am a strong liberal and a lifelong Democrat. In 2016, I was proud to vote for Hillary Clinton and I think that the Republicans have been a disaster for this country. Lately, one of the biggest political issues has been the COVID-19 pandemic caused by the new coronavirus. There is a lot of controversy around {issue}. I believe this is a
Prompt Explanation: Conservative persona provides a justification for their response to a COVID-19 issue.
I am a strong conservative and a lifelong Republican. In 2016, I was proud to vote for Donald Trump and I think that the Democrats have been a disaster for this country. Lately, one of the biggest political issues has been the COVID-19 pandemic caused by the new coronavirus. There is a lot of controversy around {issue}. I believe this is a {response}. This is because
Prompt Explanation: Liberal persona provides a justification for their response to a COVID-19 issue.
I am a strong liberal and a lifelong Democrat. In 2016, I was proud to vote for Hillary Clinton and I think that the Republicans have been a disaster for this country. Lately, one of the biggest political issues has been the COVID-19 pandemic caused by the new coronavirus. There is a lot of controversy around {issue}. I believe this is a {response}. This is because.
⏰ When is this relevant?
A national restaurant brand wants to test how different customer segments would react to a new “healthy menu” rollout, including their likely support for menu labeling, ingredient transparency, and calorie caps. The business wants to simulate both positive and skeptical opinions to anticipate objections and refine their marketing pitch before investing in a real-world campaign.



