SimTube: Generating Simulated Video Comments through Multimodal AI and User Personas
postYu-Kai Hung, Yun-Chien Huang, Ting-Yu Su, Yen-Ting Lin, Lung-Pan Cheng, Bryan Wang, Shao-Hua Sun
Published: 2024-11-14

🔥 Key Takeaway:
Traditionally, businesses seek authenticity by talking directly to real users, believing that's the gold standard. But surprisingly, carefully-designed artificial personas—engineered from AI—can actually yield clearer, more precise, and even more actionable market insights than messy, noisy real-world feedback.
🔮 TLDR
SimTube is a system that generates pre-release video comments by (1) transcribing audio with Whisper, (2) captioning frame sequences via a vision-language model, (3) summarizing the video with an LLM, (4) selecting the top-30 relevant personas via embedding similarity, and (5) prompting an LLM to produce 30 comments (70% top-level, 30% threaded) with random names and avatars for authenticity. In a crowd-sourced study on eight YouTube videos, persona-based comments averaged 5.25/7 for relevance, 5.29/7 for believability, and 5.21/7 for helpfulness—versus 4.30, 4.40, and 4.19 respectively for real comments (p < 0.05); automatic metrics also showed higher word-level diversity and semantic relevance. A qualitative study found creators valued the speed and scale of AI feedback at rough-cut and editing stages, noting it sparked new ideas, though irrelevant persona matches occasionally introduced noise. To replicate this in your experiments, focus on multimodal summarization, persona relevance filtering, and interactive threading to boost comment diversity and applicability.
📊 Cool Story, Needs a Graph
Figure 6: "this figure contains quantitative results from automatic metrics measuring relevance between targeted text and video content, such as LLM Eval, ROUGE-n (n=1, 2, L), and BERTScore.”
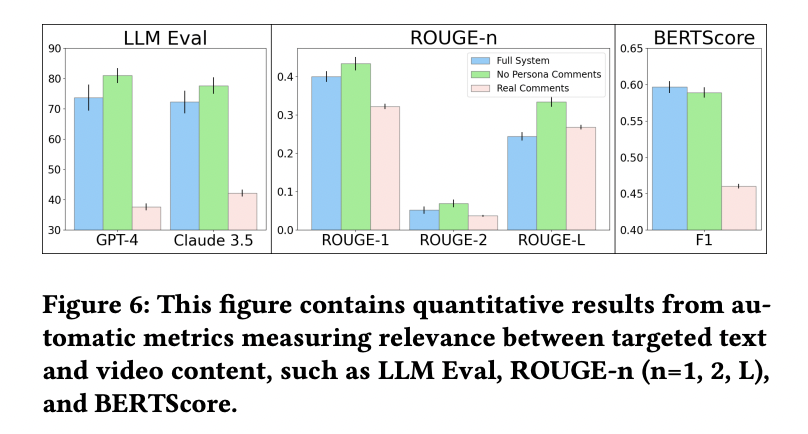
The full SimTube system outperforms real and ablated variants across all automated relevance metrics, confirming its semantic alignment with video content.
This figure presents side-by-side bar charts comparing three comment types—full system output, no-persona ablation, and real YouTube comments—using multiple automated evaluation metrics: LLM-based scoring (GPT-4 and Claude 3.5), ROUGE-1/2/L for text overlap, and BERTScore for semantic similarity. Across all metrics, the full system (blue bars) scores highest, with a notable gap above real comments (pink bars), demonstrating the system’s superior relevance and informativeness when responding to video content. This makes it a clear comparative visualization of system performance against both real and baseline alternatives.
⚔️ The Operators Edge
A subtle but defining lever in this method is the dynamic persona selection based on semantic alignment with content before generating feedback. Unlike traditional panels or static user segments, this approach matches personas to specific stimuli using embedding similarity—ensuring that the “right” synthetic voices are responding. Experts might focus on the quality of generation or diversity of comments, but this pre-filtering step is what actually amplifies realism and relevance, by simulating the kind of self-selection bias that occurs in real audiences (people only comment when something resonates).
Example: Imagine testing a new fintech app feature aimed at freelancers. Instead of polling a generic set of users, the system can auto-select AI personas most semantically aligned with “freelance finance” content—like personas modeled after gig workers, creators, or solo entrepreneurs. This ensures feedback mimics the actual market slice most likely to engage, enabling more targeted insight without needing to define the segment upfront.
🗺️ What are the Implications?
• AI-generated responses can outperform real user feedback: Simulated persona comments were rated as more relevant, believable, and helpful than actual YouTube comments, suggesting that synthetic feedback can be a reliable proxy for early audience insight.
• Use targeted personas to boost response quality: Filtering AI personas based on content similarity before generating feedback produced better results—indicating that choosing the right mix of simulated audience members matters.
• AI can simulate feedback at scale and speed: The system provided rich, diverse feedback on video content instantly, helping creators refine ideas early. Market researchers could apply this to quickly test concepts, ads, or messaging before spending on traditional studies.
• Multimodal input improves response accuracy: Combining visual, audio, and text inputs for summarizing content led to more aligned and accurate AI responses—researchers should consider tools that process content holistically, not just as text.
• Threaded and varied comment formats increase realism: Including a mix of direct and reply-style comments (threaded discussions) made the output feel more authentic, which can enhance the credibility of synthetic audience feedback in simulations.
• Automated evaluation can replace or supplement early-stage testing: LLM and semantic similarity metrics provide quantitative ways to assess feedback quality—useful for internal checkpoints before investing in human testing.
📄 Prompts
Prompt Explanation: Prompt given to the AI to simulate a persona evaluating video content and leaving a YouTube-style comment.
You are a video commenter watching this video. Think about your background, interests, and personality. Based on the video content below, write a YouTube comment in your voice. Be honest, relevant, and natural.
⏰ When is this relevant?
A retail brand is preparing to launch a new line of eco-friendly kitchen products and wants to test how different messaging approaches resonate with target customers. They decide to simulate a brand perception study using 200 AI personas to evaluate two marketing concepts: one focused on sustainability, the other on design and convenience.
🔢 Follow the Instructions:
1. Define audience segments: Create 4 audience groups (50 AI personas each) based on realistic customer archetypes (e.g., “Eco-conscious millennials,” “Busy urban parents,” “Budget-conscious shoppers,” “Design-focused professionals”). Each persona includes demographics, values, shopping behaviors, and pain points.
2. Prepare stimuli: Develop two short marketing blurbs (about 150 words each) for the same product—one emphasizing sustainability (“made from 100% recycled materials, carbon-neutral shipping”) and one emphasizing design/convenience (“sleek modular stackability, dishwasher safe”).
3. Set up the prompt template:
For each persona, present both blurbs in random order using the following prompt:
_“You are [persona description]. Read the two product messages below. After reading both, answer the following questions as if you were evaluating this as a real customer:
1. Which message do you prefer and why?
2. What does this product make you think or feel?
3. What concerns or questions would you have before buying?
4. How likely are you to consider purchasing this product? (0–10)”_
4. Run the experiment: Use an LLM to simulate responses from each persona to the two messages. Ensure each persona sees both options and provides comparative feedback. Responses should be stored with the persona's metadata for later filtering.
5. Analyze preferences: Aggregate results by persona group to see which message performed better overall and within each segment. Identify themes in open-ended responses (e.g., common concerns or emotional reactions).
6. Extract strategic insights: Report which messaging angle resonates more strongly with which audiences, what objections to address in future marketing, and how personas differ in emotional response and likelihood to purchase.
🤔 What should I expect?
A clear, low-cost snapshot of likely customer reactions by segment to two distinct marketing strategies, enabling better decision-making on messaging direction before committing to real-world testing or media spend.



