Back to n8n Workflows
 Rhys Fisher
Rhys Fisher
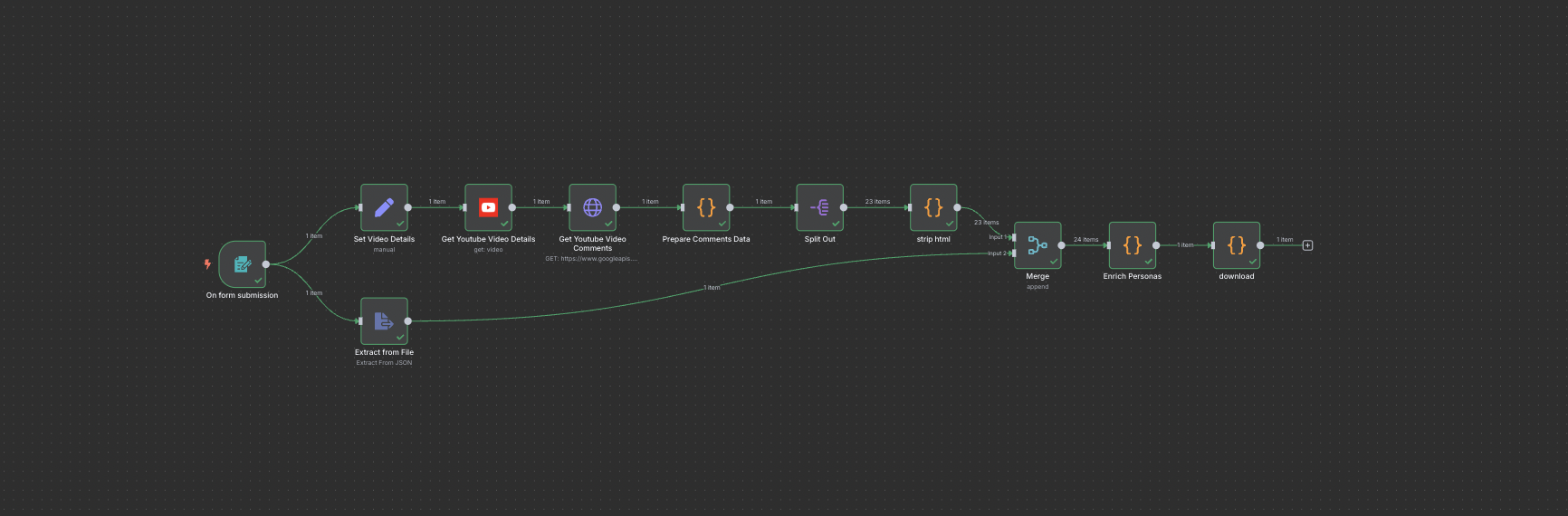

Enrich Audience With YouTube Comments
Rhys Fisher
Extract 100 Youtube comments from a target video and enrich your desired audience of AI personas with memories of these comments. Simply paste a YouTube Video ID and upload an audience json, then download the finished JSON with enriched personas ready to upload into AskRally.
Click to expand
Summarize in
OR
Summarize in
OR
🚀 n8n Workflow Template
{
"active": false,
"connections": {
"Enrich Personas": {
"main": [
[
{
"index": 0,
"node": "download",
"type": "main"
}
]
]
},
"Extract from File": {
"main": [
[
{
"index": 1,
"node": "Merge",
"type": "main"
}
]
]
},
"Get Youtube Video Comments": {
"main": [
[
{
"index": 0,
"node": "Prepare Comments Data",
"type": "main"
}
]
]
},
"Get Youtube Video Details": {
"main": [
[
{
"index": 0,
"node": "Get Youtube Video Comments",
"type": "main"
}
]
]
},
"Merge": {
"main": [
[
{
"index": 0,
"node": "Enrich Personas",
"type": "main"
}
]
]
},
"On form submission": {
"main": [
[
{
"index": 0,
"node": "Set Video Details",
"type": "main"
},
{
"index": 0,
"node": "Extract from File",
"type": "main"
}
]
]
},
"Prepare Comments Data": {
"main": [
[
{
"index": 0,
"node": "Split Out",
"type": "main"
}
]
]
},
"Set Video Details": {
"main": [
[
{
"index": 0,
"node": "Get Youtube Video Details",
"type": "main"
}
]
]
},
"Split Out": {
"main": [
[
{
"index": 0,
"node": "strip html",
"type": "main"
}
]
]
},
"download": {
"main": [
[]
]
},
"strip html": {
"main": [
[
{
"index": 0,
"node": "Merge",
"type": "main"
}
]
]
}
},
"id": "eVISRYTdVwa5FK4w",
"meta": {
"instanceId": "7921b3cd29c1121b3ec4f2177acf06fe1f1325838297f593db7db4e9563eb98d"
},
"name": "Enrich Audience With YouTube comments",
"nodes": [
{
"id": "777461be-9a36-4af4-a17c-4bdd8f94d92a",
"name": "Set Video Details",
"notes": "Prepares video ID and sets max comments limit (100)",
"parameters": {
"assignments": {
"assignments": [
{
"id": "219795ef-daa4-4444-9865-c5d3856be63b",
"name": "videoId",
"type": "string",
"value": "={{ $json[\u0027Youtube Video ID\u0027] }}"
},
{
"id": "cd4f519d-4c84-496c-8974-29ef69c890fc",
"name": "maxComments ",
"type": "number",
"value": 100
}
]
},
"options": {}
},
"position": [
320,
120
],
"type": "n8n-nodes-base.set",
"typeVersion": 3.4
},
{
"credentials": {
"youTubeOAuth2Api": {
"id": "HLjrqi36xLQPdjoE",
"name": "YouTube account"
}
},
"id": "667a1875-186e-44d9-bd32-692e5703acd8",
"name": "Get Youtube Video Details",
"notes": "Fetches video metadata including title, channel name, and other details",
"parameters": {
"operation": "get",
"options": {},
"resource": "video",
"videoId": "={{ $json.videoId }}"
},
"position": [
540,
120
],
"type": "n8n-nodes-base.youTube",
"typeVersion": 1
},
{
"credentials": {
"youTubeOAuth2Api": {
"id": "HLjrqi36xLQPdjoE",
"name": "YouTube account"
}
},
"id": "c13a5085-fd1e-49eb-a734-a8a2b0ef49d3",
"name": "Get Youtube Video Comments",
"notes": "Retrieves top 100 comments ordered by relevance using YouTube API",
"parameters": {
"authentication": "predefinedCredentialType",
"nodeCredentialType": "youTubeOAuth2Api",
"options": {},
"queryParameters": {
"parameters": [
{
"name": "part",
"value": "snippet"
},
{
"name": "videoId",
"value": "={{ $(\u0027Set Video Details\u0027).item.json.videoId }}"
},
{
"name": "maxResults",
"value": "100"
},
{
"name": "order",
"value": "relevance"
}
]
},
"sendQuery": true,
"url": "https://www.googleapis.com/youtube/v3/commentThreads"
},
"position": [
760,
120
],
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2
},
{
"id": "6d28fe77-91e0-40f0-b1fe-c025b452b19d",
"name": "Prepare Comments Data",
"notes": "Processes raw comments: extracts text, calculates stats, performs basic sentiment analysis, limits to 50 comments for AI",
"parameters": {
"jsCode": "// Get comments from HTTP Request node\nconst comments = $input.first().json.items\n//const comments = response.items || [];\n\n// Get video title from the YouTube node (step 5)\n//const videoData = ;\nconst videoTitle = $(\u0027Get Youtube Video Details\u0027).first().json.snippet.title;\n\n// Extract comment data\nconst processedComments = comments.map(item =\u003e {\n const comment = item.snippet.topLevelComment.snippet;\n return {\n text: comment.textDisplay,\n author: comment.authorDisplayName,\n likes: comment.likeCount || 0,\n publishedAt: comment.publishedAt,\n replyCount: item.snippet.totalReplyCount || 0\n };\n});\n\n// Calculate statistics\nconst totalComments = processedComments.length;\nconst totalLikes = processedComments.reduce((sum, c) =\u003e sum + c.likes, 0);\nconst avgLikes = totalComments \u003e 0 ? (totalLikes / totalComments).toFixed(2) : 0;\nconst totalReplies = processedComments.reduce((sum, c) =\u003e sum + c.replyCount, 0);\n\n// Get top comments by likes\nconst topComments = processedComments\n .sort((a, b) =\u003e b.likes - a.likes)\n .slice(0, 5);\n\n// Prepare comment texts for AI analysis\nconst commentTexts = processedComments\n .slice(0, 50) // Limit to 50 comments for AI analysis\n .map(c =\u003e c.text)\n .join(\u0027\\n---\\n\u0027);\n\n// Basic sentiment analysis (count positive/negative keywords)\nconst positiveWords = [\u0027love\u0027, \u0027great\u0027, \u0027awesome\u0027, \u0027amazing\u0027, \u0027excellent\u0027, \u0027good\u0027, \u0027fantastic\u0027, \u0027helpful\u0027, \u0027thanks\u0027];\nconst negativeWords = [\u0027hate\u0027, \u0027terrible\u0027, \u0027awful\u0027, \u0027bad\u0027, \u0027worst\u0027, \u0027horrible\u0027, \u0027useless\u0027, \u0027waste\u0027];\n\nlet positiveCount = 0;\nlet negativeCount = 0;\n\nprocessedComments.forEach(comment =\u003e {\n const lowerText = comment.text.toLowerCase();\n positiveWords.forEach(word =\u003e {\n if (lowerText.includes(word)) positiveCount++;\n });\n negativeWords.forEach(word =\u003e {\n if (lowerText.includes(word)) negativeCount++;\n });\n});\n\nreturn [{\n json: {\n videoTitle,\n totalComments,\n avgLikes,\n totalReplies,\n topComments,\n commentTexts,\n processedComments,\n sentimentCounts: {\n positive: positiveCount,\n negative: negativeCount,\n neutral: totalComments - positiveCount - negativeCount\n }\n }\n}];\n\n"
},
"position": [
1000,
120
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "e4213434-8341-4a35-98cf-29170d3c87d9",
"name": "On form submission",
"parameters": {
"formDescription": "We\u0027ll enrich your audience with comments from Youtube.",
"formFields": {
"values": [
{
"fieldLabel": "Youtube Video ID"
},
{
"acceptFileTypes": ".json",
"fieldLabel": "Audience JSON",
"fieldType": "file",
"multipleFiles": false
}
]
},
"formTitle": "Enrich Audience With Youtube Comments",
"options": {}
},
"position": [
20,
240
],
"type": "n8n-nodes-base.formTrigger",
"typeVersion": 2.2,
"webhookId": "edac4171-af91-488b-acd6-abd3158ad53a"
},
{
"id": "193d8da3-bf90-4b6f-a756-0b37a28e6108",
"name": "Split Out",
"parameters": {
"fieldToSplitOut": "processedComments",
"options": {
"destinationFieldName": "="
}
},
"position": [
1240,
120
],
"type": "n8n-nodes-base.splitOut",
"typeVersion": 1
},
{
"id": "c8c48890-75e3-4b7f-9110-a5b324fdf9f4",
"name": "strip html",
"parameters": {
"jsCode": "const decode = html =\u003e {\n return html\n .replace(/\u0026quot;/g, \u0027\"\u0027)\n .replace(/\u0026#39;/g, \"\u0027\")\n .replace(/\u0026amp;/g, \u0027\u0026\u0027)\n .replace(/\u0026lt;/g, \u0027\u003c\u0027)\n .replace(/\u0026gt;/g, \u0027\u003e\u0027)\n .replace(/\u003cbr\\s*\\/?\u003e/gi, \u0027\\n\u0027) // convert \u003cbr\u003e to newlines\n .replace(/\u003c[^\u003e]*\u003e/g, \u0027\u0027) // remove all remaining HTML tags\n .trim();\n};\n\nreturn items.map(item =\u003e {\n const cleanText = decode(item.json.text);\n return {\n json: {\n ...item.json,\n text: cleanText // or put it in a new field like `clean`\n }\n };\n});\n"
},
"position": [
1480,
120
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "7f114c0a-12a2-468c-9afc-078fc18fbedb",
"name": "Extract from File",
"parameters": {
"binaryPropertyName": "=Audience_JSON",
"destinationKey": "audienceData",
"operation": "fromJson",
"options": {}
},
"position": [
320,
360
],
"type": "n8n-nodes-base.extractFromFile",
"typeVersion": 1
},
{
"id": "b31657d2-a8ad-450c-8051-353bc4d8a80b",
"name": "Merge",
"parameters": {},
"position": [
1700,
200
],
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2
},
{
"id": "b7bb9b61-d708-4c35-8322-475f50e0d2f7",
"name": "Enrich Personas",
"parameters": {
"jsCode": "const allInputs = $input.all();\n\n// Pull the audience item (should have .audienceData)\nconst audienceItem = allInputs.find(item =\u003e item.json?.audienceData);\n\nif (!audienceItem) {\n throw new Error(\"Audience JSON not found in inputs.\");\n}\n\nconst personas = audienceItem.json.audienceData.personas || [];\n\n// Pull comment texts from other items\nconst commentTexts = allInputs\n .filter(item =\u003e item.json?.text)\n .map(item =\u003e item.json.text)\n .filter(Boolean);\n\n// Fallback comment\nconst fallback = \"No comment available\";\n\n// Merge comments into personas by appending to background\nconst updatedPersonas = personas.map((persona, index) =\u003e {\n const comment = commentTexts[index % commentTexts.length] || fallback;\n const background = persona.background?.trim() || \"\";\n const endsWithPunct = /[.!?]$/.test(background);\n const formattedBackground = endsWithPunct ? background : background + \".\";\n const appended = `\\n\\n#Memories\\nYour YouTube video reply: ${comment}`;\n return {\n ...persona,\n background: formattedBackground + appended\n };\n});\n\n// \u2705 Correct output structure\nreturn {\n name: audienceItem.json.audienceData.name,\n description: audienceItem.json.audienceData.description,\n personas: updatedPersonas\n};\n\n"
},
"position": [
1900,
200
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "76d0d26f-bd5d-42e6-8bda-eafb4add29ce",
"name": "download",
"parameters": {
"jsCode": "// n8n always wraps items in an array, so grab the first one\nconst data = items[0].json;\n\n// Convert to JSON string and return as binary buffer\nconst filename = \u0027personas.json\u0027;\n\nreturn [\n {\n binary: {\n data: {\n data: Buffer.from(JSON.stringify(data, null, 2)).toString(\u0027base64\u0027),\n mimeType: \u0027application/json\u0027,\n fileName: filename\n }\n }\n }\n];\n"
},
"position": [
2120,
200
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
}
],
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"tags": [],
"versionId": "339f3cc0-2114-474c-8c5a-8bd16f36ffdc"
}About the Author
Rhys Fisher
Rhys Fisher is the COO & Co-Founder of Rally. He previously co-founded a boutique analytics agency called Unvanity, crossed the Pyrenees coast-to-coast via paraglider, and now watches virtual crowds respond to memes. Follow him on Twitter @virtual_rf
