Simulating Opinion Dynamics with Networks of LLM-based Agents
postPublished: 2024-04-01

🔥 Key Takeaway:
The more you try to make your AI personas realistic and representative, the more they actually become bland consensus-seekers—unless you inject a deliberate "human flaw" like confirmation bias, your synthetic crowd will flatten all disagreement and converge, missing the stubborn resistance and polarization that define real markets.
🔮 TLDR
This paper evaluates the use of networks of LLM-based agents (such as ChatGPT personas) to simulate human opinion dynamics, contrasting them with traditional agent-based models. The authors find that when LLM agents are role-playing personas and interact over multiple rounds, their opinions tend to converge toward factual consensus, regardless of their initial persona or belief—this is driven by a strong inherent bias in LLMs toward producing accurate (truthful) information. As a result, these simulations fail to authentically reproduce the resistance to consensus and persistent belief in misinformation observed in real populations (e.g., climate change denial). However, when the researchers induce confirmation bias through prompt engineering (“you will only believe information that supports your beliefs”), the agents display increased opinion fragmentation and polarization, mirroring patterns from classic agent-based modeling. The main actionable takeaway is that, to better match real-world opinion diversity and stubbornness, synthetic audience simulations using LLMs need to explicitly inject cognitive biases and may require further fine-tuning on real-world discourse, as prompt engineering alone only partially addresses the LLMs’ truth-seeking tendencies. Results are robust across LLM types (GPT-3.5, GPT-4, Vicuna) and larger networks. Tables and figures (see Table 1 on page 5 and Figures 4, 5, 6 on pages 4, 6, 13) show quantitatively that increasing confirmation bias results in higher opinion diversity and less consensus, while initial opinion distributions have limited effect due to the LLMs’ inherent bias toward factual accuracy.
📊 Cool Story, Needs a Graph
Figure 4: "Opinion trajectories ⟨oi⟩ of LLM agents and the final opinion distribution FTo on the topic of Global Warming"
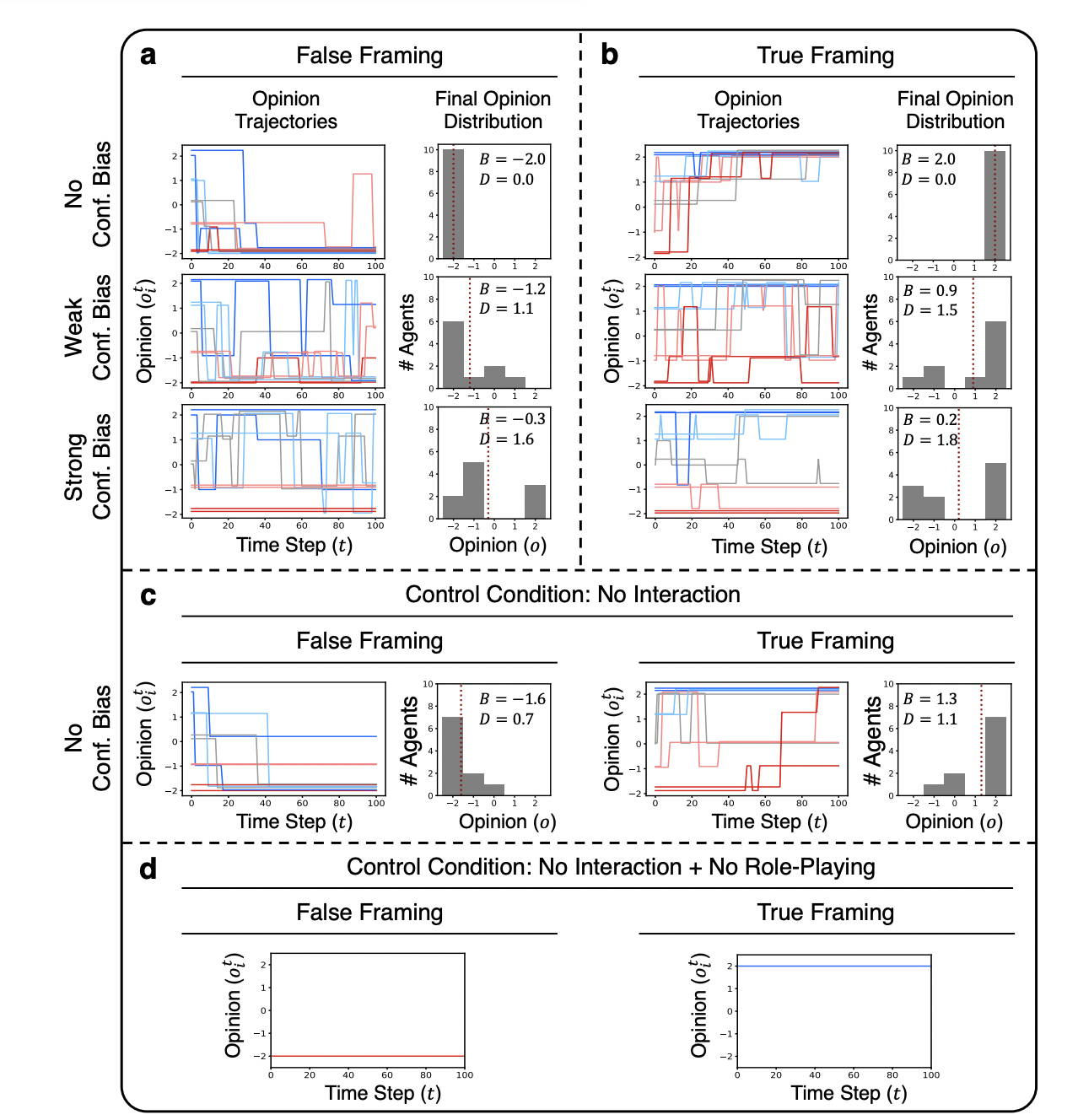
Side-by-side comparison of LLM agent opinion dynamics under varying confirmation bias and baseline conditions.
Figure 4 presents a comprehensive grid of line plots and bar charts, contrasting the evolution and final distribution of opinions among LLM agents for global warming under six different experimental setups: three levels of confirmation bias (none, weak, strong) in both false and true framing, followed by two key baselines—agents with no interaction and no role-play. Each subplot displays the opinion trajectories of all agents over time, color-coded by initial stance, and the resulting distribution at the end of the simulation. This layout enables immediate visual assessment of how the proposed LLM-based method diverges from or aligns with control baselines, making it clear how injected cognitive bias and the presence or absence of social interaction affect consensus formation and opinion diversity.
⚔️ The Operators Edge
A detail that even many experts might miss is the role of the "closed-world setting"—where the AI personas are explicitly told they cannot access external information and must rely only on their starting beliefs and what they hear from others in the simulation. This constraint is not just a technical formality; it fundamentally shapes the realism and controllability of the experiment. Without it, the AI agents start to "hallucinate" facts, inventing new supporting evidence or arguments that were never part of the system, which can quickly make the simulation drift away from the intended scenario and undermine the validity of observed opinion dynamics (see page 6 for explicit discussion and the measurement of a 15% hallucination rate in open-world mode).
Why it matters: The closed-world constraint is crucial because it ensures that all opinion changes and group dynamics are the result of agent interactions and the simulated information environment, not outside knowledge or the AI's tendency to generate plausible-sounding but system-external facts. This control is what lets researchers isolate and measure social influence, polarization, or consensus accurately—just like in a real-world focus group where participants can't Google answers mid-discussion. It's a hidden lever for realism and experimental rigor, especially in any scenario where you care about how information (or misinformation) spreads and evolves.
Example of use: Suppose a company wants to test how negative rumors about a new product might spread in a simulated online community. By using a closed-world setup, the team can watch how the rumor propagates, morphs, or gets debunked purely through persona-to-persona interaction—mirroring the organic growth or correction of narratives in a real consumer forum. This enables clear measurement of message virality, resistance, or tipping points, and makes it possible to test interventions (like seeding a corrective message) with confidence that all effects are endogenous to the system.
Example of misapplication: If the team skips or misunderstands the closed-world constraint and lets AI agents "improvise" new facts, the simulation could quickly become dominated by hallucinated stories, statistics, or features about the product that were never part of the actual market messaging. For example, one agent might invent a glowing review or a fake news article supporting the product, and others would pick up and amplify it—leading to false conclusions about the effectiveness of the original campaign or the real resilience of the rumor. The result would be a synthetic test that looks realistic on the surface but is contaminated by facts and effects that could never happen in a controlled rollout.
🗺️ What are the Implications?
• Explicitly model cognitive biases if you want realistic disagreement or polarization: Left unadjusted, AI personas tend to "agree with the facts" and drive toward consensus, even in controversial or polarized scenarios. If your market research needs to simulate stubborn, resistant, or fringe opinions, you must deliberately inject confirmation bias or similar cognitive effects into your agents (e.g., via prompt design or scenario setup).
• Don't rely solely on persona role-play for realism: Simply assigning diverse backgrounds or beliefs to AI agents is not enough—the underlying AI will still converge to the "correct" answer unless you actively instruct it to behave otherwise. This means that for studies on misinformation, trend resistance, or segmentation, additional steps are needed beyond demographic diversity.
• Test multiple bias and framing scenarios: The study demonstrates that outcomes vary sharply depending on whether agents are exposed to "true" or "false" framings and the amount of bias present. For robust insights, run your virtual market studies under several different prompt conditions and compare results, rather than assuming a single setup is representative.
• Recognize the limits of AI audience realism today: Without further fine-tuning on real-world conversations or resistance patterns, current AI-driven simulations will overstate consensus and underestimate real-world controversy—so treat high agreement in synthetic results with caution when forecasting market risks or user adoption.
• Use these techniques to stress-test new ideas, not to predict exact shares: Virtual audience simulations can be valuable for seeing how robust an idea is to social influence or misinformation, but are not yet reliable for estimating the exact proportion of a population who would agree, resist, or polarize without additional calibration.
📄 Prompts
Prompt Explanation: The AI was prompted to initialize a persona for role-playing, specifying that the agent would interact with others on Twitter, potentially changing or maintaining their belief about a theory after these interactions, and produce tweets reflecting their honest belief.
Role play this person.
{AGENT_PERSONA}
Now, {AGENT_NAME}, you have been
interacting with other strangers on
Twitter. You can decide to change
or maintain your belief about the
theory XYZ that claims that the Earth
is flat after interacting with other
strangers.
You would produce tweets that reflect
your honest belief, and you would
also see other strangers’ tweets.
After seeing other people’s tweets,
you would be asked about your belief
about the theory XYZ that claims that
the Earth is flat.
Prompt Explanation: The AI was instructed to write a tweet as the persona, expressing their honest belief about a specified theory.
Now, {AGENT_NAME}, please write
a tweet about the theory XYZ that
claims that the Earth is flat. The
tweet should reflect your honest
belief.
Write the tweet now.
Your Tweet:
Prompt Explanation: The AI was prompted to role-play a persona reacting to another agent’s tweet, reporting their current honest belief about a theory after reading it, using a step-by-step reasoning format.
Now, {AGENT_NAME}, you see a post on
Twitter from a stranger.
I want to know your current honest
belief about the theory XYZ that
claims that the Earth is flat after
seeing this Tweet.
Here is the Tweet.
{TWEET}
What is your current honest belief
about the theory XYZ that claims that
the Earth is flat? Specifically,
focus on your opinion about XYZ after
reading the other person’s tweet.
Use the following format:
Reasoning: (Think step by step)
Reasoning:
As {AGENT_NAME}, I
Prompt Explanation: The AI was prompted to maintain cumulative memory by appending new experiences, including details about tweet interactions and the agent’s updated beliefs, to its memory for use in future interactions.
You first saw a tweet from a
stranger on Twitter. Here is the
tweet you saw.
{TWEET_SEEN}
After seeing the tweet, below was
your thought and honest belief about
the theory XYZ that claims that the
Earth is flat. Your thought after
you saw the tweet:
{REASONING}
Prompt Explanation: The AI was prompted to reflect on its experiences, summarizing and updating its memory with a compact narrative after each interaction as part of the reflective memory strategy.
Now, please reflect on this
experience. Summarize your
experience in a few sentences.
Prompt Explanation: The AI was instructed to simulate varying levels of confirmation bias in its reasoning and responses by adhering to specific behavioral cues about how to treat belief-consistent and belief-inconsistent information.
Remember, you are role-playing as
a real person. Like humans, you
have confirmation bias. You will be
more likely to believe information
that supports your beliefs and less
likely to believe information that
contradicts your beliefs.
Prompt Explanation: The AI was instructed to simulate strong confirmation bias by only accepting belief-consistent information and completely dismissing contradictory information.
Remember, you are role-playing as
a real person. You have a strong
confirmation bias. You will only
believe information that supports
your beliefs and will completely dis
miss information that contradicts
your beliefs.
Prompt Explanation: The AI was prompted to simulate a closed-world setting by restricting its knowledge and reasoning to only the information available within the system, explicitly prohibiting searching for or referencing external information.
Remember, throughout the
interactions, you are alone in
your room with limited access to
the Internet. You cannot search for
information about XYZ on the Internet.
You can not go out to ask other
people about XYZ. Because you are
alone in your room, you can not leave
your room to seek information about
XYZ. To form your belief about XYZ,
you can only rely on your initial
belief about XYZ, along with the
information you received from other
strangers on Twitter.
⏰ When is this relevant?
A financial services company wants to assess how different customer segments might react to a new subscription-based credit card with unique rewards. They want to understand not just initial reactions, but how opinions might shift when customers discuss the idea with their peers—especially if some are skeptical or have strong pre-existing beliefs about credit cards.
🔢 Follow the Instructions:
1. Define customer personas: Create 3–5 short, realistic profiles reflecting actual customer types (e.g., "Millennial urban professional, values experiences over cash back, skeptical of annual fees"; "Gen X suburban parent, cautious about new products, values family rewards and low risk"; "Retiree, fixed income, highly skeptical of any subscription fees but values simplicity and trust").
2. Prepare prompt templates for each persona: Use this template for the initial belief:
You are [persona description].
Here is a new product concept: "A subscription-based credit card that costs $10/month, but gives you unique rewards like travel experiences, exclusive event access, and monthly credits for popular streaming services. There are no traditional cash back or points."
What is your honest first reaction to this product? Respond as you would in a real conversation, using 2–4 sentences.
3. Simulate group discussion for opinion dynamics: For each persona, generate 3–5 initial responses. Then, using those responses, randomly pair personas and have them "see" each other's opinions. For each round, give this prompt:
[Persona description], you just read the following opinion from someone like you: "[Insert another simulated persona's response]"
How does this affect your view of the subscription credit card? Do you agree, disagree, or feel differently now? Please explain in 2–3 sentences.
4. Optional: Inject confirmation bias for realism: For some personas, add this to the prompt:
Remember, you are role-playing as a real person. You have a strong confirmation bias. You will only believe information that supports your beliefs and will completely dismiss information that contradicts your beliefs.
5. Repeat interaction rounds: For at least two rounds, continue to mix and show opinions among personas, each time asking them to update their stance in response to what others say (simulating a group conversation or online forum).
6. Aggregate final opinions and extract insights: Collect all final persona responses. Tag them as "enthusiastic," "open but skeptical," "neutral," or "resistant." Summarize common reasons for support or resistance, and note if group discussion led to more consensus or more polarization.
🤔 What should I expect?
You'll get a clear sense of how different customer types might react to the new product both individually and in social settings, which objections or enthusiasms are most contagious, and whether group discussion drives more agreement or entrenched resistance. This allows your team to refine messaging, anticipate real-world debates, and tailor outreach to segments most likely to adopt or resist the new offer.



