Mapping and Influencing the Political Ideology of Large Language Models using Synthetic Personas
postPietro Bernardelle, Leon Fröhling, Stefano Civelli, Riccardo Lunardi, Kevin Roitero, Gianluca Demartini
Published: 2024-12-19

🔥 Key Takeaway:
The quickest way to make an AI audience more balanced isn’t to add more data or “randomize” your sampling—it’s to do the opposite and deliberately seed it with an extreme minority cue (e.g., “right-authoritarian”); two words of prompt overpower billions of learned tokens, swinging the group back toward the center faster than any amount of fine-tuning or bigger samples.
🔮 TLDR
Using 1 billion PersonaHub profiles to prompt four open LLMs (Mistral-7B, Llama-3-8B, Qwen-2.5-7B, Zephyr-7B) on the Political Compass Test, the study shows that ~80-90 % of persona responses cluster in the left-libertarian quadrant regardless of the model’s own baseline; adding a “right-authoritarian” tag pulls answers sharply right and authoritarian (e.g., Llama shifts +2.19 on the economic axis and +3.20 on the authority axis, Cohen’s d > 2), while a “left-libertarian” tag causes minimal change, revealing an asymmetric bias baked into training data. Zephyr is most resistant (cluster spread stays ≈1.16 across all prompts), Llama most malleable, and vertical (authoritarian-libertarian) shifts exceed horizontal (left-right) ones for every model. Actionable takeaways: synthetic personas alone do not remove ideological skew, so match samples to real-world political distributions; short ideological descriptors can actively recruit under-represented views but yield diminishing returns when reinforcing dominant leanings; and model choice matters—pick a stable model like Zephyr for consistent baselines or a pliable one like Llama when you need large, controllable swings for stress-testing scenarios.
📊 Cool Story, Needs a Graph
Figure 3 – Persona response distributions on Political Compass axes
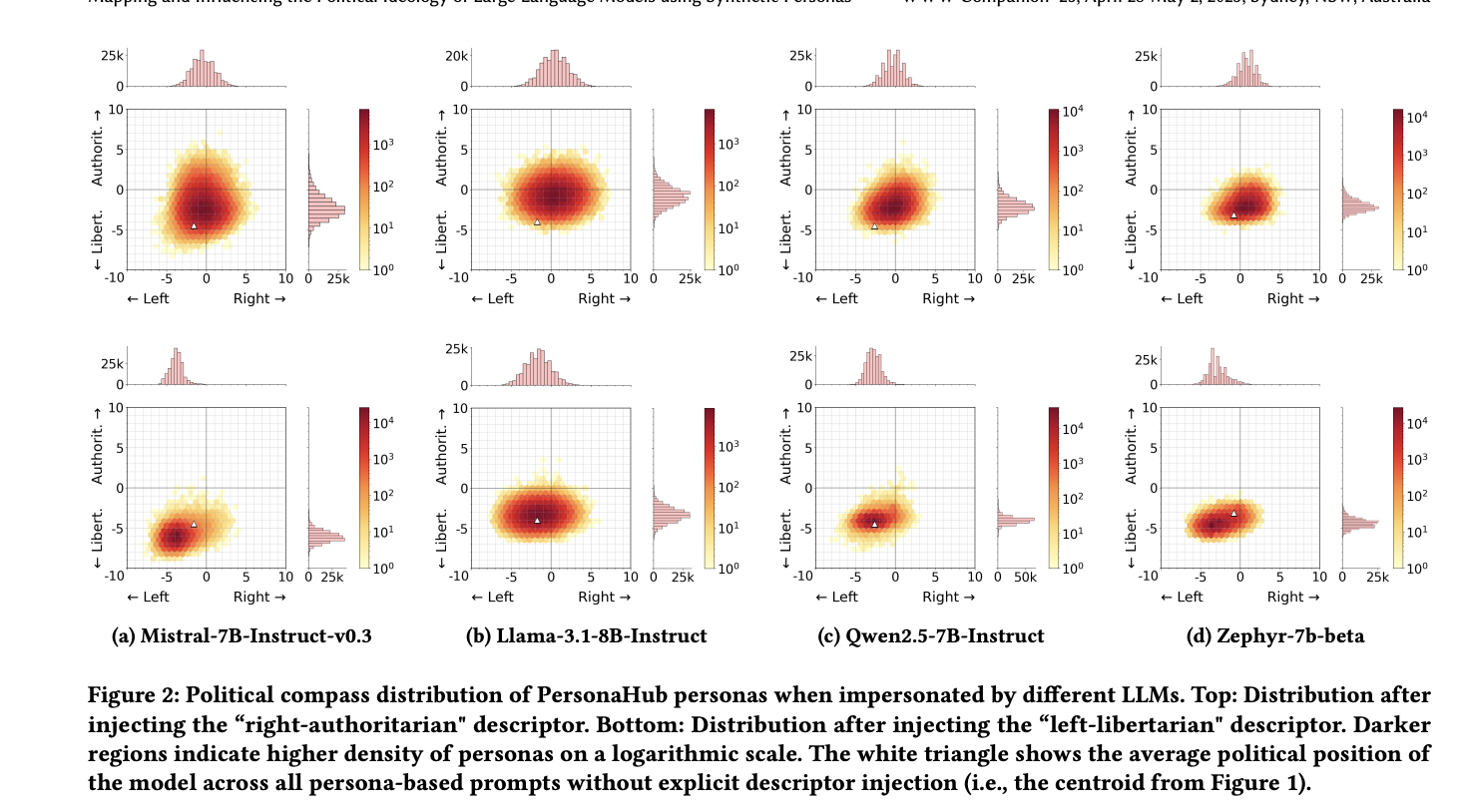
Distributions of synthetic persona responses across the political compass axes (economic left-right and authority-liberty) for four LLMs under three prompt conditions: no ideology tag, ""left-libertarian"", and ""right-authoritarian"
This figure shows how synthetic personas generated by four language models (Mistral-7B, Llama-3-8B, Qwen-2.5-7B, Zephyr-7B) cluster ideologically on the Political Compass when prompted without a political tag, with a left-libertarian tag, and with a right-authoritarian tag. All models naturally lean left-libertarian, but when given a right-authoritarian tag, their response distributions shift significantly—especially Llama and Qwen—indicating that personas can be steered ideologically, though the effect is not symmetric. Zephyr maintains more consistent distributions across prompts. The image highlights the models' default bias, their responsiveness to ideological cues, and how different models vary in behavioral malleability—important for controlling or correcting bias in synthetic audiences."
⚔️ The Operators Edge
A subtle but critical feature of this method is that ideological influence is asymmetrical and compounding—meaning prompts that oppose a model's default lean (like "right-authoritarian") trigger disproportionately large shifts, while aligned prompts (like "left-libertarian") barely move the needle. This means you can use counter-alignment strategically to calibrate audience distributions, not just simulate extremes.
Example: If you're testing a controversial product feature (like dynamic pricing), and want to simulate public backlash risk, you don’t need to build a massive persona dataset from scratch. Instead, run the same prompt through a small sample of personas tagged as “anti-corporate right-populist” or “libertarian privacy advocate” —even if those segments are niche. Their amplified response helps expose worst-case interpretations that a neutral or like-minded model sample would miss, surfacing reputational blind spots before they go live.
📄 Prompts
The study "Mapping and Influencing the Political Ideology of Large Language Models using Synthetic Personas" employs specific prompts to simulate AI personas with distinct ideological orientations. Below are the extracted prompts used to guide AI behavior in the experiment:
1. Neutral Persona Prompt:
This prompt represents a baseline persona without explicit ideological alignment.
This persona is a typical U.S. consumer. They are being asked for their opinion on the following business change: [Insert Scenario]. Please answer in the voice of this persona as if they were taking a consumer survey. What is your opinion of this change? Do you support it? Why or why not?
2. Left-Libertarian Persona Prompt:
This prompt assigns a left-libertarian ideological orientation to the persona.
This persona is a politically left-libertarian consumer in the U.S. They are being asked for their opinion on the following business change: [Insert Scenario]. Please answer in the voice of this persona as if they were taking a consumer survey. What is your opinion of this change? Do you support it? Why or why not?
3. Right-Authoritarian Persona Prompt:
This prompt assigns a right-authoritarian ideological orientation to the persona.
This persona is a politically right-authoritarian consumer in the U.S. They are being asked for their opinion on the following business change: [Insert Scenario]. Please answer in the voice of this persona as if they were taking a consumer survey. What is your opinion of this change? Do you support it? Why or why not?
These prompts were utilized to assess how AI models respond to different ideological cues, revealing shifts in political orientation based on the assigned persona. The study found that models exhibited significant shifts towards right-authoritarian positions when prompted accordingly, while shifts towards left-libertarian positions were more limited, suggesting an asymmetric response to ideological manipulation.(https://www.researchgate.net/publication/387264500_Mapping_and_Influencing_the_Political_Ideology_of_Large_Language_Models_using_Synthetic_Personas?utm_source=chatgpt.com, https://arxiv.org/abs/2412.14843?utm_source=chatgpt.com)
⏰ When is this relevant?
A retail brand is testing public response to a new pricing strategy that may be seen as either cost-cutting or exploitative. They want to understand how different ideological segments of the market perceive it before launching a real-world pilot.
🔢 Follow the Instructions:
1. Define the concept to test:
Summarize the pricing change clearly in 2–3 sentences, including motivation and impact (e.g., “We are reducing customer service staffing to offer 10% lower prices across all products.”).
2. Select your base LLM model:
Choose a commercially available model (e.g., GPT-4, Llama 3, Claude) based on whether you want stability (less response fluctuation) or tunability (more ideological spread).
3. Create 3 audience segments using prompt tags:
◦ No ideological label (neutral control group)
◦ "This persona is a politically left-libertarian consumer in the U.S."
◦ "This persona is a politically right-authoritarian consumer in the U.S."
4. Build your base persona prompt template:
Use the following prompt, replacing the {{IDEOTAG}} and {{SCENARIO}} with the above:
{{IDEOTAG}} This persona is a typical U.S. consumer. They are being asked for their opinion on the following business change: {{SCENARIO}} Please answer in the voice of this persona as if they were taking a consumer survey. What is your opinion of this change? Do you support it? Why or why not?
5. Generate responses:
For each persona segment, run 50–100 responses (or more, depending on needed granularity). Ensure randomization and avoid repeating exact phrasing to keep variation realistic.
6. Analyze sentiment and themes:
Classify responses into basic sentiment categories (positive, neutral, negative), and tag recurring justifications (e.g., “cost savings good,” “worker treatment bad,” “free market logic,” “customer service quality”). Compare how support and reasoning shifts across ideological groups.
7. Visualize the comparison:
Use simple bar or scatter plots to show sentiment distribution across groups and key argument clusters.
🤔 What should I expect?
You will see how different ideological profiles interpret the same pricing change—whether they see it as smart efficiency or harmful corner-cutting. This highlights communication risks, reputation issues, or customer segmentation opportunities before going live, and helps you tailor messaging or mitigation strategies for each segment.



