This workflow turns news monitoring into an early-warning demand engine. It continuously ingests Google Alert RSS feeds, extracts the full text of every article, and runs real-time purchase-intent modeling to predict which stories will sway your buyers—positively or negatively. The moment a spike in intent is detected, it triggers an early warning email so you can run with the right playbooks: amplify favorable narratives to accelerate deal cycles, or counter harmful ones before they dent your pipeline. Ideal for revenue teams that want to harness media signals instead of reacting to them after the fact.
Back to n8n Workflows
 Rhys Fisher
Rhys Fisher
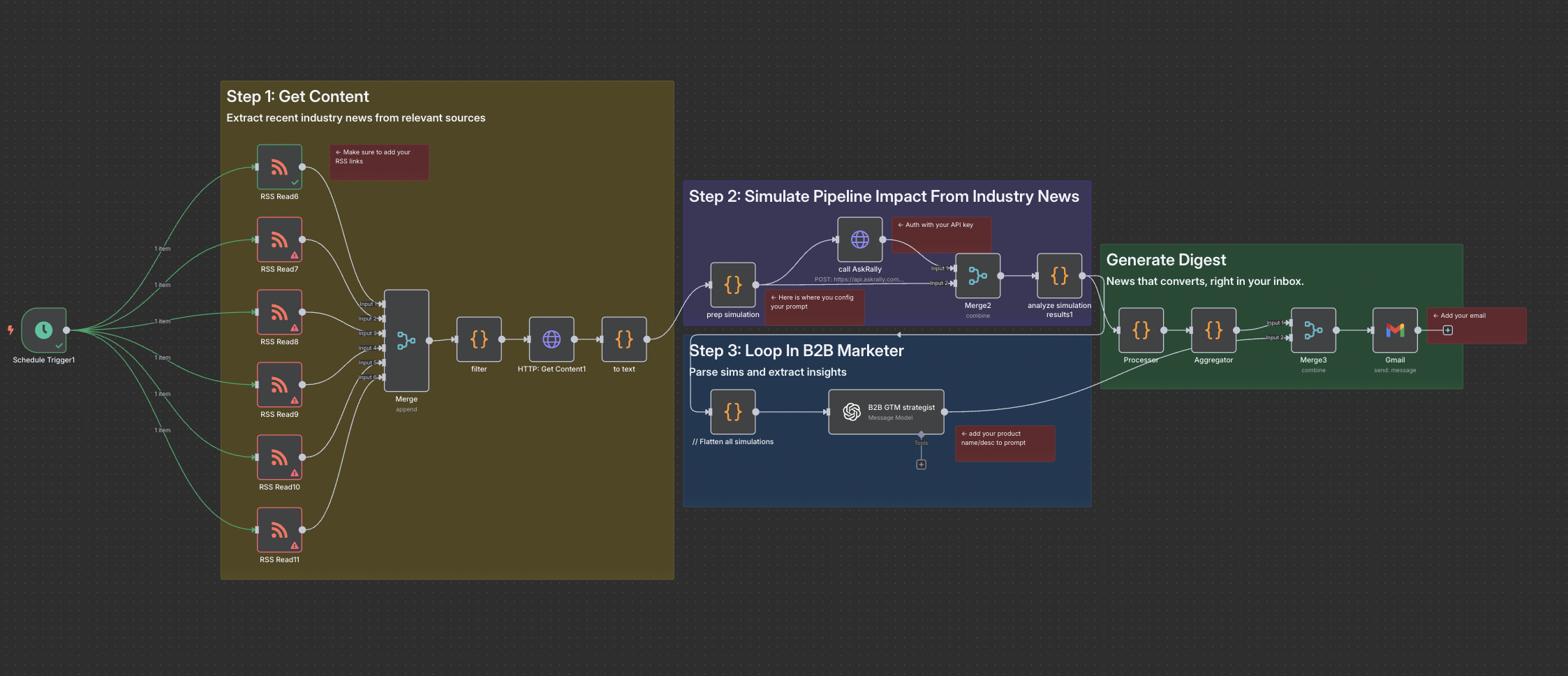

Monitor RSS Feeds And Simulate Impact On PipeLine
Rhys Fisher
Automatically pull Google Alert RSS feeds, extract each article, and forecast its impact on purchase intent in advance. With early visibility into demand drivers, you can trigger playbooks that amplify narratives that move buyers—or neutralize damaging ones—before they disrupt your pipeline.
Click to expand
Summarize in
OR
Summarize in
OR
Overview
🎯 Pro Tips & Secret Sauce
The magic lies in the three-stage signal-to-action pipeline:
-
Noise-Free Feed Curation – Configure Google Alert RSS feeds with advanced operators (
intitle:,site:) and negative keywords to keep irrelevant hits out of the pipeline, so the model isn’t distracted by “false-positive” news. -
Forward-Looking Intent Scoring – Run simulated impact on buyer intent, calculate impact and detect “spike” thresholds. This helps you predict threats or opportunities the same day the content breaks.
- Human-in-the-Loop Overrides – Send high-impact spikes to your email. Refine the simulation with iterations to the prompt (or audience) ensuring the nuance that moves your bottom line is'nt lost in the loop.
-
Opportuity For Calibration – Pipe CRM win/loss data back along with confirmed media mentions back into the model weekly. Stories that correlate with won deals get a weight boost; those with no measurable lift are down-ranked, continuously sharpening predictive power.
Apply these tips and the workflow becomes a living, self-tuning radar: it spots demand shocks early, launches the right narrative countermeasures automatically, and grows smarter with every cycle.
📝 Step-by-Step Instructions
- Add RSS Triggers - copy paste your RSS urls.
- Prep simulation Config - add your industry and product category in the prompt, audience_id, and model
- AskRally Auth - Setup your bearer token using your AskRally API key
- B2B Marketer Config - Add your product name/desc to prompt
- Add email - add your email to recieve alerts
- Test- Click play on the email play button (if it works, switch on the automation).
📋 Requirements
Required Integrations
- Rally API - AI persona testing service for simulating real user ad selection behavior
- Google Alert - RSS feed link for the keyword your want to ingest media for
- Gmail - so that you can trigger emails
Required Credentials
- Rally API Bearer token with voting mode access
- Gmail oauth configured
Setup Prerequisites
- Active Rally account with configured audience personas
- n8n instance
- Google RSS link
🚀 n8n Workflow Template
{
"active": false,
"connections": {
"Code3": {
"main": [
[
{
"index": 0,
"node": "Message a model4",
"type": "main"
}
]
]
},
"Drop failed": {
"main": [
[
{
"index": 0,
"node": "to text",
"type": "main"
}
]
]
},
"HTTP: Get Content1": {
"main": [
[
{
"index": 0,
"node": "Loop Over Items",
"type": "main"
}
]
]
},
"Loop Over Items": {
"main": [
[
{
"index": 0,
"node": "Drop failed",
"type": "main"
}
],
[
{
"index": 0,
"node": "Wait",
"type": "main"
}
]
]
},
"Loop Over Items1": {
"main": [
[
{
"index": 0,
"node": "Merge2",
"type": "main"
}
],
[
{
"index": 0,
"node": "call AskRally",
"type": "main"
}
]
]
},
"Merge": {
"main": [
[
{
"index": 0,
"node": "filter",
"type": "main"
}
]
]
},
"Merge2": {
"main": [
[
{
"index": 0,
"node": "vote\u2011parsing, sampling and analytics",
"type": "main"
}
]
]
},
"Merge3": {
"main": [
[
{
"index": 0,
"node": "Send a message",
"type": "main"
}
]
]
},
"Message a model4": {
"main": [
[
{
"index": 1,
"node": "Merge3",
"type": "main"
}
]
]
},
"RSS Read10": {
"main": [
[
{
"index": 4,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read6": {
"main": [
[
{
"index": 0,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read7": {
"main": [
[
{
"index": 1,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read8": {
"main": [
[
{
"index": 2,
"node": "Merge",
"type": "main"
}
]
]
},
"RSS Read9": {
"main": [
[
{
"index": 3,
"node": "Merge",
"type": "main"
}
]
]
},
"Schedule Trigger1": {
"main": [
[
{
"index": 0,
"node": "RSS Read6",
"type": "main"
},
{
"index": 0,
"node": "RSS Read7",
"type": "main"
},
{
"index": 0,
"node": "RSS Read8",
"type": "main"
},
{
"index": 0,
"node": "RSS Read9",
"type": "main"
},
{
"index": 0,
"node": "RSS Read10",
"type": "main"
}
]
]
},
"Wait": {
"main": [
[
{
"index": 0,
"node": "HTTP: Get Content1",
"type": "main"
}
]
]
},
"call AskRally": {
"main": [
[
{
"index": 0,
"node": "Loop Over Items1",
"type": "main"
}
]
]
},
"filter": {
"main": [
[
{
"index": 0,
"node": "Loop Over Items",
"type": "main"
}
]
]
},
"prep simulation": {
"main": [
[
{
"index": 1,
"node": "Merge2",
"type": "main"
},
{
"index": 0,
"node": "Loop Over Items1",
"type": "main"
}
]
]
},
"to text": {
"main": [
[
{
"index": 0,
"node": "prep simulation",
"type": "main"
}
]
]
},
"vote\u2011parsing, sampling and analytics": {
"main": [
[
{
"index": 0,
"node": "Merge3",
"type": "main"
},
{
"index": 0,
"node": "Code3",
"type": "main"
}
]
]
}
},
"id": "3NcJEVg5qktI4z8G",
"meta": {
"instanceId": "fb04b4346f624bab301ba87af3de742ec86c55ec1dfa2ee5f5fef9aebaad9741"
},
"name": "Monitor RSS Feeds And Simulate Impact On PipeLine",
"nodes": [
{
"id": "6889cb5c-8e30-4625-b45d-36f9e4786fb1",
"name": "filter",
"parameters": {
"jsCode": "// Multi-item deduplication + time filter + URL extraction (FIXED VERSION)\nconst items = $input.all();\nconst hoursThreshold = 24; // 24 hours\nconst now = new Date();\n\nconsole.log(`Processing ${items.length} RSS items for deduplication, filtering, and URL extraction`);\nconsole.log(`Current time: ${now.toISOString()}`);\n\n// Helper functions\nfunction stripTags(str) {\n return (str || \u0027\u0027).replace(/\u003c[^\u003e]+\u003e/g, \u0027\u0027).trim();\n}\n\nfunction normalizeTitle(title) {\n return stripTags(title)\n .replace(/\\s*\u2013.*$/, \u0027\u0027) // Remove \" \u2013 AMI\", \" \u2013 Mi3\" suffixes\n .replace(/\\s*-.*$/, \u0027\u0027) // Remove \" - AMI\", \" - Mi3\" suffixes \n .toLowerCase()\n .trim();\n}\n\nfunction extractCleanUrl(originalUrl) {\n let cleanUrl = originalUrl;\n if (originalUrl \u0026\u0026 originalUrl.includes(\u0027google.com/url\u0027)) {\n const match = originalUrl.match(/[\u0026?]url=([^\u0026]+)/);\n if (match) {\n try {\n cleanUrl = decodeURIComponent(match[1]);\n } catch (error) {\n cleanUrl = originalUrl;\n }\n }\n }\n return cleanUrl;\n}\n\n// Step 1: Time filtering\nconst timeFilteredItems = items.filter((item, index) =\u003e {\n try {\n const pubDate = new Date(item.json.pubDate || item.json.isoDate);\n const ageInHours = (now - pubDate) / (1000 * 60 * 60);\n \n console.log(`Item ${index}: \"${item.json.title}\"`);\n console.log(` Published: ${pubDate.toISOString()}`);\n console.log(` Age: ${ageInHours.toFixed(1)} hours`);\n \n if (ageInHours \u003c= hoursThreshold) {\n console.log(`\u2705 Item ${index} passed time filter`);\n return true;\n } else {\n console.log(`\u274c Item ${index} filtered out (too old)`);\n return false;\n }\n } catch (error) {\n console.log(`\u26a0\ufe0f Error processing item ${index}:`, error.message);\n return false;\n }\n});\n\nconsole.log(`After time filter: ${timeFilteredItems.length} items remaining`);\n\n// Step 2: Process items with URL extraction first, then deduplicate\nconst processedItems = timeFilteredItems.map((item, index) =\u003e {\n const originalUrl = item.json.link;\n const cleanUrl = extractCleanUrl(originalUrl);\n const normalizedTitle = normalizeTitle(item.json.title);\n \n return {\n json: {\n ...item.json,\n cleanUrl: cleanUrl,\n normalizedTitle: normalizedTitle\n }\n };\n});\n\n// Step 3: IMPROVED Deduplication using normalized titles\nconst seenItems = new Set();\nconst deduplicatedItems = processedItems.filter((item, index) =\u003e {\n const uniqueKey = item.json.normalizedTitle; // Just use normalized title for dedup\n \n console.log(`Checking item ${index} for duplicates:`);\n console.log(` Original title: \"${item.json.title}\"`);\n console.log(` Normalized title: \"${item.json.normalizedTitle}\"`);\n console.log(` Clean URL: \"${item.json.cleanUrl}\"`);\n \n if (seenItems.has(uniqueKey)) {\n console.log(`\ud83d\udd04 Duplicate found: \"${item.json.normalizedTitle}\" - removing`);\n return false;\n } else {\n seenItems.add(uniqueKey);\n console.log(`\u2705 Item ${index} is unique - keeping`);\n return true;\n }\n});\n\nconsole.log(`Final result: ${deduplicatedItems.length} items after time filter + dedup + URL extraction`);\nconsole.log(`Items being returned:`, deduplicatedItems.map(item =\u003e item.json.normalizedTitle));\n\n// Return the processed items\nreturn deduplicatedItems;"
},
"position": [
512,
528
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "063ced0f-8734-4243-9b60-84cd7311bdeb",
"name": "Merge",
"parameters": {
"numberInputs": 5
},
"position": [
352,
464
],
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2
},
{
"id": "6c3ed892-b53d-4d01-af2d-b4112e1ffebc",
"name": "prep simulation",
"parameters": {
"jsCode": "// Extract content and prepare Rally API payload - Using Clean Text Field\nlet rssData = {};\nlet httpData = {};\nlet toTextData = {};\n\ntry {\n rssData = $(\u0027filter\u0027).item.json || {};\n} catch (e) {\n console.log(\u0027No RSS data accessible:\u0027, e.message);\n}\n\ntry {\n httpData = $(\u0027HTTP: Get Content1\u0027).item.json || {};\n} catch (e) {\n console.log(\u0027No HTTP data accessible:\u0027, e.message);\n}\n\ntry {\n toTextData = $(\u0027to text\u0027).item.json || {};\n} catch (e) {\n console.log(\u0027No \u201cto text\u201d data accessible:\u0027, e.message);\n}\n\nconst sourceText = toTextData.text || \u0027\u0027;\nconst extractedTitle = httpData.title || \u0027\u0027;\nconst snippet = rssData.contentSnippet || rssData.content || rssData.summary || \u0027\u0027;\nconst articleUrl = rssData.cleanUrl || rssData.link || \u0027\u0027;\n\n// Select memory source, falling back to snippet if empty or JS-blocker\nconst badJsMsg = \u0027JavaScript is not available.\u0027;\nconst memorySource = (!sourceText || sourceText.startsWith(badJsMsg))\n ? snippet\n : sourceText;\n\n// \u2705 Wrap memory string in an object as required by Rally API\nconst memoryContent = [\n {\n content: `You\u0027ve just read this content: ${memorySource}`\n }\n];\n\n// Rally API payload\nconst rallyPayload = {\n smart: false,\n provider: \"google\",\n query: \"After reading with that content, has your willingness to allocate more budget toward REPLACE WITH YOUR PRODUCT CATEGORY\u2014especially REPLACE WITH YOUR SOLUTION TYPE? If so, how? A) I\u2019m now actively looking to increase spend in our REPLACE WITH YOUR PRODUCT CATEGORY efforts and AI personas B) I\u2019m more open than before, and would consider proposals I might have dismissed, C) No real change\u2014I still hold the same interest (or lack thereof) as before, D) I\u2019m now more skeptical or cautious about putting resources into REPLACE WITH YOUR PRODUCT CATEGORY, E) I\u2019ve become firmly opposed to spending resources on REPLACE WITH YOUR PRODUCT CATEGORY at this stage\",\n audience_id: \"REPLACE WITH YOUR AUDIENCE ID\",\n voting_mode: true,\n mode: \"fast\",\n manual_memories: memoryContent\n};\n\n// Return result\nreturn {\n title: extractedTitle || rssData.title || \"\",\n content: snippet,\n url: articleUrl,\n cleanTextLength: (httpData.text || \"\").length,\n usedCleanText: !!(httpData.text \u0026\u0026 httpData.text.length \u003e 200),\n rallyPayload: rallyPayload,\n debug: {\n sourceTextLength: sourceText.length,\n memorySourceFallbacked: memorySource === snippet,\n toTextDataFound: Object.keys(toTextData).length \u003e 0,\n rssDataFound: Object.keys(rssData).length \u003e 0,\n httpDataFound: Object.keys(httpData).length \u003e 0\n }\n};\n",
"mode": "runOnceForEachItem"
},
"position": [
1200,
400
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"credentials": {
"httpBearerAuth": {
"id": "WMmtEj2lQxOs84I8",
"name": "Bearer Auth account"
}
},
"id": "905e7b37-9f7e-4772-8a2b-7cec59a4b4f9",
"name": "call AskRally",
"parameters": {
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"jsonBody": "={{$json.rallyPayload}}",
"method": "POST",
"options": {
"batching": {
"batch": {
"batchInterval": 15000,
"batchSize": 1
}
}
},
"sendBody": true,
"sendHeaders": true,
"specifyBody": "json",
"url": "https://api.askrally.com/api/v1/chat"
},
"position": [
1600,
192
],
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2
},
{
"id": "24c3745b-5213-4389-a8b2-68e7cc3d9f97",
"name": "Sticky Note2",
"parameters": {
"content": "# Step 1: Get Recent News",
"height": 928,
"width": 616
},
"position": [
0,
0
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "8db6a373-d88b-4ef5-8a49-fb8dbc310ec9",
"name": "RSS Read6",
"parameters": {
"options": {}
},
"position": [
64,
144
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "21ea1d44-61e6-4089-bd16-87344d512a54",
"name": "Schedule Trigger1",
"parameters": {
"rule": {
"interval": [
{
"triggerAtHour": 1
}
]
}
},
"position": [
-288,
512
],
"type": "n8n-nodes-base.scheduleTrigger",
"typeVersion": 1.2
},
{
"id": "b33d1bcd-0183-4906-b03b-b22c262b063c",
"name": "RSS Read7",
"parameters": {
"options": {}
},
"position": [
64,
304
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "6083383a-fafb-419e-9614-a99c3c0bf776",
"name": "RSS Read8",
"parameters": {
"options": {}
},
"position": [
64,
464
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "35cb9f39-04c2-4071-bd44-fe199bdd3fc9",
"name": "RSS Read9",
"parameters": {
"options": {}
},
"position": [
64,
624
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
},
{
"id": "d7e385e9-e0fc-4fc9-b0ea-b112fb7b45de",
"name": "Sticky Note3",
"parameters": {
"color": 6,
"content": "# Step 3: Simulate Pipeline Impact From Industry News",
"height": 576,
"width": 900
},
"position": [
1184,
0
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"executeOnce": false,
"id": "dd51e998-7acf-4659-bd4c-52d30e5a0d98",
"maxTries": 2,
"name": "HTTP: Get Content1",
"onError": "continueErrorOutput",
"parameters": {
"headerParameters": {
"parameters": [
{
"name": "User-Agent",
"value": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
},
{
"name": "Accept",
"value": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
},
{
"name": "Accept-Language",
"value": "en-US,en;q=0.9"
},
{
"name": "Accept-Encoding",
"value": "gzip, deflate, br"
},
{
"name": "Connection",
"value": "keep-alive"
},
{
"name": "Upgrade-Insecure-Requests",
"value": "1"
}
]
},
"options": {
"redirect": {
"redirect": {
"maxRedirects": 2
}
},
"response": {
"response": {
"neverError": true
}
}
},
"sendHeaders": true,
"url": "={{ $json.cleanUrl }}"
},
"position": [
992,
528
],
"retryOnFail": false,
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2
},
{
"id": "e4d43673-3a30-4fdd-9f38-fbd6844cbe44",
"name": "to text",
"parameters": {
"jsCode": "// Simple HTML Text Extractor for n8n Code Node - Process All Items\n// Removes HTML tags and extracts clean text from any webpage\n\n// Get all input items using n8n syntax\nconst items = $input.all();\n\nconsole.log(`\ud83d\udd0d Processing ${items.length} items for text extraction`);\n\n// Simple but effective text extraction function\nfunction extractCleanText(html) {\n // Remove script and style elements completely\n let cleanHtml = html\n .replace(/\u003cscript\\b[^\u003c]*(?:(?!\u003c\\/script\u003e)\u003c[^\u003c]*)*\u003c\\/script\u003e/gi, \u0027\u0027)\n .replace(/\u003cstyle\\b[^\u003c]*(?:(?!\u003c\\/style\u003e)\u003c[^\u003c]*)*\u003c\\/style\u003e/gi, \u0027\u0027)\n .replace(/\u003cnav\\b[^\u003c]*(?:(?!\u003c\\/nav\u003e)\u003c[^\u003c]*)*\u003c\\/nav\u003e/gi, \u0027\u0027)\n .replace(/\u003cheader\\b[^\u003c]*(?:(?!\u003c\\/header\u003e)\u003c[^\u003c]*)*\u003c\\/header\u003e/gi, \u0027\u0027)\n .replace(/\u003cfooter\\b[^\u003c]*(?:(?!\u003c\\/footer\u003e)\u003c[^\u003c]*)*\u003c\\/footer\u003e/gi, \u0027\u0027)\n .replace(/\u003caside\\b[^\u003c]*(?:(?!\u003c\\/aside\u003e)\u003c[^\u003c]*)*\u003c\\/aside\u003e/gi, \u0027\u0027);\n \n // Extract title\n const titleMatch = cleanHtml.match(/\u003ctitle[^\u003e]*\u003e([^\u003c]+)\u003c\\/title\u003e/i);\n const title = titleMatch ? titleMatch[1].trim() : \u0027No title found\u0027;\n \n // Remove all HTML tags\n let text = cleanHtml\n .replace(/\u003c[^\u003e]+\u003e/g, \u0027 \u0027) // Remove all HTML tags\n .replace(/\u0026nbsp;/gi, \u0027 \u0027) // Replace \u0026nbsp; with space\n .replace(/\u0026amp;/gi, \u0027\u0026\u0027) // Replace \u0026amp; with \u0026\n .replace(/\u0026lt;/gi, \u0027\u003c\u0027) // Replace \u0026lt; with \u003c\n .replace(/\u0026gt;/gi, \u0027\u003e\u0027) // Replace \u0026gt; with \u003e\n .replace(/\u0026quot;/gi, \u0027\"\u0027) // Replace \u0026quot; with \"\n .replace(/\u0026#\\d+;/g, \u0027 \u0027) // Remove other HTML entities\n .replace(/\\s+/g, \u0027 \u0027) // Replace multiple spaces with single space\n .trim();\n \n // Filter out common unwanted text patterns\n const unwantedPatterns = [\n /cookie/i, /advertisement/i, /subscribe/i, /newsletter/i,\n /privacy policy/i, /terms of service/i, /follow us/i, /share this/i\n ];\n \n // Split into sentences and filter\n const sentences = text.split(/[.!?]+/).filter(sentence =\u003e {\n const s = sentence.trim();\n if (s.length \u003c 20) return false; // Skip very short sentences\n if (unwantedPatterns.some(pattern =\u003e pattern.test(s))) return false; // Skip unwanted content\n return true;\n });\n \n return {\n title: title,\n text: sentences.join(\u0027. \u0027).trim(),\n sentences: sentences,\n originalLength: html.length,\n cleanLength: text.length\n };\n}\n\n// Process all items and return array of results\nconst results = [];\n\nfor (let i = 0; i \u003c items.length; i++) {\n const item = items[i];\n \n try {\n // Get the HTML content from current item\n const html = item.binary?.data\n ? Buffer.from(item.binary.data.data, \u0027base64\u0027).toString()\n : item.json.body || item.json.data || item.json.html;\n\n const url = item.json.url || `Item ${i + 1}`;\n \n console.log(`\ud83d\udcc4 Processing item ${i + 1}/${items.length}: ${url}`);\n console.log(` HTML length: ${html.length} characters`);\n \n const extracted = extractCleanText(html);\n \n console.log(` \u2705 Extracted: \"${extracted.title}\"`);\n console.log(` \ud83d\udcdd Clean text: ${extracted.cleanLength} characters`);\n console.log(` \ud83d\udcc4 Found ${extracted.sentences.length} sentences`);\n \n results.push({\n // Preserve original item data\n ...item.json,\n // Add extracted text data\n title: extracted.title,\n text: extracted.text,\n sentences: extracted.sentences,\n url: url,\n wordCount: extracted.text.split(/\\s+/).length,\n sentenceCount: extracted.sentences.length,\n compressionRatio: Math.round((extracted.cleanLength / extracted.originalLength) * 100),\n success: true,\n itemIndex: i\n });\n \n } catch (error) {\n console.error(`\u274c Error processing item ${i + 1}:`, error.message);\n \n results.push({\n // Preserve original item data\n ...item.json,\n // Add error data\n title: \u0027Error\u0027,\n text: \u0027\u0027,\n url: item.json.url || `Item ${i + 1}`,\n wordCount: 0,\n success: false,\n error: error.message,\n itemIndex: i\n });\n }\n}\n\nconsole.log(`\ud83c\udf89 Completed processing ${results.length} items`);\n\nreturn results.map(item =\u003e ({ json: item }));\n"
},
"position": [
992,
400
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "fd62f833-3052-4641-9776-cf13220665d9",
"name": "Sticky Note8",
"parameters": {
"color": 5,
"content": "# Step 4: Marketing Agent",
"height": 348,
"width": 1080
},
"position": [
1184,
592
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "830bd230-5d46-4a11-9829-078e2f9c8796",
"name": "Code3",
"parameters": {
"jsCode": "// ==== Code3: Flatten + add vote\u2010legend \u2192 LLM payload ====\n// Settings: \u201cRun Once for All Items\u201d\n\n// 1) Grab the single digest in\nconst digest = $input.all()[0].json;\n\n// 2) Pull out sims + quotes just like before\nconst simsArr = Array.isArray(digest.simulations) ? digest.simulations : [];\nconst quotesArr = Array.isArray(digest.sampledQuotes) ? digest.sampledQuotes : [];\n\n// 3) Build your simulation_results array\nconst simulation_results = simsArr.map((sim, idx) =\u003e {\n // parse percentages from breakdown string\n const breakdown = sim.detailedResults?.breakdown || \"\";\n const percentages = breakdown.split(\",\").reduce((acc, part) =\u003e {\n const [k, v] = part.split(\":\");\n if (k \u0026\u0026 v) acc[k.trim()] = parseInt(v,10);\n return acc;\n }, {});\n\n // flatten pro/neutral/contra quotes into one list\n const bucket = (quotesArr[idx]?.quotes) || {};\n const sampleResponses = [\n ...(bucket.pro || []).map(t =\u003e ({ option: \"A\", thinking: t })),\n ...(bucket.neutral|| []).map(t =\u003e ({ option: \"C\", thinking: t })),\n ...(bucket.contra || []).map(t =\u003e ({ option: \"D\", thinking: t })),\n ];\n\n return {\n percentages,\n summary: sim.summary || \"\",\n sampleResponses,\n };\n});\n\n// 4) Attach a 2\u2011word legend so the LLM knows what A\u2013E stand for\nconst voteLegend = {\n A: \"Increase Spend\",\n B: \"Open to Proposals\",\n C: \"No Change\",\n D: \"More Cautious\",\n E: \"Firmly Opposed\"\n};\n\n// 5) Return exactly one output item\nreturn [\n {\n json: {\n voteLegend,\n simulation_results\n }\n }\n];\n"
},
"position": [
1664,
688
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"credentials": {
"openAiApi": {
"id": "aEwEH5APyXx6cq8g",
"name": "OpenAi account"
}
},
"id": "02b62d1e-1d1a-45dd-acc3-32d28d59a8b7",
"name": "Message a model4",
"parameters": {
"jsonOutput": true,
"messages": {
"values": [
{
"content": "You are a B2B GTM strategist.\n\nTASK \n-----\nParse *every* simulation\u2019s `percentages` and `sampleResponses`.\n\n1. **Theme mining** \n \u2022 List the narrative motifs that appear in \u2265 2 \u201cA/B\u201d comments (what excites buyers). \n \u2022 List the motifs that appear in \u2265 2 \u201cD/E\u201d comments (what scares buyers aka objections). \n \u2022 For each motif give a one-line proof quote (trimmed) and a tally of how many times it shows up.\n\n2. **Counter-intuition hunt** \n \u2022 Compare the two lists. Look for a pattern that is *not* obvious from headline voting alone \n \u2022 Formulate one commercially valuable insight for Ask Rally: a sentence that reveals this hidden tension and how to exploit it in messaging.\n\n3. **Craft two memes** \n \u2022 *meme_to_boost* \u2013 \u003c60 chars; amplifies a winning motif. \n \u2022 *meme_to_nuke* \u2013 \u003c60 chars; disarms a losing motif.\n\nOUTPUT \n------\nReturn **only** a JSON object that follows exactly this schema \u0026 order\n(keep keys snake_case, no extra keys, max 280 chars total per string):\n\n```json\n{\n \"insight\": \"string\",\n \"meme_to_boost\": \"string\",\n \"meme_to_nuke\": \"string\",\n \"objections\": \"string\",\n}\n\u2022 Do not summarise anything outside the JSON.\n\n",
"role": "=system"
},
{
"content": "=\u201csimulation_results\u201d: \u201csimulation_results\u201d: {{ JSON.stringify(\n $json.simulation_results.map(\n ({ percentages, summary, sampleResponses }) =\u003e\n ({ percentages, summary, sampleResponses })\n ),\n null,\n 2\n) }}\n"
}
]
},
"modelId": {
"__rl": true,
"cachedResultName": "O3-MINI",
"mode": "list",
"value": "o3-mini"
},
"options": {},
"simplify": false
},
"position": [
1872,
688
],
"type": "@n8n/n8n-nodes-langchain.openAi",
"typeVersion": 1.8
},
{
"id": "c450b19b-2a5a-4a7c-87fb-a73609c41e68",
"name": "Sticky Note",
"parameters": {
"color": 5,
"content": "This step extract insights and think up meme ideas. \n\nTip: tweak the prompts\n",
"height": 120,
"width": 200
},
"position": [
1840,
800
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "0461ded5-8a7b-4437-ad7f-8499aaace5fc",
"name": "Sticky Note15",
"parameters": {
"color": 4,
"content": "## Step5: Generate Digest\n",
"height": 336,
"width": 772
},
"position": [
2096,
240
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "a9d3cd38-e01f-4c8b-97df-cd37779d5bf0",
"name": "Merge2",
"parameters": {
"combineBy": "combineByPosition",
"mode": "combine",
"options": {}
},
"position": [
1952,
320
],
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2
},
{
"id": "52a69c8e-4e28-4020-a44b-9f00f041772c",
"name": "Merge3",
"parameters": {
"combineBy": "combineByPosition",
"mode": "combine",
"options": {}
},
"position": [
2448,
336
],
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2
},
{
"id": "a46dc571-48b4-4492-80de-06a31b441f7f",
"name": "Drop failed",
"parameters": {
"jsCode": "// 1) Grab all incoming items\nconst allItems = $input.all();\n\n// 2) Keep only the truly valid HTML pages\nconst items = allItems.filter(item =\u003e {\n // a) Drop any n8n\u2011level errors (Continue On Fail)\n if (item.error) {\n console.log(\u0027\ud83d\udd34 Dropping item due to n8n error:\u0027, item.error.message);\n return false;\n }\n // b) If we have an HTTP statusCode, enforce 2xx\n if (item.json \u0026\u0026 typeof item.json.statusCode !== \u0027undefined\u0027) {\n const code = Number(item.json.statusCode);\n if (isNaN(code) || code \u003c 200 || code \u003e= 300) {\n console.log(`\ud83d\udd34 Dropping item with statusCode=${code}`);\n return false;\n }\n }\n // c) Pull out the raw HTML so we can sniff for CAPTCHA pages\n const html = item.binary?.data\n ? Buffer.from(item.binary.data.data, \u0027base64\u0027).toString()\n : (item.json.body || item.json.data || item.json.html || \u0027\u0027);\n\n // d) Drop any \u201cAccess to this page has been denied\u201d challenge\n if (/Access to this page has been denied/i.test(html)) {\n console.log(\u0027\ud83d\udd34 Dropping CAPTCHA/challenge page\u0027);\n return false;\n }\n\n return true;\n});\n\nconsole.log(`\u2705 Processing ${items.length} successful items (no errors, 2xx, no captcha)`);\n\n\n// 3) HTML \u2192 clean text extractor\nfunction extractCleanText(html) {\n const cheerio = require(\u0027cheerio\u0027);\n const $ = cheerio.load(html);\n $(\u0027script, style, noscript\u0027).remove();\n const title = $(\u0027title\u0027).text().trim();\n const text = $(\u0027body\u0027).text().replace(/\\s+/g, \u0027 \u0027).trim();\n return { title, text };\n}\n\n\n// 4) Map each filtered item \u2192 { json: \u2026 }\nconst results = items.map((item, idx) =\u003e {\n const out = { ...item.json };\n\n try {\n // grab HTML from binary or known JSON fields\n const html = item.binary?.data\n ? Buffer.from(item.binary.data.data, \u0027base64\u0027).toString()\n : (item.json.body || item.json.data || item.json.html || \u0027\u0027);\n\n const { title, text } = extractCleanText(html);\n out.title = title;\n out.text = text;\n out.success = true;\n } catch (err) {\n out.success = false;\n out.error = err.message;\n }\n\n out.itemIndex = idx;\n return { json: out };\n});\n\nreturn results;\n"
},
"position": [
832,
400
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "60a9d774-4448-4e58-a5b8-93e867d96cb7",
"name": "Loop Over Items",
"parameters": {
"options": {}
},
"position": [
688,
528
],
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3
},
{
"id": "957bbd58-0e80-4c51-b599-3a2fe44c0010",
"name": "Wait",
"parameters": {},
"position": [
832,
528
],
"type": "n8n-nodes-base.wait",
"typeVersion": 1.1,
"webhookId": "3d268d0f-46f7-40c0-b868-49fe8a77904b"
},
{
"credentials": {
"gmailOAuth2": {
"id": "TBaldf4YTqggVfDo",
"name": "Gmail account"
}
},
"id": "6b01351a-a96a-4078-86c6-a5b9b5955b81",
"name": "Send a message",
"parameters": {
"message": "=\u003cdiv style=\"font-family: Arial, sans-serif; max-width: 800px; margin: 0 auto; padding: 20px; background-color: #f8f9fa;\"\u003e\n\n \u003c!-- Header Section --\u003e\n \u003cdiv style=\"background-color: #c4d8bb; color: #32466c; padding: 30px; border-radius: 12px; margin-bottom: 30px; text-align: center;\"\u003e\n \u003ch1 style=\"margin: 0 0 10px 0; font-size: 28px; font-weight: bold;\"\u003e\ud83d\udce3 AskRally Industry Daily Digest \ud83d\uddde\ufe0f\u003c/h1\u003e\n \u003c/div\u003e\n \n \u003c!-- Analytics Section --\u003e\n \u003cdiv style=\"background-color: #ffffff; border-radius: 12px; padding: 25px; margin-bottom: 30px; box-shadow: 0 2px 8px rgba(0,0,0,0.1);\"\u003e\n \u003ch2 style=\"color: #333; margin-top: 0; margin-bottom: 20px; font-size: 24px; border-bottom: 3px solid #667eea; padding-bottom: 10px;\"\u003e\n \ud83d\udcc8 Analytics\n \u003c/h2\u003e\n \n \u003cdiv style=\"display: grid; grid-template-columns: repeat(auto-fit, minmax(180px, 1fr)); gap: 16px;\"\u003e\n \n \u003cdiv style=\"background-color: #f2d091; color: #243B6E; padding: 24px 18px; border-radius: 14px; text-align: center; font-weight: 600; box-shadow: 0 2px 4px rgba(36,59,110,0.08);\"\u003e\n \u003cdiv style=\"font-size: 32px; font-weight: bold; margin-bottom: 5px;\"\u003e{{ $json.analytics.simulations }}\u003c/div\u003e\n \u003cdiv style=\"font-size: 14px; text-transform: uppercase; letter-spacing: 1px;\"\u003eMedia Simulated\u003c/div\u003e\n \u003c/div\u003e\n \n \u003cdiv style=\"background: linear-gradient(135deg, #E0EEFC 0%, #B7CFE8 100%); color: #243B6E; padding: 24px 18px; border-radius: 14px; text-align: center; font-weight: 600; box-shadow: 0 2px 4px rgba(36,59,110,0.08);\"\u003e\n \u003cdiv style=\"font-size: 32px; font-weight: bold; margin-bottom: 5px;\"\u003e{{ $json.analytics.respondents }}\u003c/div\u003e\n \u003cdiv style=\"font-size: 14px; text-transform: uppercase; letter-spacing: 1px;\"\u003eRespondents\u003c/div\u003e\n \u003c/div\u003e\n \n \u003cdiv style=\"background: linear-gradient(135deg, #E6F5F2 0%, #C4E4DF 100%); color: #243B6E; padding: 24px 18px; border-radius: 14px; text-align: center; font-weight: 600; box-shadow: 0 2px 4px rgba(36,59,110,0.08);\"\u003e\n \u003cdiv style=\"font-size: 32px; font-weight: bold; margin-bottom: 5px;\"\u003e\n {{ Math.round(($json.analytics.proVotes / $json.analytics.respondents) * 100) }}%\n \u003c/div\u003e\n \u003cdiv style=\"font-size: 14px; text-transform: uppercase; letter-spacing: 1px;\"\u003ePro Narrative Votes (A/B)\u003c/div\u003e\n \u003cdiv style=\"font-size: 12px; opacity: 0.7; margin-top: 3px;\"\u003e{{ $json.analytics.proVotes }} votes\u003c/div\u003e\n \u003c/div\u003e\n \n \u003cdiv style=\"background: linear-gradient(135deg, #F1F4F7 0%, #D8DEE7 100%); color: #243B6E; padding: 24px 18px; border-radius: 14px; text-align: center; font-weight: 600; box-shadow: 0 2px 4px rgba(36,59,110,0.08);\"\u003e\n \u003cdiv style=\"font-size: 32px; font-weight: bold; margin-bottom: 5px;\"\u003e\n {{ Math.round(($json.analytics.contraVotes / $json.analytics.respondents) * 100) }}%\n \u003c/div\u003e\n \u003cdiv style=\"font-size: 14px; text-transform: uppercase; letter-spacing: 1px;\"\u003eContra Narrative Votes (D/E)\u003c/div\u003e\n \u003cdiv style=\"font-size: 12px; opacity: 0.7; margin-top: 3px;\"\u003e{{ $json.analytics.contraVotes }} votes\u003c/div\u003e\n \u003c/div\u003e\n \n \u003c/div\u003e\n \u003c/div\u003e\n \u003c!-- Key Takeaway Section --\u003e\n\u003cdiv style=\"background-color: #ffffff; border-radius: 12px; padding: 25px; margin-bottom: 30px; box-shadow: 0 2px 8px rgba(0,0,0,0.1);\"\u003e\n \u003ch2 style=\"color: #333; margin-top: 0; margin-bottom: 20px; font-size: 24px; border-bottom: 3px solid #667eea; padding-bottom: 10px;\"\u003e\n \ud83d\udca1 Key Takeaway\n \u003c/h2\u003e\n\n \u003cp style=\"color: #495057; line-height: 1.5; margin-bottom: 15px;\"\u003e\n {{ $json.choices[0].message.content.insight }}\n \u003c/p\u003e\n\n \u003cdiv style=\"display: grid; grid-template-columns: 1fr 1fr; gap: 16px;\"\u003e\n \u003cdiv style=\"background-color: #e8f5e9; padding: 20px; border-radius: 8px;\"\u003e\n \u003cstrong style=\"display: block; margin-bottom: 8px;\"\u003eBoost the meme:\u003c/strong\u003e\n {{ $json.choices[0].message.content.meme_to_boost }}\n {{ $json.choices[0].message.content.meme_to_nuke }}\n \u003c/div\u003e\n\n \u003cdiv style=\"background-color: #ffebee; padding: 20px; border-radius: 8px;\"\u003e\n \u003cstrong style=\"display: block; margin-bottom: 8px;\"\u003eObjections:\u003c/strong\u003e\n {{ $json.choices[0].message.content.objections }}\n \u003c/div\u003e\n \u003c/div\u003e\n\u003c/div\u003e\n\n \u003c!-- Simulations Section --\u003e\n \u003cdiv style=\"background-color: #ffffff; border-radius: 12px; padding: 25px; margin-bottom: 30px; box-shadow: 0 2px 8px rgba(0,0,0,0.1);\"\u003e\n \u003ch2 style=\"color: #333; margin-top: 0; margin-bottom: 20px; font-size: 24px; border-bottom: 3px solid #667eea; padding-bottom: 10px;\"\u003e\n \ud83d\udd2c Simulations\n \u003c/h2\u003e\n \n {{\n (() =\u003e {\n const simulations = $json.simulations || [];\n if (simulations.length === 0) {\n return \u0027\u003cp style=\"color: #6c757d; font-style: italic;\"\u003eNo simulations found for today.\u003c/p\u003e\u0027;\n }\n \n let html = \u0027\u0027;\n simulations.forEach((sim, index) =\u003e {\n // Determine result type styling\n let resultBadgeStyle = \u0027\u0027;\n let resultIcon = \u0027\u0027;\n \n if (sim.resultType === \u0027pro-narrative\u0027) {\n resultBadgeStyle = \u0027background: linear-gradient(135deg, #56ab2f 0%, #a8e6cf 100%); color: white;\u0027;\n resultIcon = \u0027\ud83d\udfe2\u0027;\n } else if (sim.resultType === \u0027contra-narrative\u0027) {\n resultBadgeStyle = \u0027background: linear-gradient(135deg, #ff6b6b 0%, #feca57 100%); color: white;\u0027;\n resultIcon = \u0027\ud83d\udd34\u0027;\n } else {\n resultBadgeStyle = \u0027background: linear-gradient(135deg, #74b9ff 0%, #0984e3 100%); color: white;\u0027;\n resultIcon = \u0027\u26aa\u0027;\n }\n \n // Create the article URL with fallback\n const articleUrl = sim.articleUrl \u0026\u0026 sim.articleUrl !== \u0027#\u0027 ? sim.articleUrl : \u0027#\u0027;\n \n html += `\n \u003cdiv style=\"border: 1px solid #e9ecef; border-radius: 8px; padding: 20px; margin-bottom: 20px; background: linear-gradient(135deg, #f8f9fa 0%, #ffffff 100%);\"\u003e\n \n \u003cdiv style=\"display: flex; align-items: center; margin-bottom: 15px;\"\u003e\n \u003cspan style=\"${resultBadgeStyle} padding: 6px 12px; border-radius: 20px; font-size: 12px; font-weight: bold; margin-right: 10px;\"\u003e\n ${resultIcon} ${sim.resultType.toUpperCase().replace(\u0027-\u0027, \u0027 \u0027)}\n \u003c/span\u003e\n \u003c/div\u003e\n \n \u003ch3 style=\"margin: 0 0 10px 0; font-size: 18px; line-height: 1.4;\"\u003e\n \ud83d\udcc4 \u003ca href=\"${articleUrl}?utm_source=api\u0026utm_medium=email\u0026utm_campaign=daily-digest\" style=\"color: #495057; text-decoration: none;\"\u003e${sim.title}\u003c/a\u003e\n \u003c/h3\u003e\n \n \u003cdiv style=\"background-color: #f8f9fa; padding: 15px; border-radius: 6px; margin-bottom: 15px;\"\u003e\n \u003cstrong style=\"color: #495057;\"\u003eResults:\u003c/strong\u003e ${sim.results}\n \u003cbr\u003e\n \u003csmall style=\"color: #6c757d; margin-top: 5px; display: block;\"\u003e\n ${sim.detailedResults.breakdown} | Total Voters: ${sim.detailedResults.totalVoters}\n \u003c/small\u003e\n \u003c/div\u003e\n \n \u003cdiv style=\"border-left: 4px solid #667eea; padding-left: 15px;\"\u003e\n \u003cstrong style=\"color: #495057;\"\u003eSummary:\u003c/strong\u003e\n \u003cp style=\"margin: 8px 0 0 0; color: #495057; line-height: 1.5; font-style: italic;\"\u003e\n \"${sim.summary}\"\n \u003c/p\u003e\n \u003c/div\u003e\n \n \u003c/div\u003e`;\n });\n \n return html;\n })()\n }}\n \u003c/div\u003e\n \n \u003c!-- Sampled Quotes Section (simplified) --\u003e\n \u003cdiv style=\"background-color:#ffffff;border-radius:12px;padding:25px;margin-bottom:30px;box-shadow:0 2px 8px rgba(0,0,0,0.1);\"\u003e\n \u003ch2 style=\"color:#333;margin-top:0;margin-bottom:20px;font-size:24px;border-bottom:3px solid #667eea;padding-bottom:10px;\"\u003e\n \ud83d\udcac Sampled Quotes\n \u003c/h2\u003e\n {{\n (() =\u003e {\n const sq = $json.sampledQuotes || [];\n if (!sq.length) {\n return \u0027\u003cp style=\"color:#6c757d;font-style:italic;\"\u003eNo quotes available for today.\u003c/p\u003e\u0027;\n }\n let html = \u0027\u0027;\n sq.forEach(article =\u003e {\n const url = article.articleUrl \u0026\u0026 article.articleUrl!==\u0027#\u0027\n ? article.articleUrl\n : \u0027#\u0027;\n html += `\n \u003cdiv style=\"border:1px solid #e9ecef;border-radius:8px;padding:20px;margin-bottom:25px;background:#fafafa;\"\u003e\n \u003ch3 style=\"margin:0 0 20px;font-size:16px;font-weight:bold;\"\u003e\n \ud83d\udcc4 \u003ca href=\"${url}?utm_source=api\u0026utm_medium=email\u0026utm_campaign=daily-digest\"\n style=\"color:#495057;text-decoration:none;\"\u003e\n ${article.title}\n \u003c/a\u003e\n \u003c/h3\u003e\n \u003cdiv style=\"display:grid;gap:15px;\"\u003e`;\n\n // Pro Narrative\n if (article.quotes.pro?.length) {\n html += `\n \u003cdiv style=\"background:linear-gradient(135deg,#d4edda,#c3e6cb);\n border-left:4px solid #28a745;padding:15px;border-radius:6px;\"\u003e\n \u003ch4 style=\"margin:0 0 10px;color:#155724;font-size:14px;font-weight:bold;\"\u003e\n \ud83d\udfe2 Pro Narrative (${article.quotes.pro.length} quotes)\n \u003c/h4\u003e`;\n article.quotes.pro.forEach(text =\u003e {\n html += `\n \u003cdiv style=\"background:rgba(255,255,255,0.7);padding:10px;border-radius:4px;margin-bottom:8px;\"\u003e\n \u003cp style=\"margin:0;color:#155724;\"\u003e\"${text}\"\u003c/p\u003e\n \u003c/div\u003e`;\n });\n html += `\u003c/div\u003e`;\n }\n\n // Contra Narrative\n if (article.quotes.contra?.length) {\n html += `\n \u003cdiv style=\"background:linear-gradient(135deg,#f8d7da,#f5c6cb);\n border-left:4px solid #dc3545;padding:15px;border-radius:6px;\"\u003e\n \u003ch4 style=\"margin:0 0 10px;color:#721c24;font-size:14px;font-weight:bold;\"\u003e\n \ud83d\udd34 Contra Narrative (${article.quotes.contra.length} quotes)\n \u003c/h4\u003e`;\n article.quotes.contra.forEach(text =\u003e {\n html += `\n \u003cdiv style=\"background:rgba(255,255,255,0.7);padding:10px;border-radius:4px;margin-bottom:8px;\"\u003e\n \u003cp style=\"margin:0;color:#721c24;\"\u003e\"${text}\"\u003c/p\u003e\n \u003c/div\u003e`;\n });\n html += `\u003c/div\u003e`;\n }\n\n // Neutral\n if (article.quotes.neutral?.length) {\n html += `\n \u003cdiv style=\"background:linear-gradient(135deg,#fff3cd,#ffeaa7);\n border-left:4px solid #ffc107;padding:15px;border-radius:6px;\"\u003e\n \u003ch4 style=\"margin:0 0 10px;color:#856404;font-size:14px;font-weight:bold;\"\u003e\n \u26aa Neutral (${article.quotes.neutral.length} quotes)\n \u003c/h4\u003e`;\n article.quotes.neutral.forEach(text =\u003e {\n html += `\n \u003cdiv style=\"background:rgba(255,255,255,0.7);padding:10px;border-radius:4px;margin-bottom:8px;\"\u003e\n \u003cp style=\"margin:0;color:#856404;\"\u003e\"${text}\"\u003c/p\u003e\n \u003c/div\u003e`;\n });\n html += `\u003c/div\u003e`;\n }\n\n html += `\n \u003c/div\u003e\n \u003c/div\u003e`;\n });\n return html;\n })()\n }}\n \u003c/div\u003e \n \u003c!-- Footer --\u003e\n \u003cdiv style=\"background-color: #6c757d; color: white; padding: 20px; border-radius: 12px; text-align: center;\"\u003e\n \u003cp style=\"margin: 0; font-size: 14px; opacity: 0.8;\"\u003e\n Powered by \u003ca href=\"https://askrally.com/?utm_source=api\u0026utm_medium=email\u0026utm_campaign=daily-digest\" style=\"color: #ffffff; text-decoration: none; font-weight: bold;\"\u003eAskRally.com\u003c/a\u003e\n \u003c/p\u003e\n \u003c/div\u003e\n \n \u003c/div\u003e ",
"options": {},
"sendTo": "rhys@irrealitylabs.com",
"subject": "=\ud83d\udce3 AskRally Daily Digest \ud83d\uddde\ufe0f | {{ $json.date }}"
},
"position": [
2656,
336
],
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"webhookId": "d47ea3ca-9545-4638-a6f5-b25374cf0760"
},
{
"id": "669d195f-af62-4b55-8730-91074f83185f",
"name": "Loop Over Items1",
"parameters": {
"batchSize": 5,
"options": {}
},
"position": [
1472,
80
],
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3
},
{
"id": "db423d3d-e34d-4904-8c49-bc6537434315",
"name": "vote\u2011parsing, sampling and analytics",
"parameters": {
"jsCode": "// ==== Daily Digest Generator ====\n// This script ALWAYS returns exactly one output item: [{ json: digest }]\n\n// 1) Collect all incoming items into a simple array of JSON payloads\nconst items = $input.all().map(i =\u003e i.json);\nconst today = new Date().toISOString().split(\u0027T\u0027)[0];\n\n// 2) Helper: process one Rally result\nfunction processResult(data) {\n const raw = Array.isArray(data.responses) ? data.responses : [];\n\n // Tally votes (support both flat vote \u0026 JSON response formats)\n const voteCounts = raw.reduce((acc, r) =\u003e {\n let opt = r.vote\n || (() =\u003e {\n try { return JSON.parse(r.response).option } catch { return null }\n })();\n if (opt \u0026\u0026 acc.hasOwnProperty(opt)) acc[opt]++;\n return acc;\n }, { A: 0, B: 0, C: 0, D: 0, E: 0 });\n\n const totalVoters = raw.length;\n const percentages = {};\n for (const o of Object.keys(voteCounts)) {\n percentages[o] = totalVoters \n ? Math.round(100 * voteCounts[o] / totalVoters) \n : 0;\n }\n\n const proNarrative = percentages.A + percentages.B;\n const contraNarrative = percentages.D + percentages.E;\n const neutral = percentages.C;\n\n // Build parsed array of { persona_id, option, thinking }\n const parsed = raw.map(r =\u003e {\n let thinking, opt = r.vote;\n try {\n const d = JSON.parse(r.response);\n if (!opt) opt = d.option;\n thinking = d.thinking || r.response || \u0027\u0027;\n } catch {\n thinking = r.response || \u0027\u0027;\n }\n return { persona_id: r.persona_id, option: opt, thinking };\n });\n\n // Sample up to 5 from each bucket\n function pick(arr, n) {\n return arr.sort(() =\u003e 0.5 - Math.random()).slice(0, n);\n }\n const sampleQuotes = {\n pro: pick(parsed.filter(x =\u003e [\u0027A\u0027,\u0027B\u0027].includes(x.option)), 5),\n contra: pick(parsed.filter(x =\u003e [\u0027D\u0027,\u0027E\u0027].includes(x.option)), 5),\n neutral:pick(parsed.filter(x =\u003e x.option === \u0027C\u0027), 5),\n };\n\n // Determine narrative type\n let resultType = \u0027mixed\u0027;\n if (proNarrative \u003e= 75) resultType = \u0027pro-narrative\u0027;\n else if (contraNarrative \u003e= 75) resultType = \u0027contra-narrative\u0027;\n\n return {\n session_id: data.session_id,\n title: data.title,\n articleUrl: data.url,\n totalVoters,\n voteCounts,\n percentages,\n proNarrative,\n contraNarrative,\n neutral,\n resultType,\n summary: data.summary || \u0027\u0027,\n sampleQuotes,\n analytics: {\n totalVoters,\n proVotes: voteCounts.A + voteCounts.B,\n contraVotes: voteCounts.D + voteCounts.E,\n neutralVotes: voteCounts.C,\n }\n };\n}\n\n// 3) Run all simulations through the helper\nconst sims = items.map(processResult);\n\n// 4) Top\u2011level analytics\nconst analytics = sims.reduce((a, s) =\u003e {\n a.simulations++;\n a.respondents += s.analytics.totalVoters;\n a.proVotes += s.analytics.proVotes;\n a.contraVotes += s.analytics.contraVotes;\n return a;\n}, { simulations:0, respondents:0, proVotes:0, contraVotes:0 });\n\n// 5) Build the \u201csimulations\u201d array for the email template\nconst simulations = sims.map(s =\u003e ({\n title: s.title,\n articleUrl: s.articleUrl,\n results: `${s.proNarrative}% Pro | ${s.contraNarrative}% Contra | ${s.neutral}% Neutral`,\n detailedResults: {\n totalVoters: s.totalVoters,\n breakdown: `A: ${s.percentages.A}%, B: ${s.percentages.B}%, C: ${s.percentages.C}%, D: ${s.percentages.D}%, E: ${s.percentages.E}%`\n },\n summary: s.summary,\n resultType:s.resultType\n}));\n\n// 6) Build the sampled\u2011quotes section (2 per sentiment)\nconst sampledQuotes = sims.map(s =\u003e ({\n title: s.title,\n articleUrl: s.articleUrl,\n quotes: {\n pro: s.sampleQuotes.pro.slice(0,2).map(q =\u003e q.thinking),\n contra: s.sampleQuotes.contra.slice(0,2).map(q =\u003e q.thinking),\n neutral: s.sampleQuotes.neutral.slice(0,2).map(q =\u003e q.thinking),\n }\n}));\n\n// 7) Subject line \u0026 summaryStats\nconst avgProNarr = sims.length\n ? Math.round(sims.reduce((sum,s)=\u003e sum + s.proNarrative, 0) / sims.length)\n : 0;\nconst topResultType = sims.reduce((ct, s) =\u003e {\n ct[s.resultType] = (ct[s.resultType]||0) + 1;\n return ct;\n}, {});\n\n// 8) The final digest object\nconst digest = {\n date: today,\n analytics,\n simulations,\n sampledQuotes,\n skipEmail: simulations.length === 0,\n subject: `Rally Research Daily Digest \u2013 ${new Date().toLocaleDateString(\u0027en-US\u0027, {\n weekday:\u0027long\u0027, month:\u0027long\u0027, day:\u0027numeric\u0027, year:\u0027numeric\u0027\n })}`,\n summaryStats: {\n totalSimulations: analytics.simulations,\n totalRespondents: analytics.respondents,\n avgProNarrative: avgProNarr,\n topResultType\n }\n};\n\n// 9) **Return exactly one output item** as an array\nreturn [ { json: digest } ];\n"
},
"position": [
2160,
320
],
"type": "n8n-nodes-base.code",
"typeVersion": 2
},
{
"id": "4a3de939-0f13-4450-929f-8c8acb8d243e",
"name": "Sticky Note5",
"parameters": {
"color": 3,
"content": "# Step 2: Extract Media",
"height": 480,
"width": 520
},
"position": [
640,
272
],
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1
},
{
"id": "b2027cb5-516c-4016-8a6c-e5cb361b8246",
"name": "RSS Read10",
"parameters": {
"options": {}
},
"position": [
64,
784
],
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1.2
}
],
"pinData": {
"Schedule Trigger1": [
{
"json": {
"Day of month": "01",
"Day of week": "Tuesday",
"Hour": "01",
"Minute": "00",
"Month": "July",
"Readable date": "July 1st 2025, 1:00:02 am",
"Readable time": "1:00:02 am",
"Second": "02",
"Timezone": "America/New_York (UTC-04:00)",
"Year": "2025",
"timestamp": "2025-07-01T01:00:02.011-04:00"
}
}
]
},
"settings": {
"executionOrder": "v1"
},
"tags": [],
"versionId": "1a16874c-7fa7-4d63-8127-94ec7bf7e5a5"
}About the Author
Rhys Fisher
Rhys Fisher is the COO & Co-Founder of Rally. He previously co-founded a boutique analytics agency called Unvanity, crossed the Pyrenees coast-to-coast via paraglider, and now watches virtual crowds respond to memes. Follow him on Twitter @virtual_rf
