Turn real-time Google Alert RSS feeds into on-brand meme concepts—in minutes. The workflow pulls in every new article, simulates buyer reaction via AI-persona voting, find hidden insights, ideates a meme to drive commercial value, generates 8 variants, simulates engagements, and send a winning meme into your inbox so you can ride narrative trends with humor before anyone else.
Back to n8n Workflows
 Rhys Fisher
Rhys Fisher
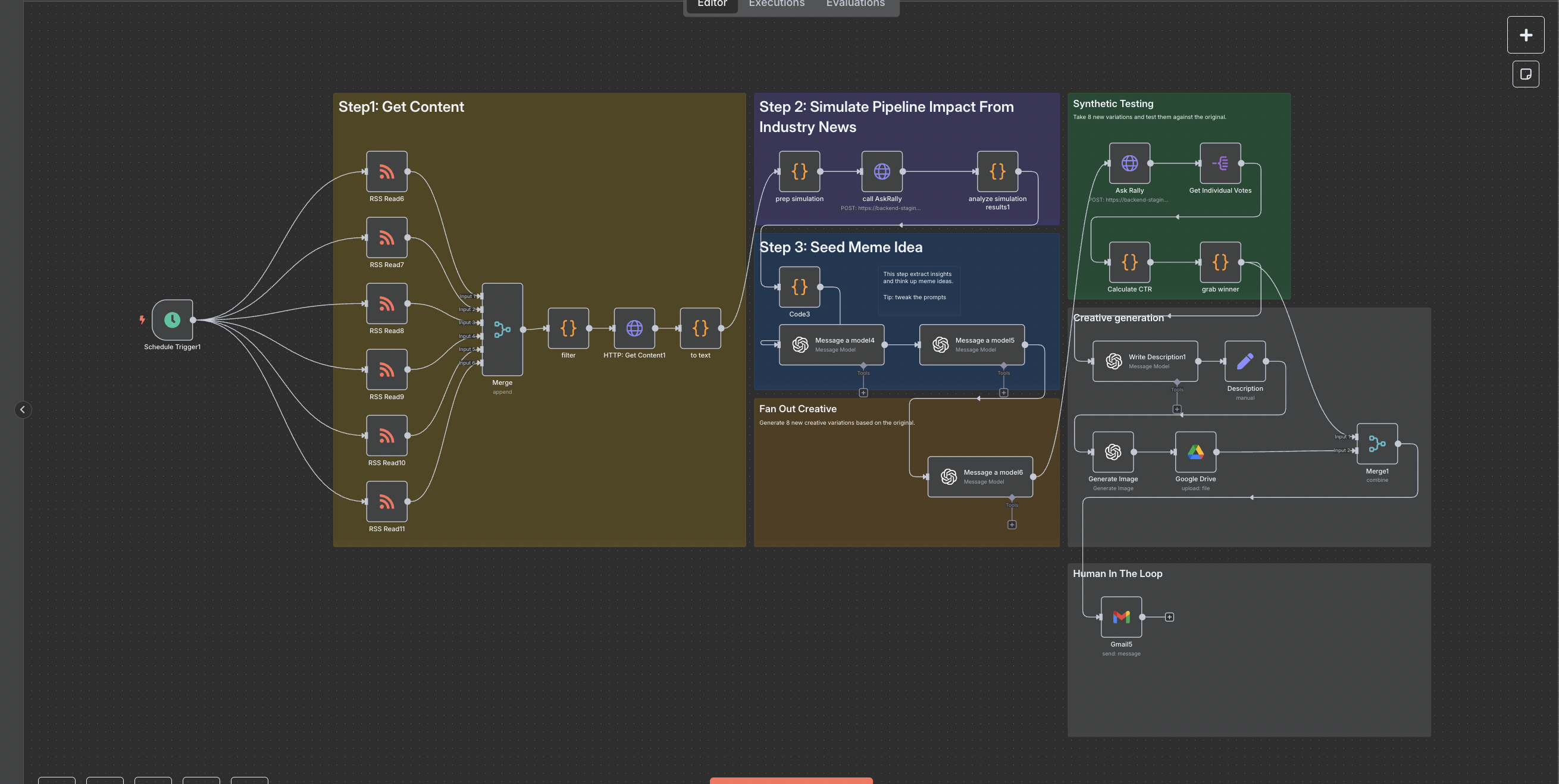

RSS Feed To Image Meme Machine (NEEDS UPDATE)
Rhys Fisher
Automatically pull RSS feed from industry news and simulates impact on pipeline. Then runs automated insight extraction to creative meme engagement testing. The winning variant is delivered to your inbox every morning.
Click to expand
Summarize in
OR
Summarize in
OR
Overview
🎯 Pro Tips & Secret Sauce
🎯 Secret Sauce: Gain-of-Function Creative Engine
Just like biological gain-of-function experiments unlock new abilities, this workflow supercharges your meme pipeline by layering capabilities at each stage—so you go from raw headlines to crowd-proven humor in minutes:
-
Live Feed → Focused Exposure
Every Google Alert RSS hit becomes immediate “nutrition” for your creative engine. No stale batch pulls—this is real-time injection of fresh narrative signals. -
AI-Persona Voting → Hidden Insight Extraction
Instead of broad metrics, you simulate how distinct buyer archetypes react. That “hidden receptor” in your messaging shows up only when you test against diverse personas, revealing subtle motifs you’d never spot in vanilla sentiment scores. -
Meme Ideation → Explosive Variant Generation
One core meme concept seeds eight high-energy offshoots. Think of it as “genetic editing” on your creative DNA—each variant tweaks tone, style, or angle to hit different humor receptors. -
Synthetic Engagement Testing → Rapid Evolution
By simulating click-throughs and reactions, you quickly “select” the fittest meme. It’s survival-of-the-funniest in a matter of minutes, not weeks of real-world trials. -
Automated Delivery → Instant Activation
The ultimate gain-of-function: your winning meme lands in your inbox (or any playbook) ready to deploy. You’re no longer chasing trends—you’re setting them, with a feedback loop that continuously refines itself.
📝 Step-by-Step Instructions
-
Import the Workflow
-
Copy & paste the JSON template into your n8n instance via “Import from Clipboard”.
-
-
Configure Rally API Calls, Audience ID, and Add your Product Category
-
In both “call AskRally” HTTP Request nodes, set your Rally API endpoint URL.
-
Attach your Rally bearer-token credential to each.
- Open the “prep simulation” code node and tweak the OpenAI query so it asks about your category instead of “synthetic research.”
- Swap the refrence to an audience ID to your audience ID
-
-
Add Your RSS Feeds
-
Replace the placeholder URLs in each “RSS Read” node with your own Google Alert (or other) RSS links.
-
-
Enable Google Drive & Gmail OAuth
-
In the “Google Drive” node, select/authorize your Drive OAuth credential.
-
In the “Gmail” node, select/authorize your Gmail OAuth credential.
-
-
Activate & Test
-
Turn on the workflow, trigger it manually (or wait for the schedule), and confirm you receive the winning meme email.
-
📋 Requirements
Integrations
-
Rally API – AI-persona testing service for simulating audience reactions
-
Google Alerts RSS – your topic-specific feed URLs
-
OpenAI – for both persona simulation and image generation
-
Google Drive – to stash generated images (optional but recommended)
-
Gmail – to email winning memes
Credentials
-
Rally API Bearer Token (with voting-mode access)
-
OpenAI API Key
-
Google Drive OAuth2
-
Gmail OAuth2
Prerequisites
-
An n8n instance (self-hosted or cloud) with HTTP Request, RSS Read, Code, and OAuth2 nodes installed
-
Active Rally account with configured audience personas
-
Google Alerts feeds created for your keywords
-
(Optional) A Google Drive folder where you’d like memes saved
-
(Optional) A Gmail address to receive the winning meme email
🚀 n8n Workflow Template
{
"active": true,
"connections": {
"Ask Rally": {
"main": [
[
{
"index": 0,
"node": "Get Individual Votes",
"type": "main"
}
]
]
},
"Calculate CTR": {
"main": [
[
{
"index": 0,
"node": "grab winner",
"type": "main"
}
]
]
},
"Code3": {
"main": [
[
{
"index": 0,
"node": "Message a model4",
"type": "main"
}
]
]
},
"Description": {
"main": [
[
{
"index": 0,
"node": "Generate Image",
"type": "main"
}
]
]
},
"Generate Image": {
"main": [
[
{
"index": 0,
"node": "Google Drive",
"type": "main"
}
]
]
},
"Get Individual Votes": {
"main": [
[
{
"index": 0,
"node": "Calculate CTR",
"type": "main"
}
]
]
},
"Google Drive": {
"main": [
[
{
"index": 1,
"node": "Merge1",
"type": "main"
}
]
]
},
"HTTP: Get Content1": {
"main": [
[
{
"index": 0,
"node": "to text",
"type": "main"
}
]
]
},
"Merge": {
"main": [
[
{
"index": 0,
"node": "filter",
"type": "main"
}
]
]
},
"Merge1": {
"main": [
[
{
"index": 0,
"node": "Gmail5",
"type": "main"
}
]
]
},
"Message a model4": {
"main": [
[
{
"index": 0,
"node": "Message a model5",
"type": "main"
}
]
]
},
"Message a model5": {
"main": [
[
{
"index": 0,
"node": "Message a model6",
"type": "main"
}
]
]
},
"Message a model6": {
"main": [
[
{
"index": 0,
"node": "Ask Rally",
"type": "main"
}
]
]
},
"RSS Read10": {
"main": [
[
{
"index": 4,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read11": {
"main": [
[
{
"index": 5,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read6": {
"main": [
[
{
"index": 0,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read7": {
"main": [
[
{
"index": 1,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read8": {
"main": [
[
{
"index": 2,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read9": {
"main": [
[
{
"index": 3,
"node": "Merge",
"type": "main"
}
]
]
},
"Schedule Trigger1": {
"main": [
[
{
"index": 0,
"node": "RSS Read6",
"type": "main"
},
{
"index": 0,
"node": "RSS Read7",
"type": "main"
},
{
"index": 0,
"node": "RSS Read8",
"type": "main"
},
{
"index": 0,
"node": "RSS Read9",
"type": "main"
},
{
"index": 0,
"node": "RSS Read10",
"type": "main"
},
{
"index": 0,
"node": "RSS Read11",
"type": "main"
}
]
]
},
"Write Description1": {
"main": [
[
{
"index": 0,
"node": "Description",
"type": "main"
}
]
]
},
"analyze simulation results1": {
"main": [
[
{
"index": 0,
"node": "Code3",
"type": "main"
}
]
]
},
"call AskRally": {
"main": [
[
{
"index": 0,
"node": "analyze simulation results1",
"type": "main"
}
]
]
},
"filter": {
"main": [
[
{
"index": 0,
"node": "HTTP: Get Content1",
"type": "main"
}
]
]
},
"grab winner": {
"main": [
[
{
"index": 0,
"node": "Write Description1",
"type": "main"
},
{
"index": 0,
"node": "Merge1",
"type": "main"
}
]
]
},
"prep simulation": {
"main": [
[
{
"index": 0,
"node": "call AskRally",
"type": "main"
}
]
]
},
"to text": {
"main": [
[
{
"index": 0,
"node": "prep simulation",
"type": "main"
}
]
]
}
},
"id": "AmlFLnF17HHUvOC9",
"meta": {
"instanceId": "7921b3cd29c1121b3ec4f2177acf06fe1f1325838297f593db7db4e9563eb98d",
"templateCredsSetupCompleted": true
},
"name": "Meme Machine",
"nodes": [
{
"id": "2e53f82f-5353-4058-b65b-bf17e01fba68",
"name": "filter",
"parameters": {
"jsCode": "// Multi-item deduplication + time filter + URL extraction (FIXED VERSION)\nconst items = $input.all();\nconst hoursThreshold = 24; // 24 hours\nconst now = new Date();\n\nconsole.log(`Processing ${items.length} RSS items for deduplication, filtering, and URL extraction`);\nconsole.log(`Current time: ${now.toISOString()}`);\n\n// Helper functions\nfunction stripTags(str) {\n return (str || \u0027\u0027).replace(/\u003c[^\u003e]+\u003e/g, \u0027\u0027).trim();\n}\n\nfunction normalizeTitle(title) {\n return stripTags(title)\n .replace(/\\s*\u2013.*$/, \u0027\u0027) // Remove \" \u2013 AMI\", \" \u2013 Mi3\" suffixes\n .replace(/\\s*-.*$/, \u0027\u0027) // Remove \" - AMI\", \" - Mi3\" suffixes \n .toLowerCase()\n .trim();\n}\n\nfunction extractCleanUrl(originalUrl) {\n let cleanUrl = originalUrl;\n if (originalUrl \u0026\u0026 originalUrl.includes(\u0027google.com/url\u0027)) {\n const match = originalUrl.match(/[\u0026?]url=([^\u0026]+)/);\n if (match) {\n try {\n cleanUrl = decodeURIComponent(match[1]);\n } catch (error) {\n cleanUrl = originalUrl;\n }\n }\n }\n return cleanUrl;\n}\n\n// Step 1: Time filtering\nconst timeFilteredItems = items.filter((item, index) =\u003e {\n try {\n const pubDate = new Date(item.json.pubDate || item.json.isoDate);\n const ageInHours = (now - pubDate) / (1000 * 60 * 60);\n \n console.log(`Item ${index}: \"${item.json.title}\"`);\n console.log(` Published: ${pubDate.toISOString()}`);\n console.log(` Age: ${ageInHours.toFixed(1)} hours`);\n \n if (ageInHours \u003c= hoursThreshold) {\n console.log(`\u2705 Item ${index} passed time filter`);\n return true;\n } else {\n console.log(`\u274c Item ${index} filtered out (too old)`);\n return false;\n }\n } catch (error) {\n console.log(`\u26a0\ufe0f Error processing item ${index}:`, error.message);\n return false;\n }\n});\n\nconsole.log(`After time filter: ${timeFilteredItems.length} items remaining`);\n\n// Step 2: Process items with URL extraction first, then deduplicate\nconst processedItems = timeFilteredItems.map((item, index) =\u003e {\n const originalUrl = item.json.link;\n const cleanUrl = extractCleanUrl(originalUrl);\n const normalizedTitle = normalizeTitle(item.json.title);\n \n return {\n json: {\n ...item.json,\n cleanUrl: cleanUrl,\n normalizedTitle: normalizedTitle\n }\n };\n});\n\n// Step 3: IMPROVED Deduplication using normalized titles\nconst seenItems = new Set();\nconst deduplicatedItems = processedItems.filter((item, index) =\u003e {\n const uniqueKey = item.json.normalizedTitle; // Just use normalized title for dedup\n \n console.log(`Checking item ${index} for duplicates:`);\n console.log(` Original title: \"${item.json.title}\"`);\n console.log(` Normalized title: \"${item.json.normalizedTitle}\"`);\n console.log(` Clean URL: \"${item.json.cleanUrl}\"`);\n \n if (seenItems.has(uniqueKey)) {\n console.log(`\ud83d\udd04 Duplicate found: \"${item.json.normalizedTitle}\" - removing`);\n return false;\n } else {\n seenItems.add(uniqueKey);\n console.log(`\u2705 Item ${index} is unique - keeping`);\n return true;\n }\n});\n\nconsole.log(`Final result: ${deduplicatedItems.length} items after time filter + dedup + URL extraction`);\nconsole.log(`Items being returned:`, deduplicatedItems.map(item =\u003e item.json.normalizedTitle));\n\n// Return the processed items\nreturn deduplicatedItems;"
},
"position": [
440,
560
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "f7909961-1aa2-4c7a-88e6-82e81ac8a987",
"name": "Merge",
"parameters": {
"numberInputs": 6
},
"position": [
280,
500
],
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2
},
{
"id": "418fd821-b103-4a04-96f9-ddccac146652",
"name": "prep simulation",
"parameters": {
"jsCode": "// Extract content and prepare Rally API payload - Using Clean Text Field\nlet rssData = {};\nlet httpData = {};\nlet toTextData = {};\n\ntry {\n rssData = $(\u0027filter\u0027).item.json || {};\n} catch (e) {\n console.log(\u0027No RSS data accessible:\u0027, e.message);\n}\n\ntry {\n httpData = $(\u0027HTTP: Get Content1\u0027).item.json || {};\n} catch (e) {\n console.log(\u0027No HTTP data accessible:\u0027, e.message);\n}\n\ntry {\n toTextData = $(\u0027to text\u0027).item.json || {};\n} catch (e) {\n console.log(\u0027No \u201cto text\u201d data accessible:\u0027, e.message);\n}\n\nconst sourceText = toTextData.text || \u0027\u0027;\nconst extractedTitle = httpData.title || \u0027\u0027;\nconst snippet = rssData.contentSnippet || rssData.content || rssData.summary || \u0027\u0027;\nconst articleUrl = rssData.cleanUrl || rssData.link || \u0027\u0027;\n\n// Select memory source, falling back to snippet if empty or JS-blocker\nconst badJsMsg = \u0027JavaScript is not available.\u0027;\nconst memorySource = (!sourceText || sourceText.startsWith(badJsMsg))\n ? snippet\n : sourceText;\n\nconst memoryContent = [\n `You\u0027ve just read this content: ${memorySource}`\n];\n\n// Rally API payload\nconst rallyPayload = {\n smart: false,\n provider: \"openai\",\n query: \"After reading that content, how has your interest in spending money on synthetic research changed? A) Much more interested, B) Somewhat more interested, C) No change, D) Somewhat less interested, E) Much less interested\",\n audience_id: \"r8eb276513d8241\",\n voting_mode: true,\n mode: \"fast\",\n manual_memories: memoryContent,\n};\n\n// Return result\nreturn {\n title: extractedTitle || rssData.title || \"\",\n content: snippet,\n url: articleUrl,\n cleanTextLength: (httpData.text || \"\").length,\n usedCleanText: !!(httpData.text \u0026\u0026 httpData.text.length \u003e 200),\n rallyPayload: rallyPayload,\n debug: {\n sourceTextLength: sourceText.length,\n memorySourceFallbacked: memorySource === snippet,\n toTextDataFound: Object.keys(toTextData).length \u003e 0,\n rssDataFound: Object.keys(rssData).length \u003e 0,\n httpDataFound: Object.keys(httpData).length \u003e 0\n }\n};\n",
"mode": "runOnceForEachItem"
},
"position": [
1000,
180
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"credentials": {
"httpBearerAuth": {
"id": "wSoUK2sXm0c8MCMq",
"name": "Bearer Auth account 2"
}
},
"id": "fe2e8663-5b48-4b1b-86b4-bde6b626fb29",
"name": "call AskRally",
"parameters": {
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"jsonBody": "={{$json.rallyPayload}}",
"method": "POST",
"options": {},
"sendBody": true,
"sendHeaders": true,
"specifyBody": "json",
"url": "https://backend-staging-858a.up.railway.app/api/v1/chat"
},
"position": [
1200,
180
],
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2
},
{
"id": "1181cc9d-be42-4484-9b3e-12333d4ce94e",
"name": "Sticky Note2",
"parameters": {
"content": "# Step1: Get Content",
"height": 1100,
"width": 1000
},
"position": [
-80,
40
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "34cbaabc-e9d0-4a25-b138-cf99ad631cf0",
"name": "analyze simulation results1",
"parameters": {
"jsCode": "// Process each Rally API response individually\nconst item = $input.item.json;\n\nlet voteCounts = { A: 0, B: 0, C: 0, D: 0, E: 0 };\nlet totalVoters = 0;\nlet responses = [];\n\ntry {\n if (item.responses \u0026\u0026 Array.isArray(item.responses)) {\n totalVoters = item.responses.length;\n for (const personaResponse of item.responses) {\n try {\n const data = JSON.parse(personaResponse.response);\n const option = data.option;\n if (option \u0026\u0026 voteCounts.hasOwnProperty(option)) {\n voteCounts[option]++;\n }\n responses.push({\n persona_id: personaResponse.persona_id,\n option: option,\n thinking: data.thinking || \u0027\u0027,\n thoughts: personaResponse.thoughts\n });\n } catch (parseErr) {\n console.log(`Error parsing persona ${personaResponse.persona_id} response:`, parseErr.message);\n }\n }\n }\n} catch (err) {\n console.log(\u0027Error processing Rally response:\u0027, err.message);\n}\n\n// Calculate percentages\nconst percentages = {};\nfor (const opt of Object.keys(voteCounts)) {\n percentages[opt] = totalVoters \u003e 0\n ? Math.round((voteCounts[opt] / totalVoters) * 100)\n : 0;\n}\n\nconst proNarrative = percentages.A + percentages.B;\nconst contraNarrative= percentages.D + percentages.E;\nconst neutral = percentages.C;\n\n// --- NEW SAMPLING LOGIC: up to 5 from each bucket ---\nconst proGroup = responses.filter(r =\u003e [\u0027A\u0027,\u0027B\u0027].includes(r.option));\nconst neutralGroup = responses.filter(r =\u003e r.option === \u0027C\u0027);\nconst contraGroup = responses.filter(r =\u003e [\u0027D\u0027,\u0027E\u0027].includes(r.option));\n\nconst samplePro = proGroup.sort(() =\u003e 0.5 - Math.random()).slice(0, 5);\nconst sampleNeutral = neutralGroup.sort(() =\u003e 0.5 - Math.random()).slice(0, 5);\nconst sampleContra = contraGroup.sort(() =\u003e 0.5 - Math.random()).slice(0, 5);\n\nconst sampleResponses = [\n ...samplePro,\n ...sampleNeutral,\n ...sampleContra\n];\n\n// Determine predicted_pipeline_impact as before\nlet predicted_pipeline_impact = \u0027\u0027;\nif (proNarrative \u003e= 75) {\n predicted_pipeline_impact = \u0027pro-narrative\u0027;\n} else if (contraNarrative \u003e= 75) {\n predicted_pipeline_impact = \u0027contra-narrative\u0027;\n} else {\n predicted_pipeline_impact = \u0027mixed\u0027;\n}\n\n// Return individual result for this RSS item\nreturn {\n // Rally simulation metadata\n session_id: item.session_id || \u0027\u0027,\n title: item.title || \u0027Interest in Synthetic Research Spending\u0027,\n \n // Rally simulation results\n totalVoters,\n voteCounts,\n percentages,\n proNarrative,\n contraNarrative,\n neutral,\n responses,\n summary: item.summary || \u0027\u0027,\n \n // Pre-selected sample responses for email (up to 15 total)\n sampleResponses,\n predicted_pipeline_impact,\n \n // Metadata\n simulationId: item.session_id \n || `sim_${Date.now()}_${Math.random().toString(36).substr(2, 9)}`,\n \n // Debug info\n debug: {\n foundResponses: !!item.responses,\n responseCount: item.responses ? item.responses.length : 0,\n hasSessionId: !!item.session_id,\n proSampleCount: samplePro.length,\n neutralSampleCount: sampleNeutral.length,\n contraSampleCount: sampleContra.length,\n totalSampleResponses: sampleResponses.length\n }\n};",
"mode": "runOnceForEachItem"
},
"position": [
1480,
180
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "2a469f23-076e-4136-b477-b547588c699d",
"name": "RSS Read6",
"parameters": {
"options": {},
"url": "https://www.google.com/alerts/feeds/12254772602100657129/16808085471630190739"
},
"position": [
0,
180
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "05e15dd2-7269-4a85-89d2-bc871cadb9d4",
"name": "Schedule Trigger1",
"parameters": {
"rule": {
"interval": [
{
"triggerAtHour": 6
}
]
}
},
"position": [
-520,
540
],
"type": "n8n-nodes-base.scheduleTrigger",
"typeVersion": 1.2
},
{
"id": "a58d45fb-0d4d-46b2-adf0-ab326abc50a3",
"name": "RSS Read7",
"parameters": {
"options": {},
"url": "https://www.google.com/alerts/feeds/12254772602100657129/10246758638327575231"
},
"position": [
0,
340
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "cee3572f-ad34-4b72-811d-ff2ecca044ba",
"name": "RSS Read8",
"parameters": {
"options": {},
"url": "https://www.google.com/alerts/feeds/12254772602100657129/1689606288350529848"
},
"position": [
0,
500
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "541081d0-7ed3-42dc-ab91-058c53e6f6a2",
"name": "RSS Read9",
"parameters": {
"options": {},
"url": "https://www.google.com/alerts/feeds/12254772602100657129/125719305669051346"
},
"position": [
0,
660
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "60113ba9-6342-4f92-982f-7363b595edbc",
"name": "RSS Read10",
"parameters": {
"options": {},
"url": "https://www.google.com/alerts/feeds/12254772602100657129/4107866991761615820"
},
"position": [
0,
820
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "4b9655fb-289e-4d8a-9ca2-c52bedf716b4",
"name": "RSS Read11",
"parameters": {
"options": {},
"url": "https://www.google.com/alerts/feeds/12254772602100657129/8477455582161935404"
},
"position": [
0,
980
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "a25098bf-1c08-45c3-9fec-ffe4a116618d",
"name": "Sticky Note3",
"parameters": {
"color": 6,
"content": "# Step 2: Simulate Pipeline Impact From Industry News",
"height": 320,
"width": 740
},
"position": [
940,
40
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"executeOnce": false,
"id": "5ebc79fb-3fd0-4f17-a6d8-b45b0c8c8c52",
"name": "HTTP: Get Content1",
"parameters": {
"headerParameters": {
"parameters": [
{
"name": "User-Agent",
"value": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
},
{
"name": "Accept",
"value": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
},
{
"name": "Accept-Language",
"value": " en-US,en;q=0.5"
},
{
"name": "Accept-Encoding",
"value": "gzip, deflate"
},
{
"name": "Connection",
"value": "keep-alive"
},
{
"name": "Upgrade-Insecure-Requests",
"value": "1"
}
]
},
"options": {
"redirect": {
"redirect": {
"maxRedirects": 2
}
},
"response": {
"response": {}
}
},
"sendHeaders": true,
"url": "={{ $json.cleanUrl }}"
},
"position": [
600,
560
],
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2
},
{
"id": "582ae5df-7c5e-4aa6-bfd6-d1d6d5c72112",
"name": "to text",
"parameters": {
"jsCode": "// Simple HTML Text Extractor for n8n Code Node - Process All Items\n// Removes HTML tags and extracts clean text from any webpage\n\n// Get all input items using n8n syntax\nconst items = $input.all();\n\nconsole.log(`\ud83d\udd0d Processing ${items.length} items for text extraction`);\n\n// Simple but effective text extraction function\nfunction extractCleanText(html) {\n // Remove script and style elements completely\n let cleanHtml = html\n .replace(/\u003cscript\\b[^\u003c]*(?:(?!\u003c\\/script\u003e)\u003c[^\u003c]*)*\u003c\\/script\u003e/gi, \u0027\u0027)\n .replace(/\u003cstyle\\b[^\u003c]*(?:(?!\u003c\\/style\u003e)\u003c[^\u003c]*)*\u003c\\/style\u003e/gi, \u0027\u0027)\n .replace(/\u003cnav\\b[^\u003c]*(?:(?!\u003c\\/nav\u003e)\u003c[^\u003c]*)*\u003c\\/nav\u003e/gi, \u0027\u0027)\n .replace(/\u003cheader\\b[^\u003c]*(?:(?!\u003c\\/header\u003e)\u003c[^\u003c]*)*\u003c\\/header\u003e/gi, \u0027\u0027)\n .replace(/\u003cfooter\\b[^\u003c]*(?:(?!\u003c\\/footer\u003e)\u003c[^\u003c]*)*\u003c\\/footer\u003e/gi, \u0027\u0027)\n .replace(/\u003caside\\b[^\u003c]*(?:(?!\u003c\\/aside\u003e)\u003c[^\u003c]*)*\u003c\\/aside\u003e/gi, \u0027\u0027);\n \n // Extract title\n const titleMatch = cleanHtml.match(/\u003ctitle[^\u003e]*\u003e([^\u003c]+)\u003c\\/title\u003e/i);\n const title = titleMatch ? titleMatch[1].trim() : \u0027No title found\u0027;\n \n // Remove all HTML tags\n let text = cleanHtml\n .replace(/\u003c[^\u003e]+\u003e/g, \u0027 \u0027) // Remove all HTML tags\n .replace(/\u0026nbsp;/gi, \u0027 \u0027) // Replace \u0026nbsp; with space\n .replace(/\u0026amp;/gi, \u0027\u0026\u0027) // Replace \u0026amp; with \u0026\n .replace(/\u0026lt;/gi, \u0027\u003c\u0027) // Replace \u0026lt; with \u003c\n .replace(/\u0026gt;/gi, \u0027\u003e\u0027) // Replace \u0026gt; with \u003e\n .replace(/\u0026quot;/gi, \u0027\"\u0027) // Replace \u0026quot; with \"\n .replace(/\u0026#\\d+;/g, \u0027 \u0027) // Remove other HTML entities\n .replace(/\\s+/g, \u0027 \u0027) // Replace multiple spaces with single space\n .trim();\n \n // Filter out common unwanted text patterns\n const unwantedPatterns = [\n /cookie/i, /advertisement/i, /subscribe/i, /newsletter/i,\n /privacy policy/i, /terms of service/i, /follow us/i, /share this/i\n ];\n \n // Split into sentences and filter\n const sentences = text.split(/[.!?]+/).filter(sentence =\u003e {\n const s = sentence.trim();\n if (s.length \u003c 20) return false; // Skip very short sentences\n if (unwantedPatterns.some(pattern =\u003e pattern.test(s))) return false; // Skip unwanted content\n return true;\n });\n \n return {\n title: title,\n text: sentences.join(\u0027. \u0027).trim(),\n sentences: sentences,\n originalLength: html.length,\n cleanLength: text.length\n };\n}\n\n// Process all items and return array of results\nconst results = [];\n\nfor (let i = 0; i \u003c items.length; i++) {\n const item = items[i];\n \n try {\n // Get the HTML content from current item\n const html = item.binary?.data\n ? Buffer.from(item.binary.data.data, \u0027base64\u0027).toString()\n : item.json.body || item.json.data || item.json.html;\n\n const url = item.json.url || `Item ${i + 1}`;\n \n console.log(`\ud83d\udcc4 Processing item ${i + 1}/${items.length}: ${url}`);\n console.log(` HTML length: ${html.length} characters`);\n \n const extracted = extractCleanText(html);\n \n console.log(` \u2705 Extracted: \"${extracted.title}\"`);\n console.log(` \ud83d\udcdd Clean text: ${extracted.cleanLength} characters`);\n console.log(` \ud83d\udcc4 Found ${extracted.sentences.length} sentences`);\n \n results.push({\n // Preserve original item data\n ...item.json,\n // Add extracted text data\n title: extracted.title,\n text: extracted.text,\n sentences: extracted.sentences,\n url: url,\n wordCount: extracted.text.split(/\\s+/).length,\n sentenceCount: extracted.sentences.length,\n compressionRatio: Math.round((extracted.cleanLength / extracted.originalLength) * 100),\n success: true,\n itemIndex: i\n });\n \n } catch (error) {\n console.error(`\u274c Error processing item ${i + 1}:`, error.message);\n \n results.push({\n // Preserve original item data\n ...item.json,\n // Add error data\n title: \u0027Error\u0027,\n text: \u0027\u0027,\n url: item.json.url || `Item ${i + 1}`,\n wordCount: 0,\n success: false,\n error: error.message,\n itemIndex: i\n });\n }\n}\n\nconsole.log(`\ud83c\udf89 Completed processing ${results.length} items`);\n\nreturn results;"
},
"position": [
760,
560
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "4147ccc3-80cc-469d-9005-caa689929974",
"name": "Sticky Note5",
"parameters": {
"color": 7,
"content": "## Human In The Loop",
"height": 420,
"width": 880
},
"position": [
1700,
1180
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "6a90a8b2-bdf4-4691-a88b-4acb197a0561",
"name": "Sticky Note8",
"parameters": {
"color": 5,
"content": "# Step 3: Seed Meme Idea",
"height": 380,
"width": 740
},
"position": [
940,
380
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "15e85c66-00ca-40c0-804c-5fec758c34dd",
"name": "Code3",
"parameters": {
"jsCode": "// Flatten all simulations that arrive on the wire\nconst sims = $input.all().flatMap(item =\u003e {\n // Each item may already wrap its data under simulation_results\n const arr = item.json.simulation_results ?? [item.json];\n\n // Pick just the fields we want from every simulation object\n return arr.map(({ percentages, summary, sampleResponses }) =\u003e ({\n percentages,\n summary,\n sampleResponses\n }));\n});\n\n// Return one tidy object\nreturn [\n {\n json: { simulation_results: sims }\n }\n];\n"
},
"position": [
1000,
460
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"credentials": {
"openAiApi": {
"id": "5LyzIG7SUcgxGxlz",
"name": "OpenAi account 2"
}
},
"id": "b5858bf7-5e92-48e5-967c-75f155485213",
"name": "Message a model4",
"parameters": {
"jsonOutput": true,
"messages": {
"values": [
{
"content": "You are a B2B GTM strategist.\n\nTASK \n-----\nParse *every* simulation\u2019s `percentages` and `sampleResponses`.\n\n1. **Theme mining** \n \u2022 List the narrative motifs that appear in \u2265 2 \u201cA/B\u201d comments (what excites buyers). \n \u2022 List the motifs that appear in \u2265 2 \u201cD/E\u201d comments (what scares buyers). \n \u2022 For each motif give a one-line proof quote (trimmed) and a tally of how many times it shows up.\n\n2. **Counter-intuition hunt** \n \u2022 Compare the two lists. Look for a pattern that is *not* obvious from headline voting alone \n \u2022 Formulate one commercially valuable insight for Ask Rally: a sentence that reveals this hidden tension and how to exploit it in messaging.\n\n3. **Craft two memes** \n \u2022 *meme_to_boost* \u2013 \u003c60 chars; amplifies a winning motif. \n \u2022 *meme_to_nuke* \u2013 \u003c60 chars; disarms a losing motif.\n\nOUTPUT \n------\nReturn **only** a JSON object that follows exactly this schema \u0026 order\n(keep keys snake_case, no extra keys, max 280 chars total per string):\n\n```json\n{\n \"insight\": \"string\",\n \"meme_to_boost\": \"string\",\n \"meme_to_nuke\": \"string\"\n}\n\u2022 Do not summarise anything outside the JSON.\n\n",
"role": "=system"
},
{
"content": "=\u201csimulation_results\u201d: {{ JSON.stringify(\n $json.simulation_results.map(\n ({ percentages, sampleResponses }) =\u003e\n ({ percentages, sampleResponses })\n ),\n null,\n 2\n) }}\n\n"
}
]
},
"modelId": {
"__rl": true,
"cachedResultName": "O3-MINI",
"mode": "list",
"value": "o3-mini"
},
"options": {},
"simplify": false
},
"position": [
1000,
600
],
"type": "@n8n/n8n-nodes-langchain.openAi",
"typeVersion": 1.8
},
{
"credentials": {
"openAiApi": {
"id": "5LyzIG7SUcgxGxlz",
"name": "OpenAi account 2"
}
},
"id": "5db3327a-8e82-4ae4-89cd-701d47e54bed",
"name": "Message a model5",
"parameters": {
"jsonOutput": true,
"messages": {
"values": [
{
"content": "You are a meme-strategist for a B2B SaaS brand called Ask Rally, an AI-persona simulation platform.\n\n\u2726 OBJECTIVE\nGenerate ONE fresh meme concept that:\n\u2022 Makes professionals laugh, then see the product\u2019s value.\n\u2022 Draws some inspo from **content**\n\n\u2726 WHAT TO DELIVER\nReturn your answer in **exactly this JSON** so designers can build it fast:\n\n{\n \"title\": \"\u003c3-5 word name for the meme\u003e\",\n \"template\": \"an original visual concept\",\n \"image copy\": \"any copy that should overlay the image\",\n \"postCopy\": \"\u003ctweet caption,\n description\u003e\",\n \"whyItWorks\": \"\u003c1-sentence rationale tying humor device to the insight\u003e\"\n}\n\n\u2726 CREATIVE GUARDRAILS\n\u2022 Feel free to pick *any* meme style\n or invent a simple image with text above gag. Surprise us. \n\u2022 Humor devices allowed: exaggeration, contrast, status flex, sudden incongruity, unpopular truth, Status flex + absurd premise , Relatable panic, Dark left-field twist, Mismatched voice) \n\u2022 No overt dystopia, fear-mongering, or replacing humans; AI = empowering sidekick. \n\u2022 Stay brand-risk on; be bold and brave\n\u2022 Sets up an everyday business pain or trope.\n\u2022 Smashes it with an exaggerated or totally mismatched punch-line.\n\u2022 Leaves just enough gap for the reader to \u201cget the joke\u201d on their own.\n\n\u2726 INPUTS\n{\n \"content\": \"insight from our research\",\n}\n\n\u2726 OUTPUT ONLY THE JSON \u2014 no extra commentary.",
"role": "=system"
},
{
"content": "=\"content\": {{ JSON.stringify($json[\"choices\"][0].message.content) }}\n"
}
]
},
"modelId": {
"__rl": true,
"cachedResultName": "O3-MINI",
"mode": "list",
"value": "o3-mini"
},
"options": {},
"simplify": false
},
"position": [
1340,
600
],
"type": "@n8n/n8n-nodes-langchain.openAi",
"typeVersion": 1.8
},
{
"credentials": {
"httpBearerAuth": {
"id": "wSoUK2sXm0c8MCMq",
"name": "Bearer Auth account 2"
}
},
"id": "4d7d282c-2797-4386-b104-0e2bcdabc05b",
"name": "Ask Rally",
"parameters": {
"authentication": "genericCredentialType",
"bodyParameters": {
"parameters": [
{
"name": "smart",
"value": "false"
},
{
"name": "provider",
"value": "google"
},
{
"name": "query",
"value": "=You\u0027re scrolling LinkedIn during a lunch walk break and you see the following memes. Which would you leave a laugh reaction on?:\n\n{{ \n $json.choices[0].message.content.memes\n .map((m,i) =\u003e \n `${String.fromCharCode(97 + i)}) Template: ${m.memeTemplate}\\n` +\n `Image copy: ${m.imageCopy}\\n` +\n `Post copy: ${m.postCopy}`\n )\n .join(\u0027\\n\\n\u0027)\n}}\n\n"
},
{
"name": "audience_id",
"value": "rb842b547c27640"
},
{
"name": "voting_mode",
"value": "true"
},
{
"name": "audience_id",
"value": "r8eb276513d8241"
}
]
},
"genericAuthType": "httpBearerAuth",
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
},
{
"name": "accept",
"value": "application/json"
}
]
},
"method": "POST",
"options": {},
"sendBody": true,
"sendHeaders": true,
"url": "=enter rally api end point"
},
"position": [
1800,
160
],
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2
},
{
"id": "a59420c5-0706-444c-bf8c-7b8e05329f40",
"name": "Get Individual Votes",
"parameters": {
"fieldToSplitOut": "responses",
"options": {}
},
"position": [
2020,
160
],
"type": "n8n-nodes-base.splitOut",
"typeVersion": 1
},
{
"id": "9e7dcdfc-b6b7-44d3-98a4-141b38c7842d",
"name": "Calculate CTR",
"parameters": {
"jsCode": "// 1) Count how many people picked each letter (a,b,c\u2026)\nlet optionCounts = {}, total = 0;\nfor (const item of $input.all()) {\n try {\n const r = JSON.parse(item.json.response);\n if (r.option) {\n total++;\n optionCounts[r.option] = (optionCounts[r.option] || 0) + 1;\n }\n } catch (e) {\n console.log(`\u26a0\ufe0f bad JSON for persona ${item.json.persona_id}:`, e.message);\n }\n}\n\n// 2) Pull the real `simulation_results` out of *your* LLM node\nlet adVariations = [];\ntry {\n // replace \"Message a model6\" with whatever your Chat node is actually called\n const llm = $node[\"Message a model6\"].json;\n adVariations = llm.choices[0].message.content.simulation_results || [];\n} catch (e) {\n console.log(\"\u26a0\ufe0f couldn\u2019t find simulation_results:\", e.message);\n}\n\n// 3) Zip counts \u2194\ufe0f meme objects and compute %\nconst variationsWithAds = [];\nfor (const [opt, cnt] of Object.entries(optionCounts)) {\n const pct = total ? (cnt/total*100).toFixed(1) : \"0.0\";\n const idx = opt.charCodeAt(0) - 97; // a\u21920, b\u21921\u2026\n const m = adVariations[idx] || {};\n variationsWithAds.push({\n option: opt,\n count: cnt,\n percentage: parseFloat(pct),\n template: m.memeTemplate || \"\u2014\",\n imageCopy: m.imageCopy || \"\u2014\",\n postCopy: m.postCopy || \"\u2014\",\n });\n}\n\n// 4) Sort by highest CTR and log\nvariationsWithAds.sort((a,b)=\u003eb.percentage - a.percentage);\nconsole.log(`Total responses: ${total}`);\nvariationsWithAds.forEach(v=\u003e{\n console.log(`${v.option.toUpperCase()}) ${v.template} \u2014 ${v.count} clicks (${v.percentage}%)`);\n});\n\n// 5) Return for downstream\nreturn { total, variationsWithAds };\n"
},
"position": [
1800,
400
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "6e856777-7302-4c8b-8cd8-b88e24d73b43",
"name": "Sticky Note13",
"parameters": {
"color": 2,
"content": "## Fan Out Creative\nGenerate 8 new creative variations based on the original.",
"height": 360,
"width": 740
},
"position": [
940,
780
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "587b3c8a-2d9b-41f3-8eea-fd41ba8479b6",
"name": "Sticky Note12",
"parameters": {
"color": 4,
"content": "## Synthetic Testing\nTake 8 new variations and test them against the original.",
"height": 500,
"width": 540
},
"position": [
1700,
40
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"credentials": {
"openAiApi": {
"id": "5LyzIG7SUcgxGxlz",
"name": "OpenAi account 2"
}
},
"id": "041f21cb-6ff0-4131-ad6d-cd2c85d56808",
"name": "Message a model6",
"parameters": {
"jsonOutput": true,
"messages": {
"values": [
{
"content": "Come up with 8 new very creative variations on this meme idea by changing the image copy, postCopy. Do not deviate from the core creative idea (title/template), just express it in more creative ways. image copy can be up to 24 words, while post copy can be 140 characters. Only respond with an array of meme template, image copy and postCopy combinations. Always start with the original Headline and Description you were given as the first in the list, then add your 8 new variations after.\n\n## Business we are trying to create commercial value for Ask Rally, an AI-persona simulation platform.\n\n## Examples \nHere are some examples to show you what the task looks like when done well. \nYou should not use these examples in your output\u2014always make **new** variations relevant to the brand.\n\n**Original Meme:**\n- memeTemplate: \"Smug Yacht Laptop\"\n- imageCopy: \"Exit plan: simulate, scale, sail, settle\u2026 \u2026who needs compliance when you\u0027re on a yacht.\"\n- postCopy: \"Sail past red tape\u2014run an AI persona sim before regulators even clock in. #PowerYourGenius\"\n\n**Output:**\n\n```json\n[\n {\n \"memeTemplate\": \"Smug Yacht Laptop\",\n \"imageCopy\": \"Exit plan: simulate, scale, sail, settle\u2026 \u2026who needs compliance when you\u0027re on a yacht.\",\n \"postCopy\": \"Sail past red tape\u2014run an AI persona sim before regulators even clock in.\"\n },\n {\n \"memeTemplate\": \"Conspiracy Keanu\",\n \"imageCopy\": \"WHEN U SCREW UP A FIRST IMPRESSION\u2026 \u2026AND LEARN U COULD HAVE SIMULATED IT WITH AI PERSONAS\",\n \"postCopy\": \"That face when you realise gut-check \u2260 sim-check.\n },\n {\n \"memeTemplate\": \"Chat-Bubble Screenshot\",\n \"imageCopy\": \"Text: \u0027When an AI company I invested in has a North Korean spy\u0027\n \"postCopy\": \"Even ridiculous scenarios deserve a quick focus-group sim.\"\n },\n {\n \"memeTemplate\": \"Uncalibrated Redneck\",\n \"imageCopy\": \"UNCALIBRATED AI PERSONAS BE LIKE: \u0027THINK I NEED TO REDUCE MY CARBON FOOTPRINT\u0027\",\n \"postCopy\": \"Mullet logic? Calibrate those personas before you trust the take. \n }\n]\n",
"role": "=system"
},
{
"content": "=\"simulation_results\": {{ JSON.stringify($json[\"choices\"][0].message.content) }}\n"
}
]
},
"modelId": {
"__rl": true,
"cachedResultName": "O3-MINI",
"mode": "list",
"value": "o3-mini"
},
"options": {},
"simplify": false
},
"position": [
1360,
920
],
"type": "@n8n/n8n-nodes-langchain.openAi",
"typeVersion": 1.8
},
{
"id": "2738b9d0-1921-4083-9ebe-e45a96ad6e43",
"name": "Sticky Note14",
"parameters": {
"color": 7,
"content": "## Creative generation",
"height": 580,
"width": 880
},
"position": [
1700,
560
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "4759a487-3225-46d4-80c7-ec2c6898cf52",
"name": "Description",
"parameters": {
"assignments": {
"assignments": [
{
"id": "76861df4-8aa5-4ddf-99ba-908ab20f9c6e",
"name": "description",
"type": "string",
"value": "={{ $json.message.content }}"
}
]
},
"options": {}
},
"position": [
2080,
640
],
"type": "n8n-nodes-base.set",
"typeVersion": 3.4
},
{
"credentials": {
"openAiApi": {
"id": "5LyzIG7SUcgxGxlz",
"name": "OpenAi account 2"
}
},
"id": "87efda79-3420-4294-af3b-7de04c223dbb",
"name": "Generate Image",
"parameters": {
"options": {},
"prompt": "={{ $json.description }}",
"resource": "image"
},
"position": [
1760,
860
],
"type": "@n8n/n8n-nodes-langchain.openAi",
"typeVersion": 1.8
},
{
"credentials": {
"openAiApi": {
"id": "5LyzIG7SUcgxGxlz",
"name": "OpenAi account 2"
}
},
"id": "171d7ece-90fc-430d-92d3-91def18eb96d",
"name": "Write Description1",
"parameters": {
"messages": {
"values": [
{
"content": "You are an art director for a satire publication, and your job is to describe what the meme image should look like when given a winning meme idea. Be brief, and only return the details that are most essential to making an unforgettable image. Only return the description, no other text.",
"role": "system"
},
{
"content": "=Briefly describe what image would make sense for the featured image on this meme idea:\n\nwinner: Template: {{ $json.template }}\nImage copy: {{ $json.imageCopy }}\nPost copy: {{ $json.postCopy }}\n\n\n"
}
]
},
"modelId": {
"__rl": true,
"cachedResultName": "CHATGPT-4O-LATEST",
"mode": "list",
"value": "chatgpt-4o-latest"
},
"options": {}
},
"position": [
1760,
640
],
"type": "@n8n/n8n-nodes-langchain.openAi",
"typeVersion": 1.8
},
{
"id": "28a5b81b-c7be-47c0-a96e-3f08a2fd17ee",
"name": "grab winner",
"parameters": {
"jsCode": "// 1) Grab your CTR payload\nconst item = $input.item.json;\nconst variations = item.variationsWithAds || [];\nif (variations.length === 0) {\n throw new Error(\u0027No variationsWithAds[] found\u0027);\n}\n\n// 2) Pick the winner by highest percentage\nconst winnerRec = variations.reduce((best, cur) =\u003e\n cur.percentage \u003e (best.percentage||0) ? cur : best,\n {}\n);\n\n// 3) Pull in your model6 output\nconst NODE = \u0027Message a model6\u0027; // \u2190 must match your workflow\nconst m6 = ($items(NODE)[0] || {}).json;\nif (!m6) throw new Error(`No data from node \"${NODE}\"`);\nconst content = m6.choices?.[0]?.message?.content;\nif (!content) {\n console.log(\u0027Full model6 JSON:\u0027, JSON.stringify(m6, null, 2));\n throw new Error(`Couldn\u2019t find .choices[0].message.content in \"${NODE}\"`);\n}\n\n// 4) Find your array (or single object) of creatives\nlet pool = content.memes || content.simulation_results;\nif (!Array.isArray(pool)) {\n // fallback to single\u2010object pattern\n pool = [{\n template: content.template,\n imageCopy: content[\u0027image copy\u0027] || content.imageCopy,\n postCopy: content[\u0027post copy\u0027] || content.postCopy,\n }];\n}\n\n// 5) Safely convert your option letter to an index\nlet idx = 0;\nif (typeof winnerRec.option === \u0027string\u0027) {\n const o = winnerRec.option.trim().toLowerCase();\n if (/^[a-z]$/.test(o)) {\n const i = o.charCodeAt(0) - 97;\n if (i \u003e= 0 \u0026\u0026 i \u003c pool.length) idx = i;\n }\n}\n\n// 6) Enrich the winner and return\nconst full = pool[idx] || {};\nreturn [{\n json: {\n // carry forward your CTR stats\n total: item.total,\n option: winnerRec.option,\n count: winnerRec.count,\n percentage: winnerRec.percentage,\n // bring in the creative fields\n template: full.memeTemplate || full.template || \u0027\u0027,\n imageCopy: full.imageCopy || full[\u0027image copy\u0027] || \u0027\u0027,\n postCopy: full.postCopy || full[\u0027post copy\u0027] || \u0027\u0027,\n }\n}];\n\n\n"
},
"position": [
2020,
400
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"credentials": {
"gmailOAuth2": {
"id": "JFRMn1ji8imM26f4",
"name": "Gmail account"
}
},
"id": "259a39af-6cff-4899-bad0-98cb5ac09690",
"name": "Gmail5",
"parameters": {
"message": "=\u003cdiv style=\"font-family: Arial, sans-serif; max-width: 600px; margin: 0 auto; padding: 20px;\"\u003e\n\n \u003c!-- Header --\u003e\n \u003cdiv style=\"background-color: #f8f9fa; padding: 15px; border-radius: 8px; margin-bottom: 20px;\"\u003e\n \u003ch2 style=\"margin: 0; color: #333;\"\u003e\ud83d\udce2 AskRally Meme Drop\u003c/h2\u003e\n \u003c/div\u003e\n\n \u003c!-- Persona Data --\u003e\n \u003cdiv style=\"background-color: #ffffff; border: 1px solid #e9ecef; border-radius: 8px; padding: 20px; margin-bottom: 20px;\"\u003e\n \u003ch3 style=\"color: #495057; margin-top: 0; border-bottom: 2px solid #dee2e6; padding-bottom: 10px;\"\u003e\n \ud83e\udde0 {{$json.template}} \ud83e\udda0\n \u003c/h3\u003e\n \u003cp\u003e\u003cstrong\u003eImage Copy:\u003c/strong\u003e\u003cbr/\u003e\n \u003cem style=\"color: #6c757d;\"\u003e{{$json.imageCopy}}\u003c/em\u003e\u003c/p\u003e\n\n \u003cp\u003e\u003cstrong\u003ePost Copy:\u003c/strong\u003e\u003cbr/\u003e\n {{$json.postCopy}}\u003c/p\u003e\n\n \u003cp\u003e\u003cstrong\u003eThumbnail Preview:\u003c/strong\u003e\u003c/p\u003e\n \u003ca href=\"{{$json.webViewLink}}\" target=\"_blank\"\u003e\n \u003cimg src=\"{{$json.thumbnailLink}}\" \n alt=\"Persona Thumbnail\" \n style=\"width: 100%; max-width: 500px; height: auto; border-radius: 6px; border: 1px solid #ccc;\"\u003e\n \u003c/a\u003e\n \u003c/div\u003e\n\n \u003c!-- Footer --\u003e\n \u003cdiv style=\"background-color: #f8f9fa; padding: 15px; border-radius: 8px; text-align: center; font-size: 12px; color: #6c757d;\"\u003e\n \u003cp style=\"margin: 0;\"\u003e\n Powered by \n \u003ca href=\"https://askrally.com/?utm_source=api\u0026utm_medium=email\u0026utm_campaign=rss-to-meme-machine-v1\" \n style=\"color: #007bff; text-decoration: none;\"\u003e\n AskRally.com\n \u003c/a\u003e\n \u003c/p\u003e\n \u003c/div\u003e\n\n\u003c/div\u003e\n",
"options": {},
"sendTo": "Enter Your Email",
"subject": "="
},
"position": [
1780,
1260
],
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"webhookId": "d47ea3ca-9545-4638-a6f5-b25374cf0760"
},
{
"id": "2d1da9e6-3971-41a7-94b7-648471d5c075",
"name": "Merge1",
"parameters": {
"combineBy": "combineByPosition",
"mode": "combine",
"options": {}
},
"position": [
2400,
840
],
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2
},
{
"credentials": {
"googleDriveOAuth2Api": {
"id": "lolQfCBJjJ6XjXJ3",
"name": "Google Drive account"
}
},
"id": "8c1ca725-9ba8-4f6c-ae93-f5e0b8a97ea9",
"name": "Google Drive",
"parameters": {
"driveId": {
"__rl": true,
"mode": "list",
"value": "My Drive"
},
"folderId": {
"__rl": true,
"cachedResultName": " n8n-memes",
"cachedResultUrl": "https://drive.google.com/drive/folders/1gzzLUXWdLgKiIjTcXfiAt4rxzf-H9PIc",
"mode": "list",
"value": "1gzzLUXWdLgKiIjTcXfiAt4rxzf-H9PIc"
},
"options": {}
},
"position": [
1960,
860
],
"type": "n8n-nodes-base.googleDrive",
"typeVersion": 3
},
{
"id": "90412f4b-8f00-4a24-85e0-ef9173dfa34d",
"name": "Sticky Note",
"parameters": {
"color": 5,
"content": "This step extract insights and think up meme ideas. \n\nTip: tweak the prompts\n",
"height": 120,
"width": 200
},
"position": [
1240,
460
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
}
],
"pinData": {},
"settings": {
"executionOrder": "v1"
},
"tags": [],
"versionId": "52f8b909-6c94-4451-98bf-05ba458882ae"
}About the Author
Rhys Fisher
Rhys Fisher is the COO & Co-Founder of Rally. He previously co-founded a boutique analytics agency called Unvanity, crossed the Pyrenees coast-to-coast via paraglider, and now watches virtual crowds respond to memes. Follow him on Twitter @virtual_rf
