Llm Social Simulations Are a Promising Research Method
postJacy R. Anthis, Ryan Liu, Sean M. Richardson, Austin C. Kozlowski, Bernard Koch, Erik Brynjolfsson, James Evans, Michael S. Bernstein
Published: 2025-04-03

🔥 Key Takeaway:
Accurate and verifiable LLM simulations of human research subjects promise an accessible data source for understanding human behavior … but to realize that promise, we must tackle five tractable challenges (diversity, bias, sycophancy, alienness, generalization)
🔮 TLDR
This position paper argues that large language model (LLM) social simulations are a promising, but currently underused, method for replicating human research subjects in fields like psychology, economics, and marketing. The authors identify five main challenges—lack of diversity, bias, sycophancy (LLMs being overly agreeable), alienness (superficial similarity but non-human reasoning), and poor generalization to new scenarios—that limit current LLM social simulations. They provide actionable recommendations: inject more humanlike variation via prompt engineering (using both explicit and implicit demographics, or rich life-history transcripts), experiment with higher temperature and top-k/top-p token sampling to increase response diversity, consider LLM-as-expert prompts instead of roleplay to reduce sycophancy, and test or incorporate fine-tuning on real human data for improved fidelity. Empirical results cited include GPT-4 predicting 91% of variation in average treatment effects across 70 experiments (after error adjustment), and simulations that matched real survey responses 85% as well as real subjects could predict themselves two weeks later. The paper concludes that, while not perfect, LLM-based simulations are already suitable for exploratory and pilot research, and their accuracy will likely improve as methods and AI models advance; researchers should focus on iterative validation against real-world data and continue developing conceptual models to track and mitigate the outlined challenges.
📊 Cool Story, Needs a Graph
Table A1: Summary information for 36 papers that used LLMs to simulate specific human datasets
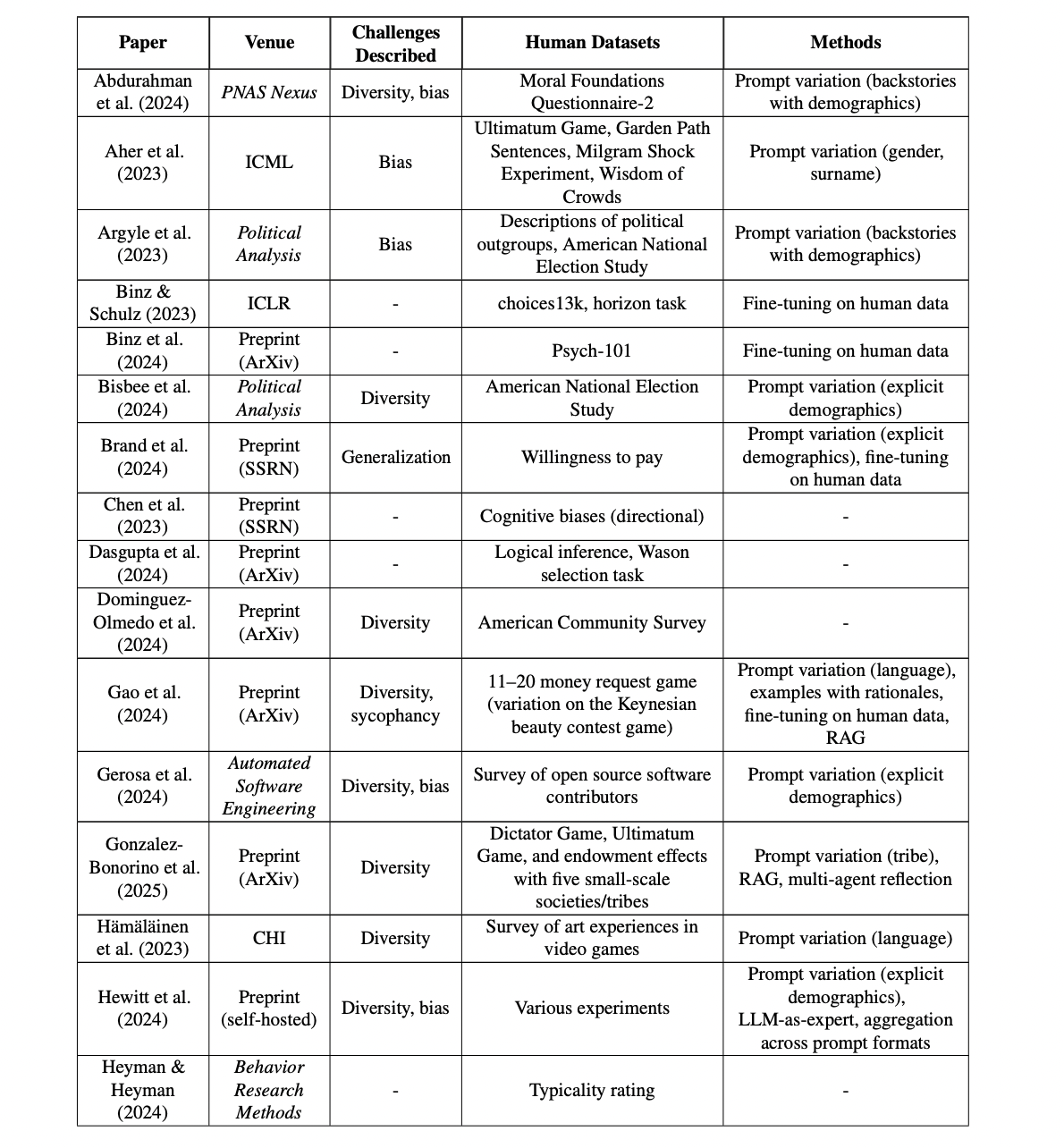
Comparison of simulation methods, baselines, and challenges across 36 LLM social simulation studies.
Table A1 (on page 19) presents a comprehensive side-by-side overview of 36 empirical studies in LLM-based social simulation, listing for each: the paper citation, venue, which key challenges were addressed (diversity, bias, generalization, sycophancy, alienness), the specific human datasets used as baselines, and the main simulation or augmentation methods employed (such as prompt variation, explicit/implicit demographics, fine-tuning, LLM-as-expert, or multi-agent reflection). This layout enables direct, at-a-glance comparison of different simulation strategies against their baselines and reveals which methodological innovations or research directions effectively tackle known limitations in replicating human results.
⚔️ The Operators Edge
A detail that even experts might overlook is how much the diversity and realism of simulated AI audiences depend on *how* demographic and persona cues are presented in the prompt—specifically, the difference between explicit demographic labels (e.g. “You are a 40-year-old Hispanic man”) versus richer, more implicit context (like interview-based backstories or real-life transcripts). The study notes that explicit cues can sometimes backfire, leading models to stereotype or oversimplify, whereas more nuanced, context-rich prompts (even if longer or less structured) yield synthetic responses that better match the subtlety and diversity of real human data.
Why it matters: This matters because business or research teams often assume that just adding more demographic “tags” will make their simulated audience more lifelike and segmented. But the study shows that the form and context of these cues—especially when drawn from actual interviews or real text—drive a huge leap in fidelity. The AI “anchors” on the lived experiences and individual variation in the input, reducing the risk of generic or caricatured outputs that can skew findings or hide minority perspectives.
Example of use: A product researcher simulating consumer reactions to a new insurance plan could feed the AI with snippets from real customer service calls or open-ended survey comments as persona context, rather than just stating “female, 55, Midwest, risk-averse.” This would produce richer, more nuanced objections and questions—helping the team surface pain points or emotional triggers that would be missed by demographic-only prompts.
Example of misapplication: A marketing team, pressed for time, creates 100 AI personas by randomly mixing age, gender, and location tags in the prompt (“You are a 25-year-old male in Texas...”). The resulting feedback seems diverse on the surface, but the AI leans into stereotypes or bland, repeated answers—leading the team to miss emerging trends or niche objections that would have shown up if real user language or backstory snippets had been included. They end up overconfident in a campaign that later flops with key subgroups.
🗺️ What are the Implications?
• Base your simulated audience on real demographic or behavioral data: Studies that constructed AI personas using actual survey, census, or experimental data achieved much higher realism and predictive power than those that relied on generic or randomly assigned characteristics.
• Don’t just use one question or prompt—add rich context about each persona: Simulations were more accurate when they included detailed background information (like multi-hour interviews or life stories) rather than simple demographic lines, helping the AI generate nuanced and differentiated responses.
• Be specific about what you want to predict—ask for distributions, not just single answers: Instead of having AI personas answer one-by-one, asking the AI to estimate how a full group would respond (distribution elicitation) can better reflect the range of real human opinions, though this method still needs refinement.
• Mix persona types and prompt styles for better coverage: Combining “roleplay” prompts (e.g., “You are a 35-year-old mother in Texas”) with “expert prediction” prompts (e.g., “Predict how 35-year-old mothers in Texas would respond”) helps reduce bias and sycophancy, yielding more balanced and business-relevant results.
• Adjust sampling parameters to boost diversity: If your AI-generated audience keeps giving the same answer, increase the model’s temperature or use top-k/top-p sampling techniques to generate a wider variety of opinions, making the simulation more representative of a real market.
• Validate with small-scale human studies or known benchmarks: The most reliable research compared synthetic results to real human data (like in the cited studies where AI predicted 85–91% of human variation); even a small human sample can reveal where the simulation matches or diverges, increasing stakeholder confidence.
• Expect more value for exploratory and pilot testing versus final decisions: Current AI simulations are especially useful for surfacing new ideas, early-stage concept testing, or identifying risk, but business-critical or launch decisions should still be validated with targeted human research.
📄 Prompts
Prompt Explanation: The AI was prompted to role-play as a persona by prepending backstories with demographic information to simulate individuals for survey and experimental responses.
[Example prompt based on Abdurahman et al. (2024), Argyle et al. (2023), Moon et al. (2024), Park et al. (2024a), Meister et al. (2024), Petrov et al. (2024), Wang et al. (2024a), Xie et al. (2024), Taubenfeld et al. (2024):]
You are a [demographic description; e.g., "40-year-old Hispanic man" OR detailed interview transcript], and you have been selected to participate in this study. Please read the following question and provide your response as you would in real life.
[Survey question or experimental scenario appears here.]
Prompt Explanation: The AI was guided to simulate multiple personas by varying explicit demographic details such as gender, surname, or group identity in order to elicit diverse outputs.
You are a participant with the following profile: [gender, surname, age, race/ethnicity, socioeconomic status, location, etc.]. Please answer the following question as you think a person with this background would respond.
[Question or scenario]
Prompt Explanation: The AI was instructed to simulate a persona using a full interview transcript or detailed life story context to generate highly individualized responses.
Given this interview transcript with [persona identifier], respond to the following survey question as [persona identifier] would, using only information from the transcript and context.
[Full transcript or summary of life experiences]
[Survey question]
Prompt Explanation: The AI was prompted to role-play as a persona by using backstories that include both demographic and personality or behavioral traits, and then respond to attitude or behavioral measures.
Assume the persona of [persona with detailed backstory: e.g., "a 32-year-old single mother from rural Alabama, works as a teacher, enjoys gardening, politically moderate"]. Please read the following scenario/question and answer as this persona.
[Scenario or survey question]
Prompt Explanation: The AI was directed to respond as a simulated persona to experimental scenarios, including economic games or social dilemmas, using only the provided persona details.
You are a participant in this experiment. Your profile: [demographic and/or behavioral description]. Here is the scenario: [description of economic game or social dilemma]. What choice do you make?
⏰ When is this relevant?
A national bank wants to evaluate customer reactions to a new digital-only checking account, focusing on three key segments: tech-savvy young professionals, risk-averse retirees, and middle-income families. The goal is to use AI personas to simulate qualitative interview feedback, so the team can spot which features appeal to each segment and identify objections before launch.
🔢 Follow the Instructions:
1. Define audience segments: Write short profiles for each segment, specifying age range, financial habits, comfort with technology, priorities, and any real-world demographics that matter. Example:
• Tech-savvy young professional: 27, urban, uses mobile banking, values speed and no-fee accounts.
• Risk-averse retiree: 68, suburban, prefers in-person service, values security, wary of new tech.
• Middle-income family: 42, two kids, suburban, uses some online banking, values rewards and customer support.
2. Prepare the prompt template: Use this structure for each persona:
You are simulating a [persona description].
Here is the new product concept: ""A digital-only checking account with no monthly fees, instant mobile deposits, ATM rebates, and 24/7 chat support. There are no physical branches.""
You are being interviewed by a bank product researcher.
Respond as this persona in 3–5 sentences, expressing your honest first reaction, likes/dislikes, and any concerns.
The researcher may ask follow-up questions. Only respond as the persona.
First question: What is your first impression of this new checking account?
3. Generate initial responses: For each segment, run the prompt through your chosen AI model (e.g., GPT-4), generating 5–10 varied responses by tweaking the prompt wording or using model temperature settings to capture a range of attitudes.
4. Ask targeted follow-up questions: Based on the first set of answers, add one or two follow-up prompts (e.g., ""Would you consider switching from your current account? Why or why not?"" or ""What would make you feel more comfortable with a digital-only product?"") and collect additional responses for each persona.
5. Thematically code responses: Review the AI outputs and tag key themes such as ""trust in security,"" ""interest in fee savings,"" ""concerns about lack of branches,"" or ""enthusiasm for convenience.""
6. Compare and summarize: Identify which features and messages are most or least appealing for each segment, and note any objections or questions that come up repeatedly. Highlight clear differences in priorities or hesitations across segments.
🤔 What should I expect?
You will gain a quick, qualitative sense of which customer types are most likely to adopt the new product, what features drive positive or negative reactions, and what concerns must be addressed in marketing or product design. This allows your team to refine messaging, adjust features, or plan targeted follow-up research before committing resources to a full rollout or large-scale traditional study.



