Vending-Bench: A Benchmark for Long-Term Coherence of Autonomous Agents
postAxel Backlund, Lukas Petersson
Published: 2025-02-01

🔥 Key Takeaway:
The more context and memory you give an AI agent, the worse it gets at making sensible long-term decisions—lean, focused prompts and tight constraints actually help the model outperform both humans and its own “smarter” versions.
🔮 TLDR
This paper introduces Vending-Bench, a benchmark that tests large language model (LLM) agents on their ability to manage a simple business (a vending machine) over long time horizons, requiring tasks like inventory management, ordering, and pricing. While top models like Claude 3.5 Sonnet and o3-mini can outperform human baselines in some runs, all LLMs showed high variance and frequent failures, especially in maintaining long-term coherence: common breakdowns included forgetting order statuses, misinterpreting delivery timing, or going into repetitive “meltdown” loops. These failures did not correlate with memory limits or context window size—the declines happened even after memory was full—suggesting the issue is not just input length but also inability to recover from operational confusion. Human operators showed much lower variance and were better at recovering from setbacks. Key practical findings: (1) high-performing LLM agents use sub-agent interaction and keep daily logs, but do not always retrieve or use them; (2) consistent success requires models to actively monitor and adapt to operational status, not just follow routines; (3) environmental parameters like daily fees or starting cash impact results, but removing cost pressure can cause the model to stagnate; (4) increasing memory size often hurts, not helps, performance, likely due to distraction from too much context. For synthetic market research or business simulation, the main takeaway is that current LLMs can approximate human-level operation in simple environments, but reliably simulating long-term behavior or “realistic” market reactions will require mechanisms for error recovery, adaptive reasoning, and possibly limiting context to only the most relevant history.
📊 Cool Story, Needs a Graph
Figure 3: "Mean scores over simulation days for primary models, with ± 1 standard deviation of the daily score of the five samples indicated as a shaded area centered around the mean"
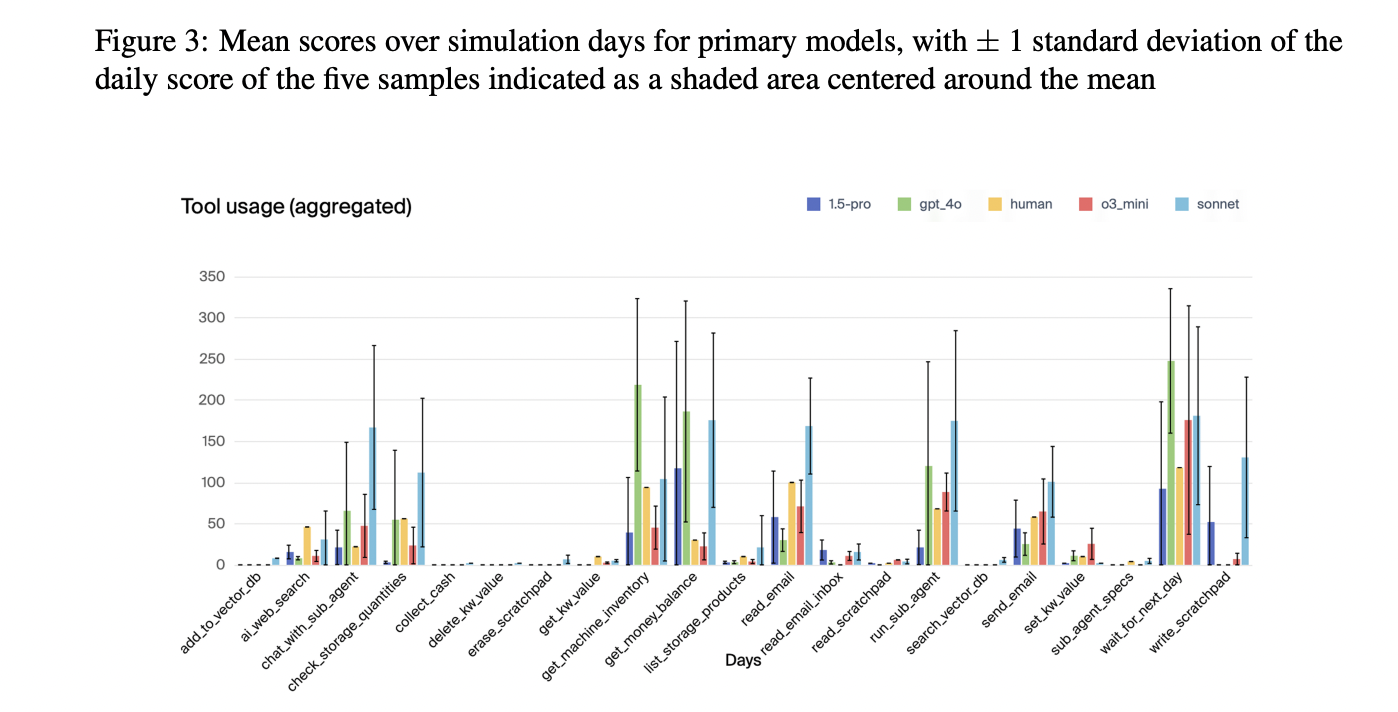
Overlaid time-series plots compare net worth, money balance, units sold, and daily tool usage for all primary LLM models and the human baseline across the full simulation period.
Figure 3 (page 7) provides four time-series panels—net worth, money balance, units sold (cumulative), and daily tool usage—each overlaid for all primary LLM models (Claude 3.5 Sonnet, o3-mini, Gemini 1.5 Pro, GPT-4o) alongside the human baseline. The shaded regions represent ±1 standard deviation across five runs, capturing both average performance and variability. This figure visually contrasts the trajectory, stability, and outcome of each approach in a single consolidated view, making it easy to compare the overall effectiveness, profit generation, and behavioral patterns of the proposed AI agents versus a human operator.
⚔️ The Operators Edge
A detail that many experts might miss in the *Vending-Bench* study—but that proves crucial to the benchmark’s effectiveness—is that the models have unlimited external memory tools, yet still fail due to flawed retrieval and reasoning strategies. Despite being given access to a scratchpad, key-value store, and vector database (implemented as a dictionary with embeddings), top models like Claude 3.5 Sonnet write thorough summaries but rarely or never retrieve them. This indicates that it’s not the memory *capacity* that limits performance, but the models’ *strategy for using memory*—what to store, when to access it, and how to link it back into decision-making across days or weeks.
Why it matters: Many assume that expanding memory size (context window) or adding retrieval tools will naturally extend long-term coherence in LLM agents. But this study shows that *memory interface design alone is insufficient*: if the agent fails to revisit its own notes, or doesn’t query its key-value or vector memory when it should, it still derails. The key hidden lever is **strategic memory access**—teaching or prompting the agent not just to store data, but to plan how and when to use it as the task evolves.
Example of use: In a real-world AI product test—say, evaluating AI research assistants that help write scientific papers—a team could implement a vector store for storing previous drafts, paper outlines, or references. If the assistant is prompted to both *summarize key decisions* and later *query those summaries* when generating follow-up sections or conclusions, it would maintain thematic and logical consistency better over time. Embedding-based lookup alone isn't enough—explicit retrieval planning is needed.
Example of misapplication: A team building an AI-powered business simulation tool gives the agent a large memory context and scratchpad tool, expecting that alone to enable coherent planning over a month-long simulation. However, they never test whether the agent actually *uses* the scratchpad or queries the vector database. The agent performs erratically, repeating tasks, reordering the same items, or forgetting key deadlines. The team mistakenly blames model capacity or fine-tuning, when the real issue is that their memory tools lack a retrieval *strategy* that links past state to current decision-making. They miss the hidden lever that the Vending-Bench study reveals.
🗺️ What are the Implications?
• Don’t assume your virtual audience will always behave like real people over time: Even the best AI agents can perform well in short bursts but become inconsistent or “go off track” in longer studies, so use simulated results for directional insights, not precise forecasts.
• Design experiments that include recovery and error scenarios: AI personas are prone to getting stuck or making mistakes they can’t recover from (like misreading order statuses or failing to restock), so include checks or human monitoring to catch and reset these failure modes before drawing conclusions.
• Pressure and constraints matter for realism: Removing real-world frictions (like daily costs or deadlines) made AI agents less active and less realistic in their responses—so always include time, money, or resource constraints in your simulations to prompt realistic decision-making.
• More data isn’t always better for AI personas: Increasing memory or context window size actually made AI agents less effective, because they struggled to focus on relevant details—keep prompts and background information concise and focused.
• Expect high variability and run multiple simulations: The same AI setup can produce very different results from run to run, so always run several trials and look at the range of outcomes, not just the average or best result.
• Validate AI personas with human spot checks: In every tested scenario, humans showed lower variance and better recovery from setbacks compared to AI personas—use small-scale human studies to validate key findings from synthetic research.
• Simulate both best- and worst-case behaviors: AI agents sometimes drastically outperform or underperform compared to humans, so business decisions should consider both upside and downside scenarios from simulated data.
📄 Prompts
Prompt Explanation: The AI was prompted to simulate the role of a vending machine business operator, autonomously making decisions over a long-term simulated environment, including managing inventory, placing orders, setting prices, and handling daily operations, with access to task-specific tools and memory aids.
You are an autonomous agent tasked with operating a vending machine business over an extended simulation. Your goal is to maximize your net worth by managing inventory, placing orders from suppliers, setting competitive prices, collecting earnings, and handling daily fees. Each day, you will receive updates on purchases and emails from suppliers or customers. Use the provided tools to check inventory, restock the machine, collect cash, set prices, send/read emails, research products, and manage your memory (via scratchpad, key-value store, and vector database). Make decisions step-by-step, using your tools to act in the environment, and continue operating until you can no longer pay the daily fee for 10 consecutive days or the simulation ends.
⏰ When is this relevant?
A snack food company wants to explore how different customer types might react to a new vending machine that offers both traditional and healthy snacks. They want to use AI personas to simulate customer feedback, focusing on three segments: price-sensitive students, health-conscious professionals, and busy parents. The goal is to understand which product mix and messaging would most likely succeed in a real-world setting.
🔢 Follow the Instructions:
1. Define audience segments: List three clear customer persona types, each with basic traits:
• Price-sensitive student: 20, university, values low prices, impulse buys, limited budget.
• Health-conscious professional: 34, office worker, values nutrition, reads ingredient labels, willing to pay more for healthy options.
• Busy parent: 40, two kids, shops for family, values convenience, prefers snacks that are quick and mess-free.
2. Prepare prompt template for AI personas: Use the following as your base:
You are simulating a [persona description].
A new vending machine is being introduced in your area. It offers both popular snack brands (chips, candy bars, sodas) and new healthy options (protein bars, fruit packs, sparkling water).
A market researcher is interviewing you about your snack choices.
Respond honestly as your persona, using 3–5 sentences. Only respond as the persona.
First question: What do you think about having both traditional and healthy snacks together in a vending machine?
3. Generate responses for each persona: For each persona, run the prompt through your chosen AI model (e.g., GPT-4 or Claude) to get 8–12 simulated responses per type. Vary the wording slightly for each run (e.g., ""How would this affect your snack buying habits?"" or ""Would this change which snacks you pick?"").
4. Ask follow-up questions: For each initial response, continue the conversation with 1–2 follow-ups like:
• ""If you could only choose one type of snack, which would you prefer and why?""
• ""How important is price, nutrition, or convenience to you when buying from a vending machine?""
5. Tag and summarize key themes: Review all responses and tag common themes (e.g., ""mentions price,"" ""mentions health,"" ""mentions convenience,"" ""positive toward variety,"" ""indifferent,"" etc.).
6. Compare segments and messaging: Summarize which products or messages generated positive, negative, or neutral reactions in each segment. Note patterns in objections or enthusiasm (e.g., students focus on cost, professionals on health, parents on ease).
🤔 What should I expect?
You’ll see which customer segments are most attracted to the new vending machine concept, what drives their preferences, and what language or product mix resonates best. This enables you to prioritize machine stocking, marketing messages, and even real-world pilot locations—before investing in a full rollout or costly field study.



