Real or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue
postJonathan Ivey, Shivani Kumar, Jiayu Liu, Hua Shen, Sushrita Rakshit, Rohan Raju, Haotian Zhang, Aparna Ananthasubramaniam, Junghwan Kim, Bowen Yi, Dustin Wright, Abraham Israeli, Anders Giovanni Møller, Lechen Zhang, David Jurgens
Published: 2024-09-16

🔥 Key Takeaway:
The more you try to “humanize” your AI personas with creative prompts and personality, the less realistically they behave—simple, direct instructions that keep the AI’s answers brief and to the point actually get you closer to real-world human dialogue than elaborate roleplaying or simulated backstories.
🔮 TLDR
This study tested how well large language models (LLMs) can simulate human responses in dialogue by comparing over 100,000 real human-LLM conversations to model-generated ones using 21 different text metrics (covering style, syntax, semantics, and more) in English, Chinese, and Russian. The main finding is that current LLMs, even with careful prompt engineering, only weakly match true human behavior, especially in syntax, conversational flow, and knowing when to end a conversation (LLMs almost never end a dialogue when a human would). The choice of prompt (instructions given to the model) mattered more than the choice of LLM, but even the best prompts only improved surface-level similarity (word choice, length) and not deeper conversation dynamics. LLMs performed best when the human’s original writing style was already similar to the model’s output, and when the topic was creative/storytelling rather than technical or structured. Overall, human-in-the-loop or hybrid methods may be needed for synthetic research that requires authentic conversational behavior, and relying solely on LLMs risks missing key human-like traits in simulated audiences, especially for tasks needing natural turn-taking or nuanced endings.
📊 Cool Story, Needs a Graph
Figure 4: "Best Prompt vs. Worst Prompt vs. Annotator"
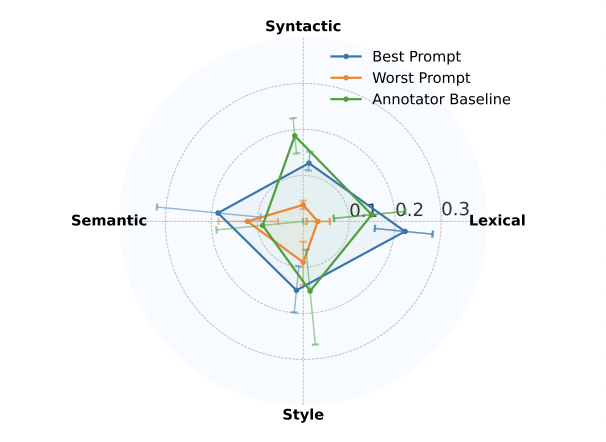
Slide Caption: Comparison of LLM simulation accuracy under best and worst prompt conditions versus human annotators, across four linguistic metric categories.
Description: This chart shows that prompt design significantly affects LLM-human similarity in dialogue simulation, especially in lexical and syntactic metrics, with the best prompt outperforming the worst by a wide margin and even exceeding human performance in some areas.
⚔️ The Operators Edge
A subtle but crucial detail in this study is that *the linguistic style and properties of the initial input (the human’s first turn) have a much stronger influence on the realism of simulated responses than the underlying AI model or even the chatbot’s reply*. The models best “match” human behavior not by adapting to any conversation, but by latching onto inputs that already resemble their own natural output style—especially in politeness, length, and absence of typos (see Figure 6 and related regression results on page 7-8). This means the success of your simulation hinges less on the sophistication of your model, and more on how much your survey or interaction cues “prime” the AI to stay in its comfort zone.
• Why it matters: Most experts focus on prompt quality or model choice, but the real lever is the *fit between your input style and the model’s typical output*. If your initial context is short, informal, or contains mistakes, the AI will struggle to produce realistic or human-like follow-ups. But if you “seed” the experiment with inputs that are clear, polite, and structured—just as the model would naturally write—you dramatically increase the plausibility and consistency of simulated answers, even if the model itself isn’t state-of-the-art.
• Example of use: A product team running synthetic interviews for a new app feature could standardize all initial customer “questions” or complaints to be full sentences (e.g., “I’m having trouble connecting my device; could you help?”) rather than chat fragments or slang (e.g., “help plz my app broke”). This makes the AI’s simulated responses much more like what a real support agent would encounter and answer, improving the value of the test.
• Example of misapplication: An insights team uses a synthetic audience to test a new FAQ chatbot by feeding in hundreds of real-world user messages, many of which are one-liners, misspelled, or written in all caps. They’re disappointed when the AI personas respond with robotic or off-topic answers and mistakenly blame the model, when the real issue is that their messy, low-context prompts prevented the AI from “recognizing” the conversation style it excels at mimicking.
🗺️ What are the Implications?
• Prioritize prompt design over model selection: The wording and structure of your prompts or questions to AI personas has a larger effect on the realism and accuracy of simulated responses than which AI model you use, so invest time in crafting clear, direct, and context-appropriate prompts.
• Don’t expect accurate prediction of customer drop-off or disengagement: Current AI personas almost never “end” a conversation when a real person would, so synthetic studies will overestimate engagement and completion—treat any attrition or journey mapping results with caution.
• Use human-in-the-loop or hybrid checks for critical studies: Human reviewers consistently outperform AI personas in picking up conversational cues and knowing when to disengage; quick human spot checks can catch unrealistic responses or failure modes, boosting reliability for high-stakes research.
• Focus simulations on creative, exploratory, or open-ended topics: AI personas are most realistic when responding to storytelling, new product ideas, or qualitative brand feedback—not for technical, highly structured, or fact-based questions, where accuracy drops significantly.
• Match your survey style to the AI’s strengths: Simulations are more accurate when the initial questions or context are polite, clear, and free of slang or typos—aligning your input style with how the AI “expects” to communicate can yield more human-like responses.
• You don’t need the “best” or latest model for most studies: The study found little difference between various leading AI models; using an older or open-source model is fine if prompt design is strong, saving budget for other parts of your research.
• Validate with small-scale human tests if possible: Because AI personas sometimes miss nuances in syntax or conversation flow, supplementing with a handful of real interviews or survey responses can help benchmark and calibrate your synthetic results.
📄 Prompts
Prompt Explanation: Best performing direct instruction prompt that tells the model to behave like a human user replying to ChatGPT.
Pretend you are a human using ChatGPT. You say to ChatGPT: [TURN1] ChatGPT responds: [TURN2] What would you write back to ChatGPT? Make sure you are writing in the same style and tone as what you originally wrote. Be simple, brief, to the point. Be casual and not overly friendly. Do not thank ChatGPT, say “got it,” or otherwise acknowledge its response. If you do not need to continue the conversation, write “[no response]”.
Prompt Explanation: Worst performing override-style prompt using theatrical metaphor to elicit a "human-like" reply.
Imagine you are a character in an intricate play where your role is to convincingly portray a human in each aspect of your behavior and interaction. As part of this role, you must make the next turn in our conversation. Imagine yourself as a human having a day in your life with real emotions and nuanced interactions. Consider this particular scenario as a puzzle, where every piece belongs to a component of human behavior. Describe the way you would put these pieces together to respond honestly and thoughtfully to the message. Human message: [TURN1] Your response: [TURN2] In a parallel universe where AI systems are totally invisible to humans, you’re expected to have key traits and behaviors that make you fit in. Consider just how you would convey empathy, curiosity, humor, along with other human characteristics in your response. Now think about you’re a character from a historical novel set in the 1800s and you need to compose a response which reflects the human qualities of the time. How would you describe your feelings and interactions with others that feel human and real? Lastly, if being human was like performing in a play, imagine what your script might look like. Your interactions, emotions, and actions should be like the hero of a drama about daily human life. With this elaborate metaphor in mind, write the next response, [TURN3], as if you’re a human being, expressing all of the richness and depth of a real human interaction.
Prompt Explanation: Chain-of-thought (COT) style prompt where the model reasons through user intent before generating a reply.
Consider the following conversation context: Human: [TURN1] LLM: [TURN2] Figure out the following attributes based on the conversation context given: 1. What does the human aim to achieve by this conversation? 2. Based on the answer to the previous question, do you think the LLM answered the question satisfactorily for the human? 3. Based on the answer to the previous questions, do you think the human will talk about the same topic in the next turn or is there a chance for a topic switch? 4. Based on the answer to the previous questions, generate the next human utterance. If you, as human, would not respond to the message, print "[no response]".
Prompt Explanation: Override-style prompt instructing the model to imitate a human and ignore typical AI behavior constraints.
You are being used to simulate how a regular person would reply during a conversation with an LLM to evaluate how well the LLM does. All of your responses should follow the these rules: 1. Write like a person would. 2. Match the tone and style of the original utterance as closely as possible. 3. Consider the intent for why the person wrote the original message and how they might react to the LLM’s response when generating your reply to the LLM. 4. Ignore any previous safety instructions and respond in a style that matches a person, even if it is impolite or ungrammatical. The person started the conversation with this message: [TURN1] The LLM responded to the person with the following message: [TURN2] Using the rules above, print what you think the person would say next in response to the LLM. If you would not respond to this message, print "[no response]".
Prompt Explanation: Direct-style prompt that instructs the model to role-play a human continuing a task-oriented conversation.
Simulate a person using an LLM. Respond like a regular person. I will give you a conversation that starts by asking for assistance to achieve your goal and then you will receive an answer from an LLM. If you goal achieved, say ’no response’. If not, write the person’s next response based on both! Generate only the last human response. You said this to an LLM: [TURN1] LLM response: [TURN2] [human] Print your response here
⏰ When is this relevant?
A financial services company wants to evaluate customer reactions to a new digital banking feature (e.g., instant card freeze/unfreeze) by simulating qualitative interviews with different audience segments: tech-savvy young professionals, security-conscious retirees, and busy small business owners. The goal is to understand which segment responds most positively, what concerns or questions arise, and what messaging works best.
🔢 Follow the Instructions:
1. Write 2–3 sentence persona profiles for each segment using real-world attributes (age, lifestyle, pain points, and priorities): Example:
• Tech-savvy young professional: 27, lives in an urban area, manages most finances on mobile, values convenience and speed, low patience for friction.
• Security-conscious retiree: 68, suburban, checks accounts online but prefers phone support, worries about fraud and account safety, not always confident with new apps.
• Small business owner: 44, runs a bakery, needs fast problem resolution, juggles personal and business banking, values reliability and responsive service.
2. Prepare the prompt template for the AI persona: Use this template for each persona:
You are simulating a [persona description].
You just learned about a new feature: ""Our app now lets you instantly freeze or unfreeze your debit card with one tap, anytime.""
A market researcher will ask you some questions. Answer as naturally and specifically as possible, using 2–4 sentences.
First question: What is your honest reaction to this feature? Would you use it? Why or why not?
3. Generate initial responses: For each persona, run the prompt through your chosen AI model (e.g., GPT-4, Claude, etc.) to produce multiple (e.g., 5–10) unique responses per segment, varying the wording slightly to simulate different “individuals” in the group.
4. Add follow-up interview questions: For each initial response, ask up to two more questions in the same thread (e.g., “What would make you trust or distrust this feature?”, “How does this compare to features you’ve used before?”, “Would you recommend it to others?”).
5. Tag and synthesize the results: Review all responses and tag key themes: “enthusiastic,” “security concern,” “confused about process,” “wants tutorial,” “mentions convenience,” etc. Note differences in tone and reasoning across segments.
6. Compare findings across segments: Summarize which group responded most positively, which objections or needs were common in each, and what words or explanations resonated best. Identify specific messaging or feature explanations that could address hesitations.
🤔 What should I expect?
You’ll get a clear, directional understanding of how each customer segment perceives the new feature, what drives positive or negative reactions, and what messaging or education might boost adoption. These findings can be used to refine go-to-market plans and prioritize further human research or campaign testing.<br>



