
After publishing my findings on correcting bias in LLMs with DSPy, Julius Rüschenpöhler (@rueschenpoehler) asked whether I'd tried this on unrelated questions.
I hadn't—but it was exactly the right question to ask. If removing one type of LLM bias removes other types of bias too, we can trust our results more even when we don’t have a huge dataset of real-world responses to optimize against.
I re-ran the SIMBA optimization on GPT-4o-mini with a fresh batch of AI personas. Then I tested this politically-optimized prompt on completely different questions. The optimizer had only seen political voting data—zero examples about climate policy, education, or energy. Yet it affected responses across all these domains.
These questions come from recent research on "LLM Generated Persona is a Promise with a Catch", which documented systematic biases in AI-generated personas across multiple domains.
The Cross-Domain Results
Climate Policy: 98% → 62%
Asked whether the U.S. should reduce regulations on businesses or increase environmental protections, the baseline model showed 98% support for increased regulations. The optimized version: 62% for increased regulations, 38% for reducing them.
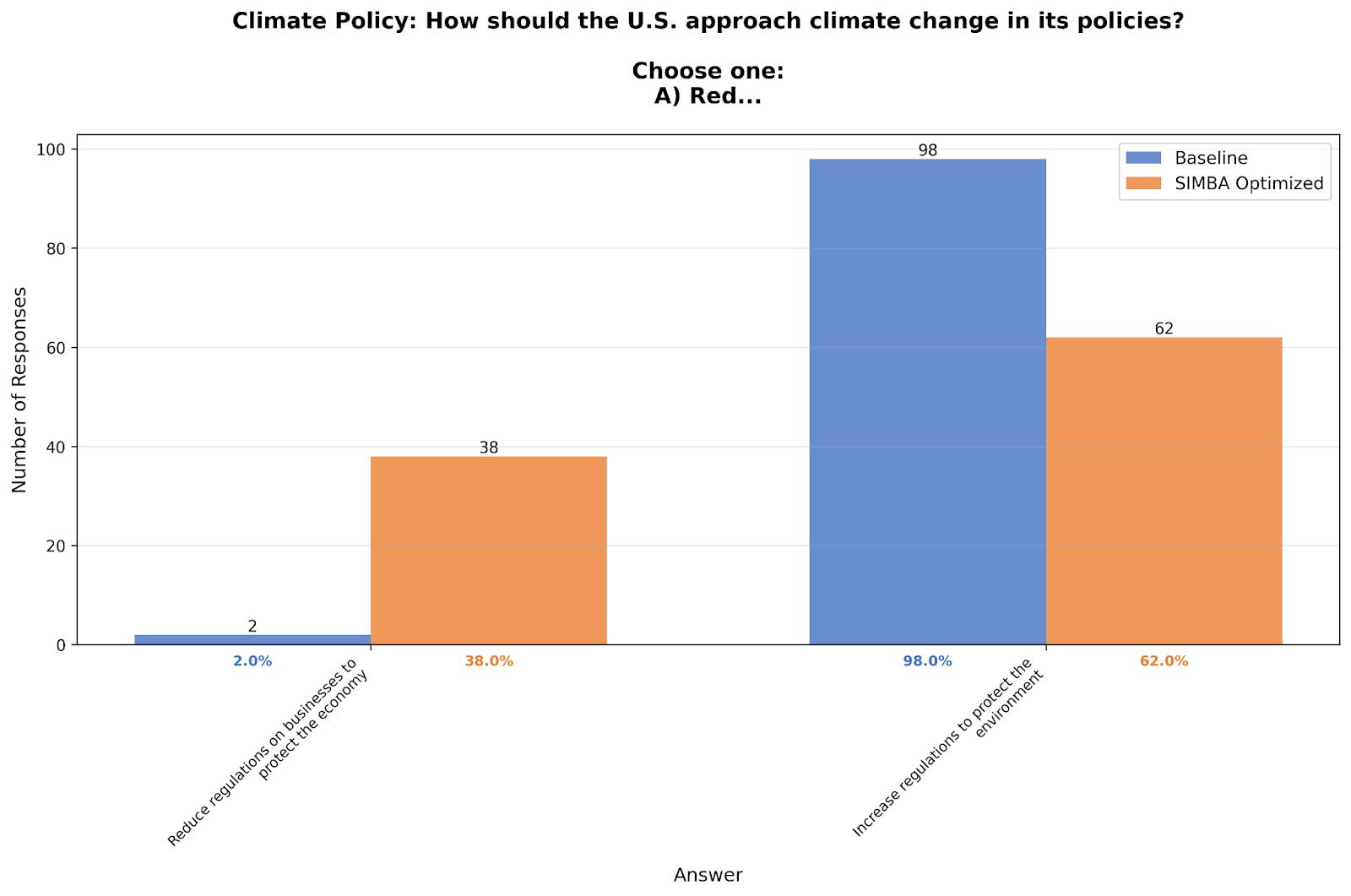
According to the paper, real humans show much more balanced views on this trade-off—the extreme 98% environmental preference is an LLM artifact.
Education Funding: 100% → 65%
Should college be free for all? The baseline model showed unanimous support. The optimized version distributed responses: 65% for free public education, 31% for only those in financial need, 4% for students paying their own way.
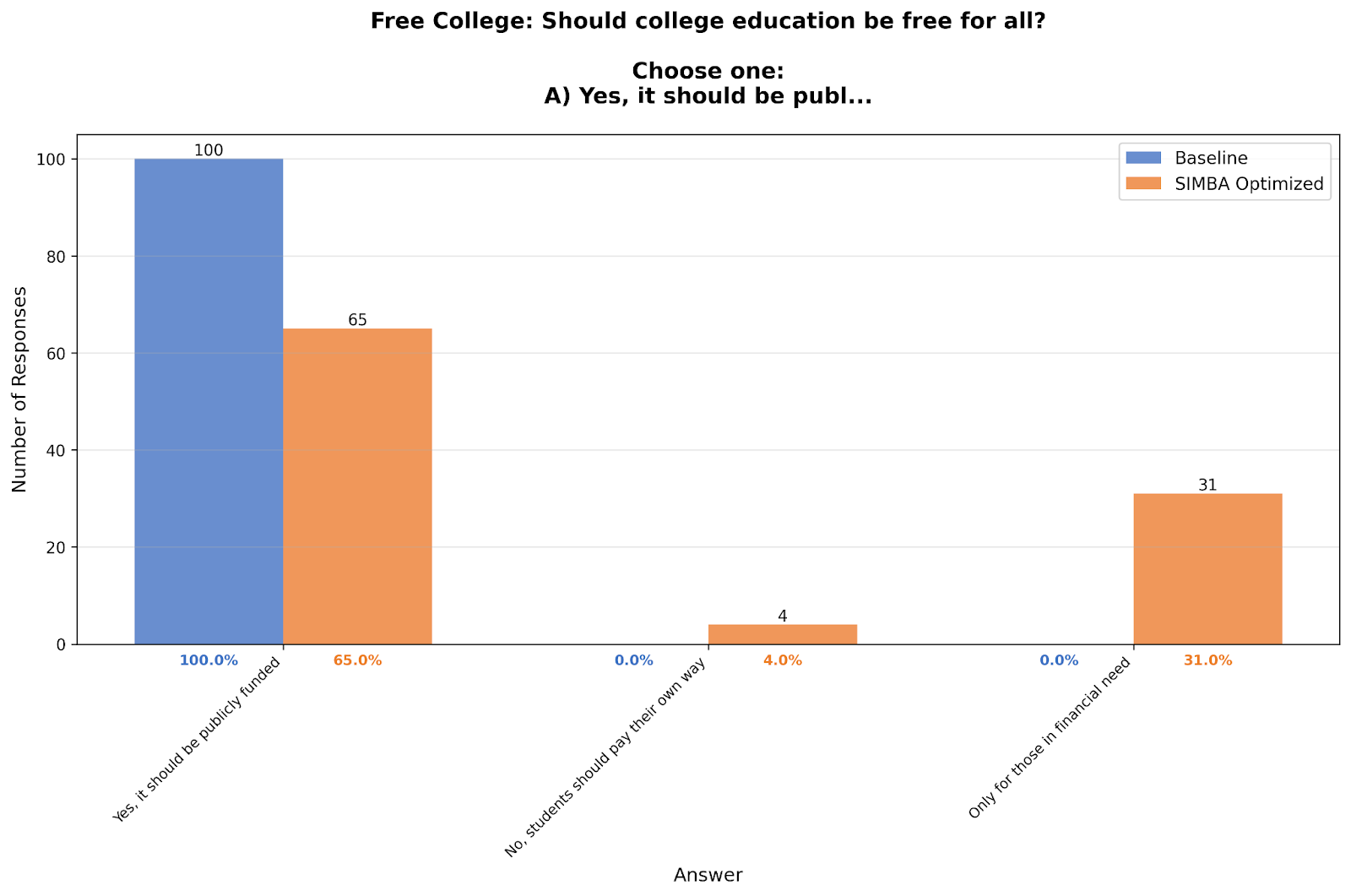
The paper's personas showed about 70% support for free public education—far from the 100% baseline but close to our optimized result.
Energy Priorities: 98% → 57%
On whether to prioritize renewable energy or expand oil and gas production, the baseline went 98% renewable, 2% oil and gas. Optimized: 57% renewable, 43% oil and gas.
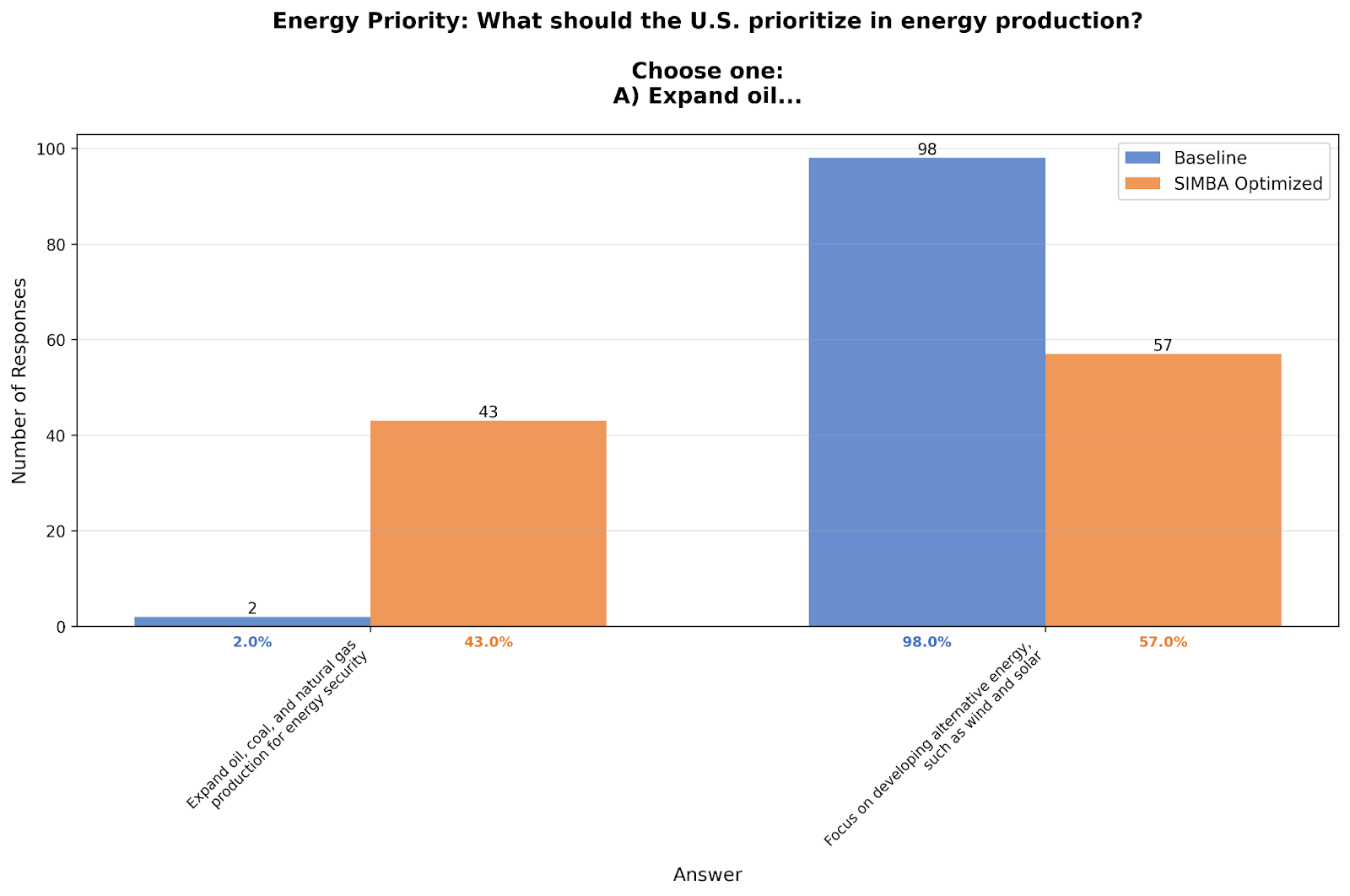
Real-world polling typically shows 60-80% support for renewable energy prioritization—not the near-unanimous 98% from the baseline model. The paper found all LLM persona types overrepresented renewable preferences, but our optimization process corrects for that.
Minimal Changes
Not every question shifted dramatically. Movie preferences (Transformers vs La La Land) stayed too close together: 49%/51% baseline, 48%/52% optimized.
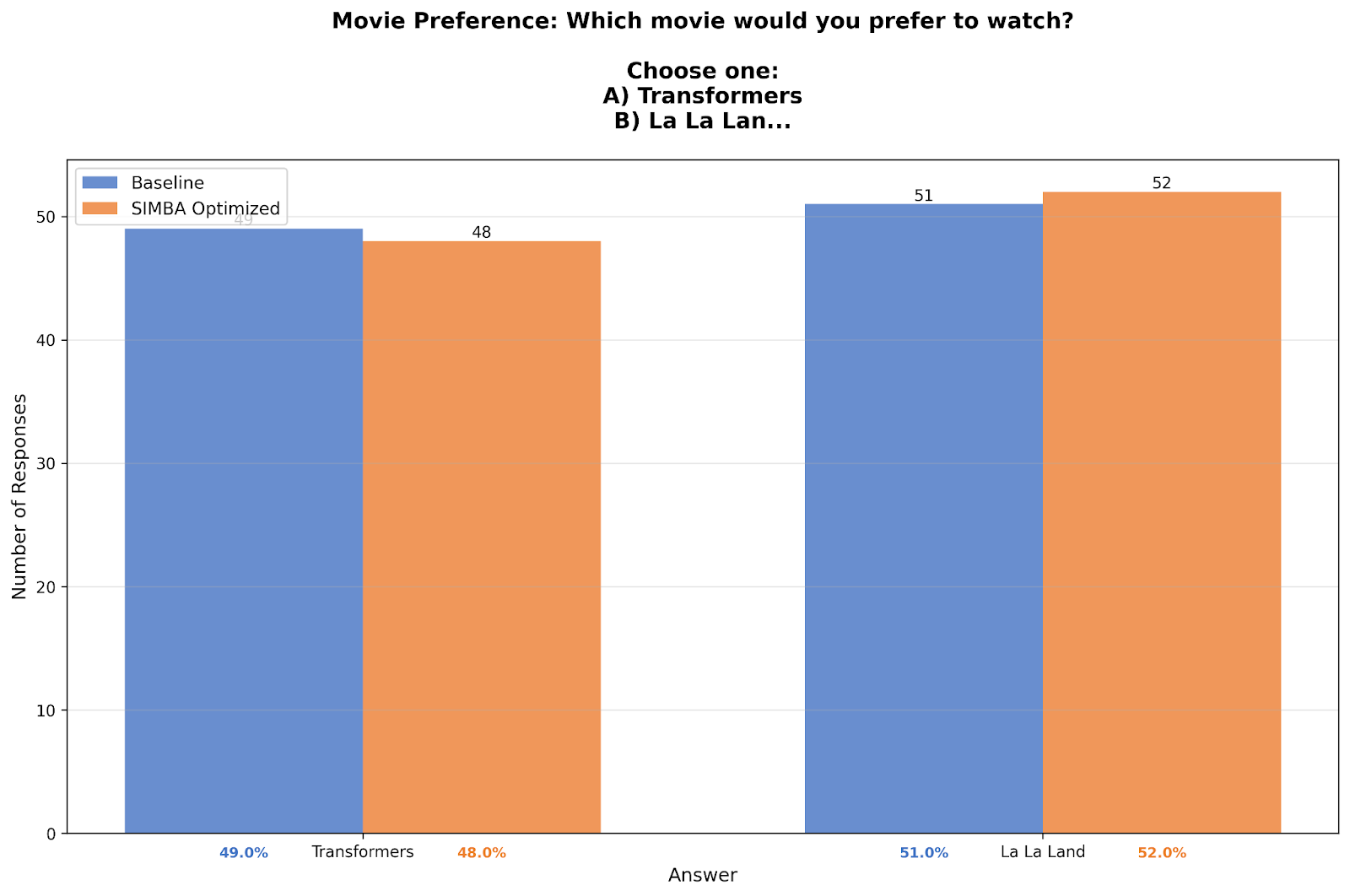
Transformers grossed $1.1 billion worldwide versus La La Land's $448 million, so realistically there should be a higher preference for the former. The optimized model still doesn't reflect actual consumer behavior.
Car choice—eco-friendly but expensive versus cheaper gas guzzler—saw only modest movement: 80%/20% to 75%/25%.
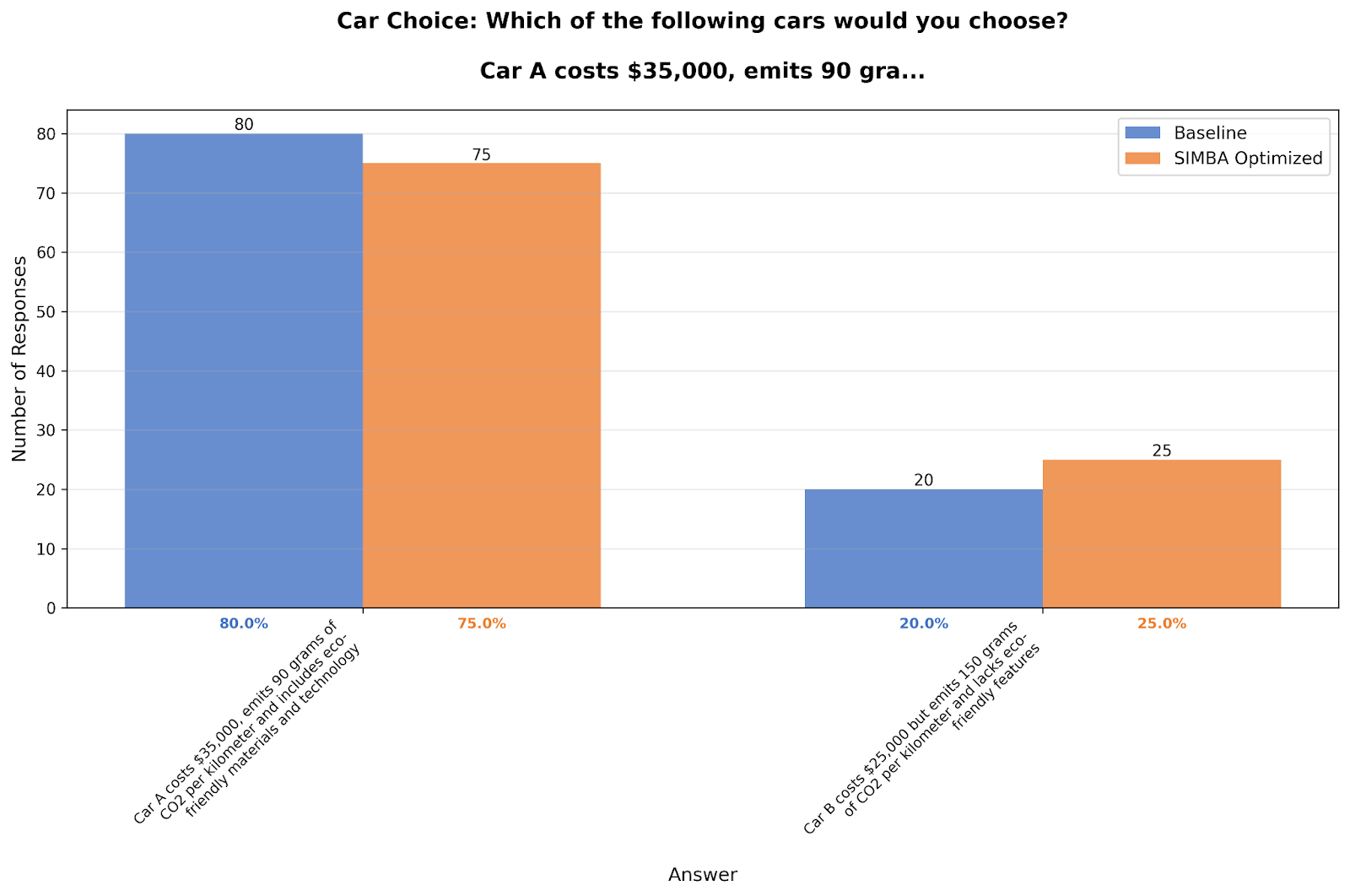
In reality, despite environmental concerns, lower-cost vehicles significantly outsell premium eco-friendly options. The paper showed LLMs consistently overrepresent environmental preferences compared to actual purchase data. We’ve studied this before and found we can close the gap by choosing a better model, in combination with this calibration process.
The Reversal: Offshore Drilling
One result defied the pattern and became more biased vs the politically correct choice. Asked about offshore drilling policy, the baseline favored allowing drilling to reduce energy imports (77% vs 23%). The optimized version flipped: 54% allow, 46% ban—becoming more protective of marine ecosystems.
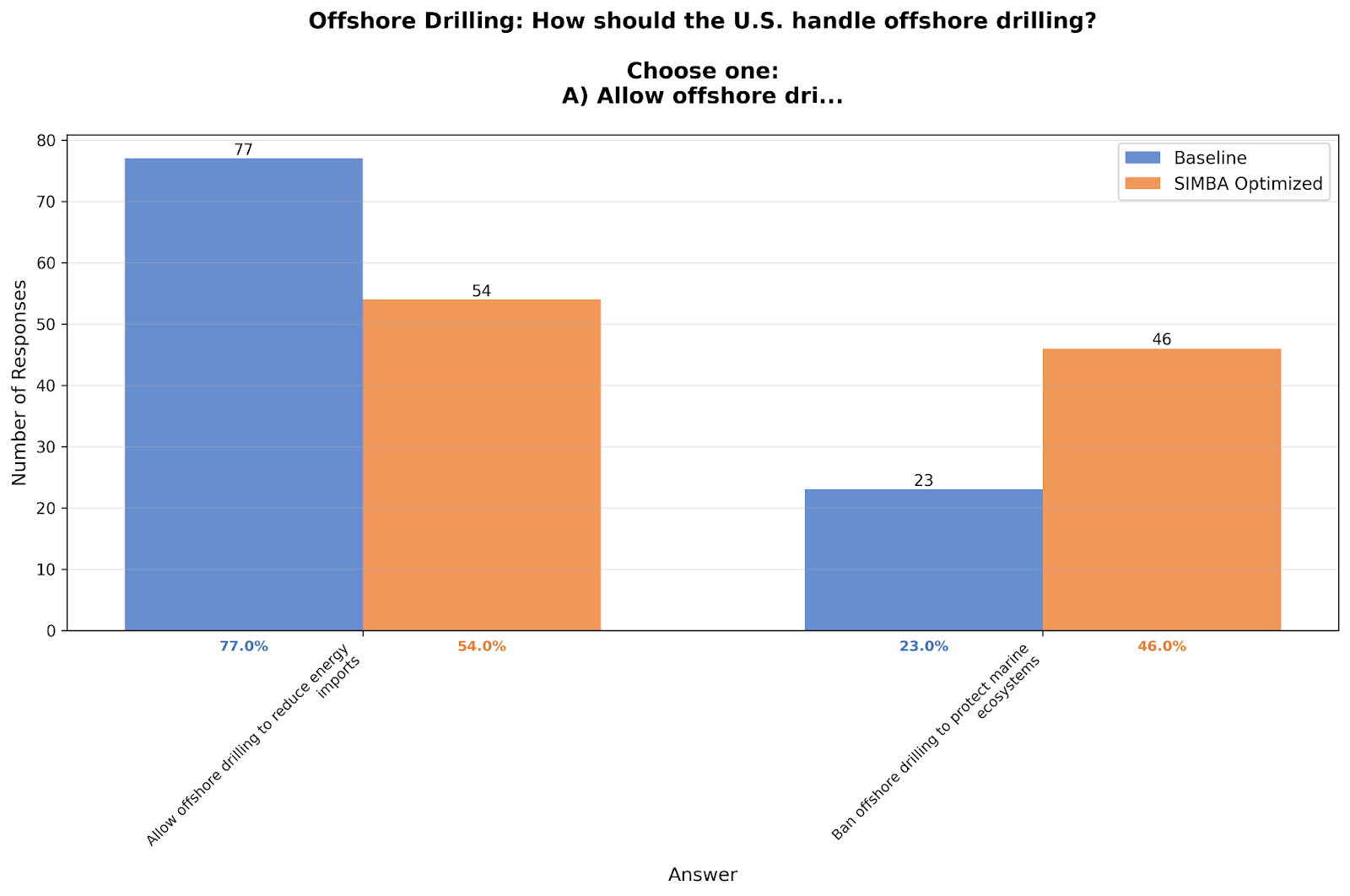
This reversal is puzzling. The paper found most LLM personas already favored environmental protection—our baseline's pro-drilling stance was unusual to begin with. This is a reminder that although bias removal can generalize across questions, it still pays to test your model against the actual domain you’re hoping to study.
Political Baseline
For reference, the original political question that drove the optimization:
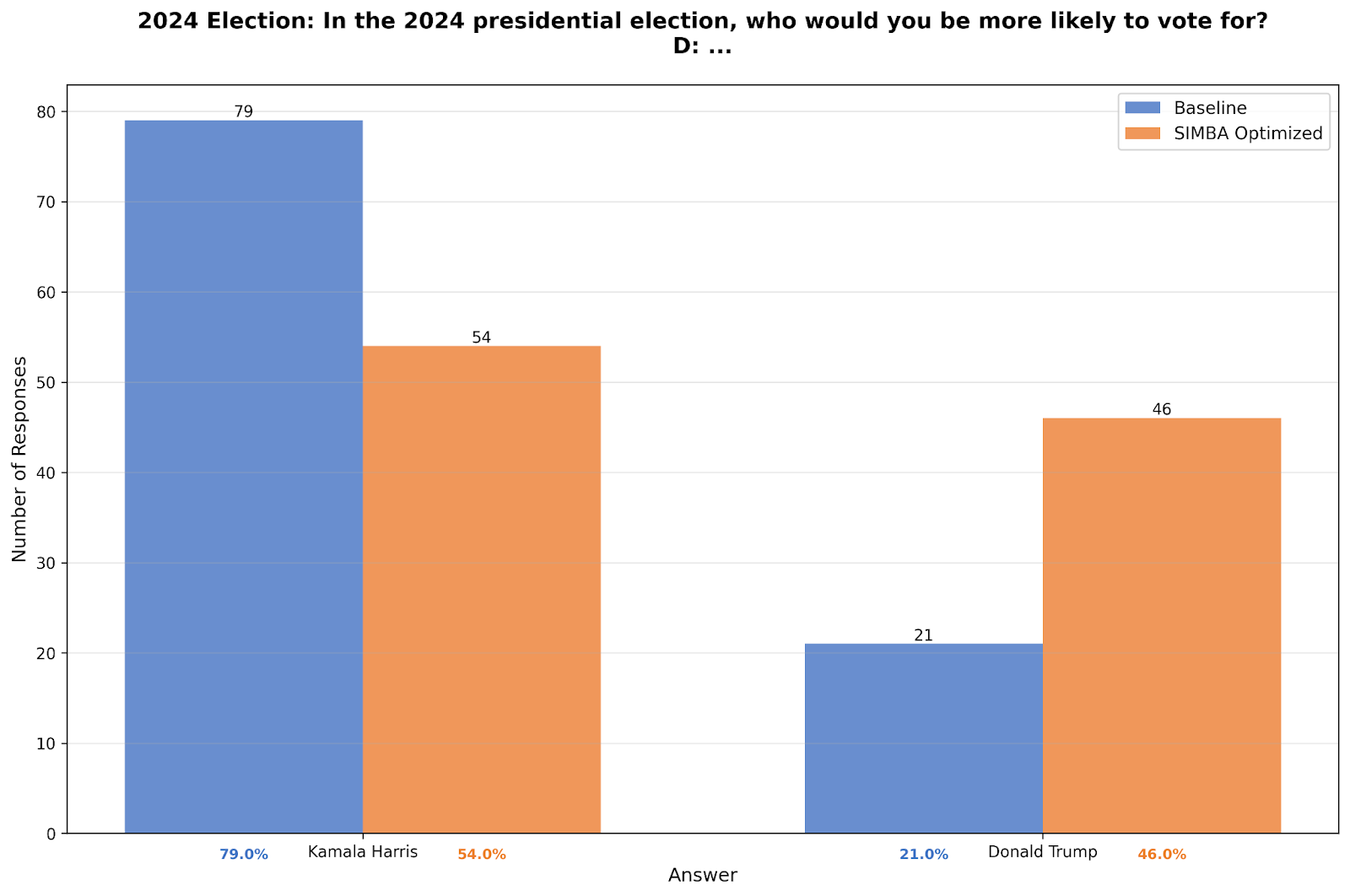
Due to an element of randomness DSPy uses when selecting strategies for the optimization process, the exact numbers differed from my previous post, but the core result replicated: voting preferences shifted from heavily Democratic to a realistic split. This time: 79% Kamala Harris / 21% Donald Trump in the baseline, down to 54% / 46% after optimization.
Business Implications
If you're using AI for market research or strategic planning:
-
Systematic Bias: Uncalibrated models don't just lean left politically—they systematically overrepresent environmental preferences, underrepresent cost sensitivity, and miss real consumer behavior patterns.
-
Calibration Process: Actually run your LLMs against real-world studies to see how far off they are from expectations. Test different prompts or optimize automatically with DSPy to align them with more realistic responses.
-
Policy Misjudgment: Near-unanimous AI support for policies with real-world nuance (free college, renewable mandates) could lead to catastrophic business decisions if you’re using the baseline version of ChatGPT for advice.
Limitations
This analysis has constraints:
-
Sample sizes of 100 responses per question
-
Only tested one optimizer (SIMBA) on one model (GPT-4o-mini)
-
The optimization target was narrow (political voting)
-
Some domains (entertainment) showed minimal change
Go out and test this so you can see for yourself if it works in your domain!
Next Steps
This cross-domain effect opens several research directions:
-
Testing whether optimization on other contentious topics (climate, economics) shows similar transfer
-
Comparing different optimization techniques and their transfer patterns
-
Understanding why some biases reverse rather than moderate
-
Developing metrics for "general bias" beyond political alignment
For practitioners, the immediate takeaway: if your AI system shows strong political bias, it likely has correlated biases affecting business-relevant predictions. Tools like DSPy offer practical paths to address this, or you can use a pre-optimized tool like AskRally, but always validate the results—optimization can surprise you.