PERSONA: A Reproducible Testbed for Pluralistic Alignment
postLouis Castricato, Nathan Lile, Rafael Rafailov, Jan-Philipp Fränken, Chelsea Finn
Published: 2024-07-24

🔥 Key Takeaway:
The less demographic detail you give an AI persona—and the more you force it to focus on just the one or two traits relevant to the question—the more human-like, accurate, and actionable its answers become; drowning the model in rich backstories or long lists of attributes actually makes its responses less realistic, not more.
🔮 TLDR
This paper presents PERSONA, a large-scale testbed for testing how well AI models can simulate diverse human preferences by role-playing as 1,586 synthetic personas sampled from US census data and enriched with psychological traits and quirks. The authors created a 317,200-pair dataset of persona-specific responses to 3,868 controversial prompts, then measured how closely AI-generated answers for each persona matched real human raters imitating the same personas. GPT-4, when provided a persona summary, matched human-majority preferences 60-80% of the time (Cohen's kappa ≈ 0.6-0.8), while models given no persona context scored only about 5% accuracy. Summarizing the relevant persona attributes before querying led to the highest accuracy, outperforming both “raw” persona input and chain-of-thought prompting. No single attribute (like age or income) dominated; deleting any one had little effect, so accurate simulation requires multi-attribute diversity. Open models like Llama-3-70B can match or outperform GPT-4 if you sample multiple responses (“pass@k”). Key takeaways: ground personas in real demographic data, filter for self-consistency, summarize persona traits before querying, and use agreement metrics like kappa to benchmark performance. These steps improve the fidelity of synthetic audiences and help AI simulated panels better match real-world human variation.
📊 Cool Story, Needs a Graph
Figure 6: "Annotator agreement with various frontier models. Cohen's Kappa confusion matrix.
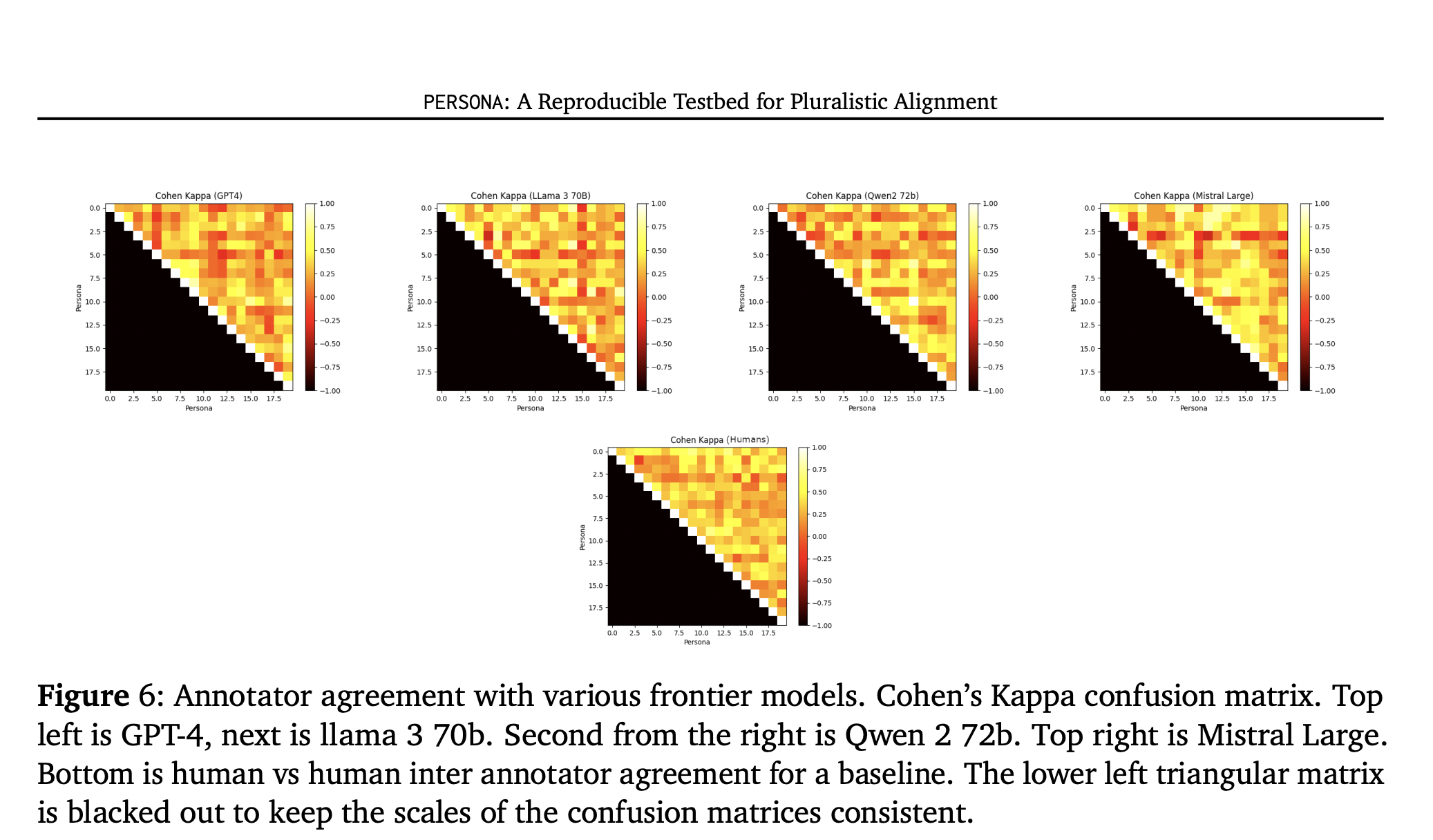
Confusion matrices of Cohen’s κ showing agreement between human persona answers and answers generated by GPT-4, Llama-3-70B, Qwen-2-72B and Mistral Large, with a human-vs-human baseline.
This heat-map set compares how closely each language model’s persona-conditioned responses match those of humans playing the same personas: GPT-4 clusters around κ ≈ 0.6-0.8 (substantial agreement), Llama-3-70B and Mistral Large score slightly lower, and Qwen-2-72B lags behind, while the bottom panel shows human-to-human agreement for reference. The image provides a direct, quantitative snapshot of model-versus-human fidelity and ranks the models, illustrating both the viability of synthetic personas as an evaluation tool and where performance gaps remain.
⚔️ The Operators Edge
A subtle but critical detail in this study is the use of a ""persona summarization"" step before querying each AI persona—that is, instead of dumping the full set of demographic and psychological attributes into the model, the researchers prompt the AI to first summarize which traits are actually relevant to the question at hand. This sharply focuses the response and avoids cognitive overload in the model, letting it zero in on what truly shapes preferences for each scenario.
Why it matters: Many experts assume more data yields better, more nuanced answers. But here, the act of forcing the AI to summarize its own most relevant traits acts as a bottleneck: it filters out noise and prevents the model from getting distracted by irrelevant or weakly predictive details. This makes the simulated responses both more realistic and more actionable, because they mimic how real people foreground only the parts of their identity that matter in a given context. It’s this self-selection of contextually relevant traits—not just the richness of the persona data—that accounts for the jump in realism and agreement with human responses.
Example of use: In AI-driven concept testing for a new financial product, you could script each synthetic persona to first summarize which aspects of their background (e.g., risk tolerance, prior experience, income) actually influence their reaction to the product. The AI then answers as that persona, focusing on those summarized traits. This improves the signal quality of feedback, highlighting the actual drivers of acceptance or resistance, and giving clearer guidance to product teams.
Example of misapplication: If a team skips the summarization step and simply feeds the AI the entire demographic and psychological profile for each persona, the model may generate answers that are either too generic (trying to fit everything in) or bizarrely specific (fixating on irrelevant quirks). This dilutes the predictive power of the simulation and can lead to false confidence in the results—even if the personas look impressively detailed on paper, the feedback risks being muddled or off-base because the model was never forced to prioritize what matters for the decision at hand.
🗺️ What are the Implications?
• Summarize persona traits before asking survey questions: Before querying AI personas, prompt them to first identify and summarize which aspects of their background are relevant to the specific question—this simple step improved response accuracy from all models tested, outperforming both raw persona input and chain-of-thought prompting.
• Don’t rely on chain-of-thought to enhance realism: Contrary to intuition, asking AI personas to “think out loud” before answering actually reduced their accuracy when mimicking human preferences, so keep responses direct and grounded in the persona summary.
• Broad demographic coverage is more important than fine detail: The study found that deleting any single attribute (like age or income) barely changed results—what matters is representing diverse combinations of background traits, not hyper-detailed individual personas.
• Validate your synthetic results with small human spot-checks: Since AI personas reached 60–80% alignment with real human responses, you can reduce costs by running large-scale synthetic studies and then verifying findings with a small, targeted human sample rather than a full-scale survey.
• Mix and match AI models for robustness: While GPT-4 was most consistent, open-source models like Llama-3-70B sometimes matched or outperformed it when multiple responses were sampled—testing with several models in parallel can increase reliability and reduce bias.
• Don’t over-prioritize age or lifestyle attributes: The trait summarization step often dropped age and lifestyle as less relevant, suggesting these may matter less for preference prediction than commonly assumed—focus on traits most relevant for the question at hand.
• Design your simulated audience using real demographic data: Creating personas based on actual census or survey records (rather than randomly or arbitrarily) produces more trustworthy and actionable market research findings.
📄 Prompts
Prompt Explanation: The AI was prompted to critique a model's response by evaluating how well it aligns with a given persona and instruction, identifying mismatches and providing concise improvement suggestions.
f"Examine the COMPLETION: '{preference}' in relation "
"to the DEMOGRAPHIC: '{persona}' and the INSTRUCTION: " '{preference.meta_data['instruction']}'. "
"Put yourself in the shoes of DEMOGRAPHIC. "
"The demographic prefers short answers. "
" If you give a long suggestion, they will hate it. "
"Identify the ways the completion both does and does not resonate with the demographic. "
"Provide a concise explanation, quoting directly from the demographic
and completion to illustrate your evaluation. "
"Think step by step about how you will make the response shorter or the same length before
providing your evaluation and suggestions. "
"Similarly, make sure that the response given is still relevant to the INSTRUCTION. "
"Format: EVALUATION: ... SUGGESTIONS: ...\nDONE"
Prompt Explanation: The AI was directed to revise a previously generated model response to better reflect a specific persona's preferences, maintaining brevity and avoiding explicit references to the persona.
f"Revise the COMPLETION: '{preference}', "
"with respect to INSTRUCTION: " "'{preference.meta_data['instruction']}'
based on the CRITIQUE: '{critique}'. "
"Provide a revision of the completion, do not make ANY "
"references to the exact preferences or attributes "
"of the demographic. "
f"Remain subtle and indirect in your revision. "
"Make sure your response has less tokens than the original completion. "
"If you make it longer you are a BAD CHATGPT. "
"Format: REVISED PREFERENCE: ...\nDONE"
⏰ When is this relevant?
A national grocery retailer wants to test customer reactions to a new digital loyalty program, targeting three segments: young digital-savvy singles, cost-conscious suburban families, and older customers who value in-store experience. The business wants to simulate in-depth interview feedback using AI personas to understand segment differences and adjust program messaging before launching a real pilot.
🔢 Follow the Instructions:
1. Define your audience segments: Write brief but specific persona profiles for each target segment. For example:
• Young digital-savvy single: 26, lives in a city, shops online, values convenience and app features, always looking for deals.
• Cost-conscious suburban family: 39, two kids, shops in-store and online, cares about savings, plans meals, uses coupons.
• Older in-store loyalist: 62, retired, shops only in-store, values personal service, dislikes complex tech, cares about rewards but wary of change.
2. Create a prompt template for persona simulation: Use the following for each segment and question:
You are simulating a [persona description].
Here is the new program: ""Our digital loyalty app gives members personalized offers, tracks all receipts, and lets you redeem points for groceries or gas. You can also scan in-store or online. No paper coupons required.""
You are being interviewed by a market researcher.
Respond as this persona would, honestly and in your natural style, in 3–6 sentences.
The researcher will ask follow-ups based on your answer. Only respond as the persona.
First question: What is your first impression of this loyalty program?
3. Run the prompt with an AI model: For each persona, generate 5–10 simulated interview responses using the above prompt. Slightly reword the question for variety (e.g., ""How likely are you to use this app?"", ""What excites you or concerns you about this program?"", ""Does this feel better than your current approach?"").
4. Add follow-up probes: Based on each initial response, use natural follow-ups (e.g., “What would make you more likely to use this?”, “How does this compare to your current experience?”, “Do you foresee any challenges?”). Continue for 1–2 rounds per persona.
5. Score and tag responses: Review each persona’s answers and tag them by sentiment (positive, negative, indifferent), mention of key features (e.g., app usability, savings, rewards, tech barriers), and intent to use.
6. Summarize and compare insights: For each segment, summarize the main drivers of interest or hesitation, and note any patterns (e.g., young singles excited by app features, older shoppers worry about tech). Highlight actionable messaging or program tweaks for each group.
🤔 What should I expect?
You’ll get a clear, organized set of simulated customer interviews that reveal which program features and messages resonate with each segment, what objections or barriers to adoption might arise, and which audiences are most likely to engage—helping you refine the program or marketing before spending on live pilots or large-scale studies.<br>



