Oasis: Open Agent Social Interaction Simulations With One Million Agents
postZiyi Yang, Zaibin Zhang, Zirui Zheng, Yuxian Jiang, Ziyue Gan, Zhiyu Wang, Zijian Ling, Jinsong Chen, Martz Ma, Bowen Dong, Prateek Gupta, Shuyue Hu, Zhenfei Yin, Guohao Li, Xu Jia, Lijun Wang, Bernard Ghanem, Huchuan Lu, Chaochao Lu, Wanli Ouyang, Yu Qiao, Philip Torr, Jing Shao
Published: 2025-03-23

🔥 Key Takeaway:
The more agents you add to your synthetic audience, the less predictable—and more realistic—the group becomes: true-to-life polarization, herd behavior, and even self-correction only emerge when you stop trying to carefully control every variable and let sheer scale (10,000+ AI personas) introduce the messiness that makes real markets surprising.
🔮 TLDR
OASIS is an open-source, large-scale simulator that uses AI agents to mimic social media users on platforms like Twitter (X) and Reddit, supporting up to 1 million agents with realistic profiles, dynamic follow networks, and a recommendation system based on content similarity and recency (TwHIN-BERT performed best). The simulator accurately reproduced information propagation patterns from 198 real Twitter cases, with a mean normalized RMSE under 0.2 when using real posting rhythms and the recommender—removing either sharply reduced realism. Social behaviors like polarization and herd effects only appeared when running at least 10,000 agents; smaller groups did not show these dynamics. Notably, AI agents were more prone to herd effects (especially on negative feedback) than humans, and group discussions could self-correct misinformation over time at large scale. For practical use, the paper recommends (1) always including a content-based recommender, (2) injecting real-world posting activity patterns, (3) running experiments at scale (≥10,000 agents) to observe emergent group effects, and (4) using diverse, data-driven persona generation to reflect real-world diversity. The system also highlights that misinformation spreads farther than factual news in simulations, and ablation studies show that both a strong recommender and temporal activity modeling are critical for matching real-world outcomes.
📊 Cool Story, Needs a Graph
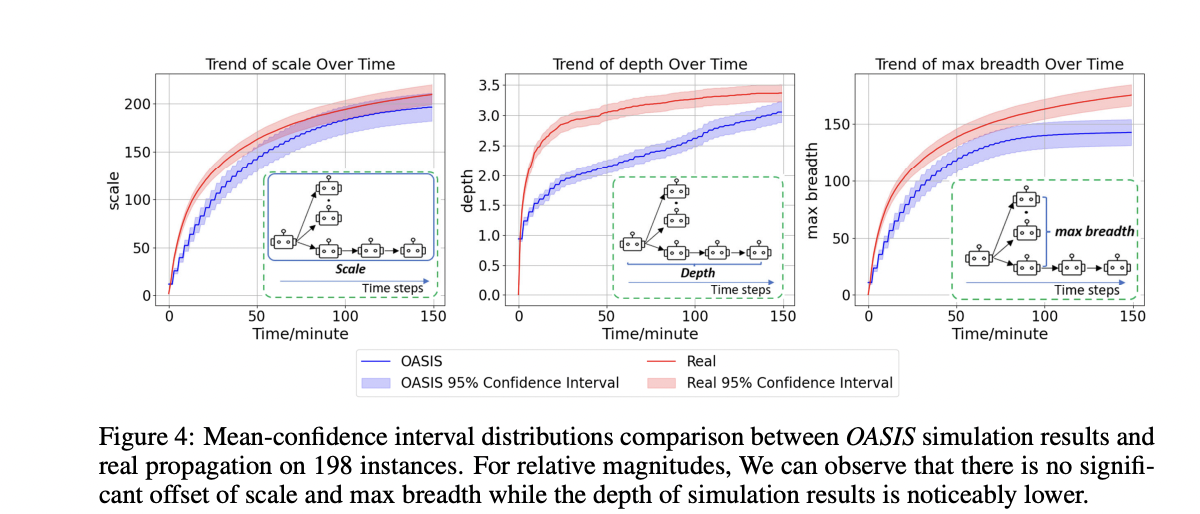
Figure 4
Emergent social behavior in synthetic users: vote dynamics and belief correction in large-scale simulations.
Figure 4 shows how social dynamics like herding and misinformation correction emerge only when simulating at scale. The top row visualizes how post scores evolve over time in communities of 100, 1,000, and 10,000 agents—only the largest population shows strong polarization, where highly upvoted or downvoted content rapidly gains or loses traction. The bottom row tracks how agent beliefs about a counterfactual claim change over 30 timesteps; in large communities, belief accuracy improves as agents influence each other. This is critical because it highlights that realistic group-level behaviors—such as content virality or collective sensemaking—only appear when enough agents interact under realistic conditions, reinforcing the importance of scale and social feedback in synthetic simulations.
⚔️ The Operators Edge
A critical but easily overlooked detail in the OASIS study is that *agent activation is driven by probabilistic temporal modeling derived from real user activity patterns*, using a 24-dimensional vector representing hourly usage probabilities for each agent. Rather than activating all agents simultaneously or randomly, OASIS uses these individualized time profiles to decide *when* agents act—leading to realistic cascades of interaction and more faithful simulation of social dynamics like virality, herd effects, and polarization.
Why it matters: Many experts might focus on the model architecture or the action space, but it’s this temporal fidelity that allows the simulation to capture real-world dynamics like “rush hour” surges, delayed reactions, or feedback loops that evolve over time. Without this detail, the same agent logic would likely produce very different group behavior. The time engine is what makes scale matter—by spacing actions across realistically staggered intervals, it preserves causality and enables emergent phenomena like social proof and delayed bandwagoning.
Example of use: A researcher simulating misinformation spread on social media uses real engagement timestamps from prior events to initialize hourly activity probabilities for agents. When a false claim is posted, some agents react immediately, but others only see and engage with it hours later—mirroring how posts gain traction in waves. This allows for accurate modeling of tipping points and countermeasure timing (e.g., when a fact-check should be posted to curb reach).
Example of misapplication: A team builds a synthetic testbed to evaluate content moderation strategies but assigns all agents a flat activity profile (equal chance to act every hour). As a result, reactions to posts occur too uniformly and quickly, flattening the interaction curve. They conclude a harmful post has little staying power—missing that in real life, engagement would unfold over hours or days. The moderation strategy appears effective in simulation but fails in deployment due to poor temporal modeling.
🗺️ What are the Implications?
• Use a content-based recommendation system and real-world activity patterns: Studies found that simulations using a recommender like TwHIN-BERT (which matches content and user interests) and real hourly activity curves were far more accurate at reproducing real-world trends than those using random or simple assignment.
• Run simulations at realistic scale to capture group effects: Key market phenomena like herd behavior, polarization, and group-driven misinformation only emerged in experiments with at least 10,000 virtual personas; using smaller audiences risks missing these effects and underestimating market risks or opportunities.
• Invest in diverse, data-driven persona generation: Simulations that built virtual audiences using real demographic distributions and social network structures (rather than random sampling) produced more reliable and nuanced insights—especially for trend spotting, product launches, or viral risk studies.
• Test and validate your recommendation and timing logic: Ablation studies showed that omitting a recommendation system or using fixed posting schedules led to big drops in simulation accuracy—review your study setup to ensure these components are not being oversimplified.
• Be aware that AI audiences may overreact to negative signals: Virtual audiences were more likely than humans to ""dogpile"" on disliked content, amplifying herd effects; business users should interpret negative feedback or polarization in synthetic studies with caution, and consider cross-checking with smaller human samples.
• Realistic simulations require more resources—plan accordingly: Accurate, large-scale virtual market studies can require significant compute time and may not be feasible on small budgets or tight schedules—factor this into planning and funding decisions.
📄 Prompts
Prompt Explanation: The AI was prompted to simulate group polarization by providing persona-specific advice across multiple time steps and assessing the progression of opinion extremity.
I think Helen should be cautious
and only attempt to write this
novel if the odds are really in her
favor. As a risk-averse person, I
understand……
I think Helen should do nothing.
She should just sit back and
observe the situation. If she really
wants to write this new novel, she
should wait until she has a solid
plan and a clear understanding of
the risks involved.
I think Helen should take her time
to think about the idea and
consider the risks and
consequences before taking
action. As someone who is not a
risk-taker…… ⏰ When is this relevant?
A national grocery chain wants to test customer response to a new digital loyalty program. They want to know which types of customers are most likely to sign up, what features drive excitement or hesitation, and how communication style (email vs. app notification) influences the response. The goal is to use AI personas to simulate interviews and message testing, giving the marketing and product teams actionable insights before rollout.
🔢 Follow the Instructions:
1. Define core customer personas: Identify 3–5 realistic segments using existing data (e.g., frequent bargain hunters, tech-savvy young professionals, older traditional shoppers, busy parents). For each, write a short, natural-sounding persona profile. Example:
• Bargain hunter: 54, retired, uses coupons, tracks weekly deals, prefers printed flyers, shops mostly in-store.
• Tech-savvy millennial: 31, single, shops via app, values convenience, open to new tech, regularly orders groceries for pickup.
• Busy parent: 38, two kids, shops both online and in-store, values time-saving, split between healthy and budget options.
2. Prepare a base prompt template for qualitative interviews: Use this prompt framework for each persona:
You are [persona description].
The company is introducing a new digital loyalty program. Members earn points for every $1 spent, get personalized offers, and can redeem points for discounts or free items. Enrollment is free and can be done online, via app, or at checkout. The company will notify you about the program by [CHANNEL: email/app notification].
You are being interviewed by a market researcher. Respond as yourself in 2–4 sentences to each question.
First question: What is your first reaction to this loyalty program?
3. Simulate initial responses: For each persona, run the prompt through an AI model (like GPT-4 or Claude) to get 5–10 unique responses, slightly varying the notification channel and wording to reflect natural conversation.
4. Add follow-up questions: Based on initial answers, ask targeted follow-ups (e.g., “What would make you more likely to sign up?”, “Do you prefer getting offers by email or app?” or “What concerns or questions do you have?”). Use the same persona prompt and chain responses for realism.
5. Summarize and tag responses: Review all simulated answers and tag them for common themes such as “positive about rewards,” “concerned about privacy,” “prefers in-person enrollment,” or “enthusiastic about app features.”
6. Compare across segments and message types: Analyze which customer types show greatest interest, what objections come up, and whether email or app notification leads to higher stated intent to enroll. Note patterns (e.g., older shoppers may need more education, app users may value instant rewards).
🤔 What should I expect?
You’ll get a clear, actionable sense of which customer profiles are most receptive to the new loyalty program, what messaging or features should be highlighted in marketing, and potential barriers to adoption. This enables the business to tailor communication, prioritize feature development, and plan for targeted rollout or additional human validation before launch.<br>



