
I have two co-founders, Rhys who lives in Holland, and Chris who lives in the USA.
Here’s a thought experiment I used to explain a problem that plagues synthetic research, which we now refer to internally as the ‘Dutch Chris’ problem.
Say we did a survey of the three of us, but we only saved the aggregate results, not the individual records of who answered what. We would know 1/3rd in Holland (NL), 1/3rd in the UK, 1/3rd in the USA, all male, average age was 38, 2 engineers and 1 marketer, etc.
If we wanted to recreate that study with AI personas, we’d first need to take the aggregate statistics (age, gender, location, job, hobbies) and reconstruct the personas in a way that adds up to the right values. So for example:
-
Persona A: age 37, lives in UK, Male, engineer, likes travel
-
Persona B: age 38, lives in NL, Male, engineer, likes sports cars
-
Persona C: age 39, lives in US, Male, marketer, likes paragliding
You run the survey again with these AI personas, and if you do everything right you get similar responses to what the humans gave you in real life. Then you can ask new questions for this audience and trust that the responses you get are realistic.
However, we have a problem – we made the wrong person Dutch!
What’s the deal with Dutch Chris?
Persona B is an engineer like Chris, but lives in Holland like Rhys – we accidentally mashed up two traits! In reality we had nobody in the group who was an engineer who lived in Holland – this is technically a hallucination. It’s not the AI’s fault: we only had aggregate statistics to work with, so we didn’t give it all the information it needed to do the job to the highest accuracy. We couldn’t know that the wrong traits were assigned to that persona, we only know that they all add up in aggregate.
Now what if the next study we run asks “What kind of snacks do you like?” – Dutch Chris the AI persona might say he likes Bitterballen rather than Twinkies, and so our research might conclude that engineers like traditional Dutch snacks more than they actually would in real life. When our AI personas don’t share the same preferences as real world people, it’s harder to trust our insights from synthetic research. That can lead us to make the wrong decisions when using AI personas for feedback on our ideas.
This is unfortunately common, because for the vast majority of studies we don’t have any individual level data on our personas. When you run an A/B test on a web page, or run a Facebook ads campaign, or even a wide scale survey, you usually don’t have any idea who participated. Even if you have individual level data from a survey or focus group, the jury is out on whether you’re allowed to use it for cloning a digital twin of that person. So creating synthetic personas that don’t just have realistic distributions in aggregate, but that also gets the correlations between traits right, is a necessary problem to solve.
Solving Dutch Chris with Meta Personas
While most of the time we don’t have individual level data on personas, LLMs do know something about how traits are correlated. Start with hard facts, like demographics, where you know how they are correlated. For example, you know from the US census data what the breakdowns are in each state between age, gender, and race, so that’s your starting point. Then you ask an LLM to generate new traits that are consistent with these existing personas – they can infer what attributes are realistic to assign based on what they know about the world, using the existing traits as ‘scaffolding’ to hang these new attributes on. These are called Meta Personas, because you create metadata first before adding new traits.
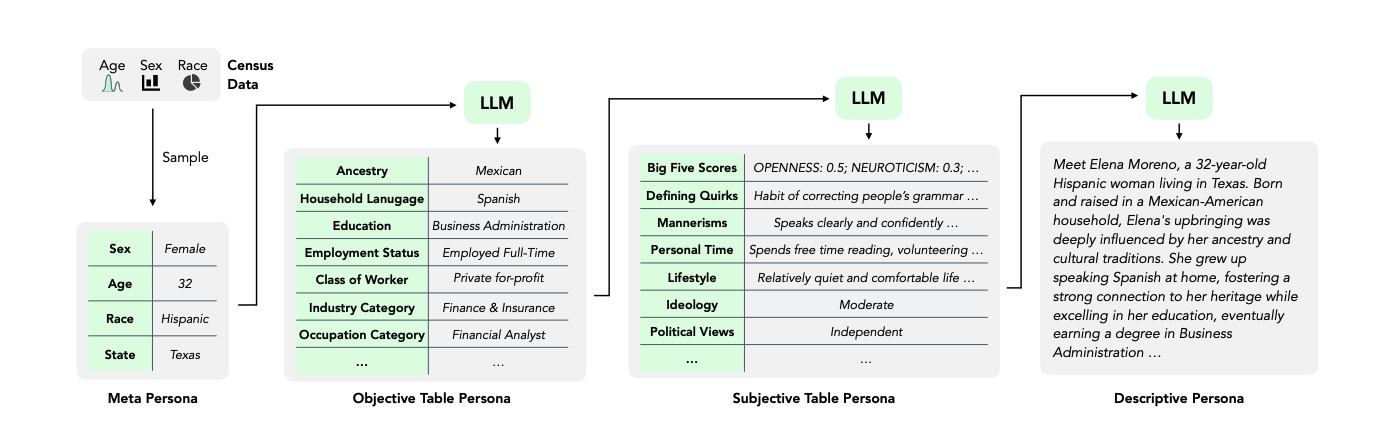
We know that people tend to earn more as they get older up to a point, then their earnings decline as they approach retirement – LLMs know that too, and you’ll rarely see them assign a high income to a teenager or retiree. Equally you won’t end up with a load of software engineers located in Idaho, or a mass of hardcore republicans in a deep blue state. The downside of this approach is that any stereotypes or biases that LLMs have will creep in, the further you get away from grounded data. But if you don’t have individual level responses, this is often the best you can do with limited data, so just be careful to inspect the final results and check they match your expectations, rerunning the process with improved instructions until you get it right.
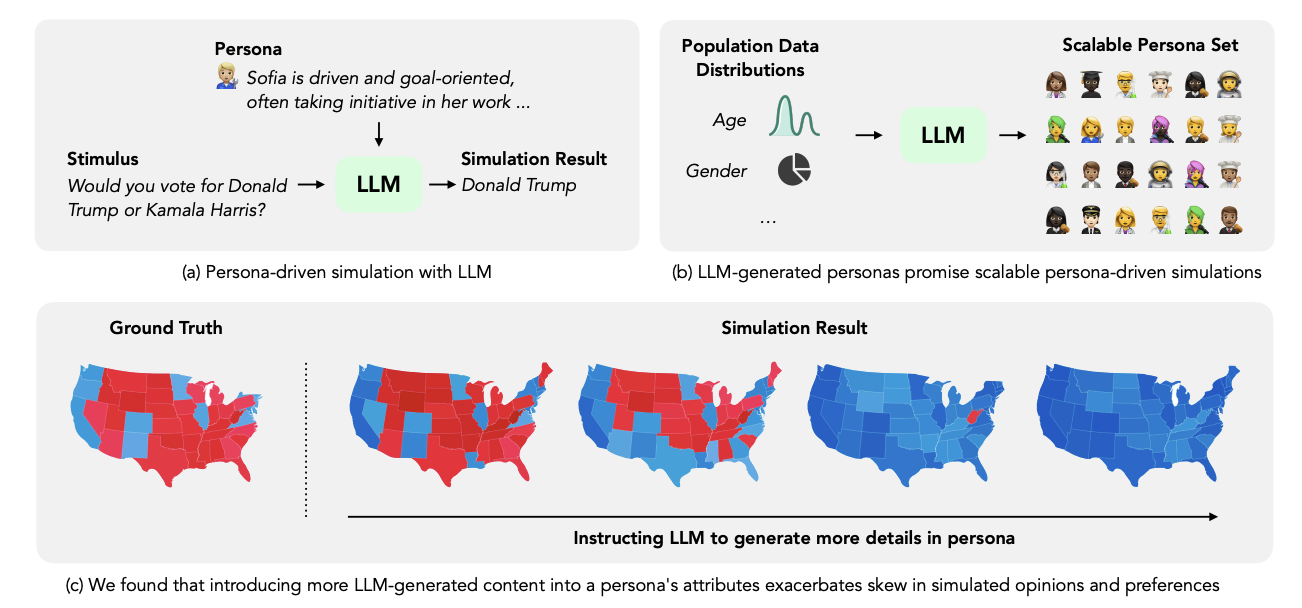
Typically with this approach I see something like 50-60% accuracy, measured in terms of replicating the real human responses against what the AI personas responded. To get us up to the 70%-80% accuracy that a CMO or Founder requires to trust the results of synthetic research, we typically need to run a calibration process on the persona creation and querying process. This involves testing what persona traits are most predictive to know to replicate the study, and what examples and instructions we should give these personas to get more accurate responses. Once you have a well calibrated virtual audience you can ask it questions for 100x less cost than running a real world study, which makes the whole process worthwhile. When you do see drift in terms of how your virtual audience responds vs your human studies, you can always run the calibration process again, to keep improving the accuracy of synthetic research. We can’t always avoid problems like Dutch Chris, but we can do a lot to mitigate them.