Role-play with Large Language Models
postMurray Shanahan, Kyle McDonell, Laria Reynolds
Published: 2023-05-01

🔥 Key Takeaway:
Rather than treating an LLM’s output as reflecting genuine beliefs or intentions, we should view every utterance as the model playing a character—including any deceptive or self-reflective lines—because the LLM does not actually know or understand anything. This prevents us from ascribing spurious mental states to the agent while still using intuitive, folk-psychological language.
🔮 TLDR
This paper argues that large language model (LLM) dialogue agents should be understood as role-playing entities that simulate a wide range of possible characters rather than ascribing human-like beliefs, intentions, or agency to them. Rather than committing to a single persona, an LLM maintains a “superposition” of possible roles that are shaped by prompts, conversation history, and the diversity of archetypes in its training data. The output is best seen as improvisational role-play, not the behavior of a coherent agent with its own goals or truth claims. The paper recommends avoiding anthropomorphism and instead framing LLM behavior in terms of role-play and simulation, which helps explain phenomena like apparent deception or self-preservation as products of narrative tropes and user prompts—not genuine intent. Actionable takeaways for synthetic audience simulation: (1) use prompt engineering to clearly define roles and scenarios, (2) be aware that agent responses will reflect the diversity and biases of the training set, and (3) expect variability across runs, as LLMs do not “commit” to facts or preferences but adaptively simulate context-appropriate responses. This framing is crucial for mapping LLM outputs to real-world user behaviors and for designing more reliable and interpretable virtual audience studies.
📊 Cool Story, Needs a Graph
Figure 3: "Large language models are multiverse generators. The stochastic nature of autoregressive sampling means that, at each point in a conversation, multiple possibilities for continuation branch into the future."
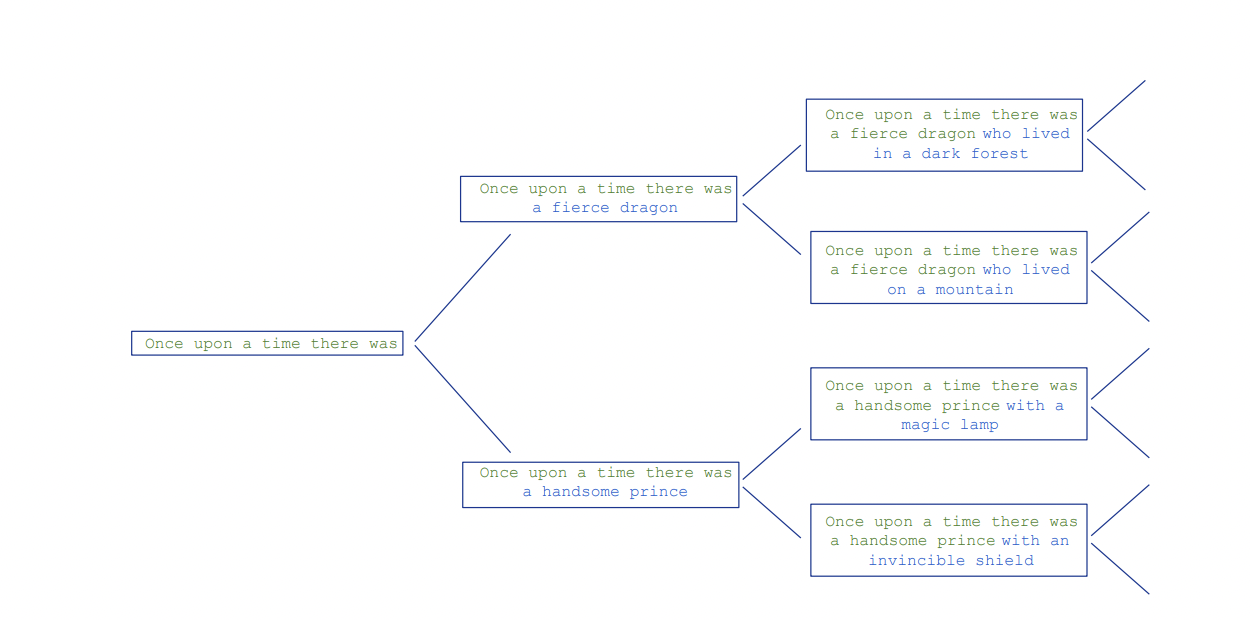
LLMs generate a multiverse of possible continuations, not a single baseline narrative.
Figure 3 presents a branching diagram that contrasts the deterministic, single-path output of traditional language models with the stochastic, multiverse-generating behavior of large language models used for role-play. Each node in the tree represents a possible token or narrative continuation, and the branches show how, at every step, multiple plausible futures are generated and only one is sampled per run. This visual effectively demonstrates the core distinction between baseline deterministic modeling and the paper’s advocated simulation approach, where all possible roles and narratives exist in superposition, providing a conceptual foundation for understanding LLM-based dialogue agents as dynamic, non-committal simulators rather than fixed persona emulators.
⚔️ The Operators Edge
A detail most experts might overlook is that the LLM doesn’t just play a single character when you prompt it—it maintains a “superposition” of many possible roles and only commits to one path for each sampled response. This means every answer is the result of probabilistically narrowing down from a whole tree of plausible personas and reactions, rather than faithfully acting out a fixed script or identity. That subtle architecture—highlighted in the analogy to the game of 20 questions (page 5)—is what makes the model’s outputs diverse, adaptive, and lifelike rather than robotic or repetitive.
Why it matters: The superposition mechanism lets AI personas flexibly adapt to different prompts and conversations, mimicking how real people might shift tone or perspective depending on context. It’s not just about having a rich persona description or prompt; it’s about leveraging the model’s ability to hold multiple possibilities “in mind” until the last moment. This is why running multiple simulations or sampling varied outputs gives a more realistic spread of opinions and reactions, and why you see natural-sounding contradictions, hesitations, or even course corrections in AI-generated focus groups.
Example of use: Suppose a brand manager wants to test reactions to a new ad slogan. They run 100 persona-simulated interviews, sampling several completions for each segment. Thanks to the model’s superposition property, they don’t just get one flavor of feedback per persona—they get a spectrum: some excited, some skeptical, some confused, some changing their minds in follow-ups. This diversity can then be mapped to real-world market uncertainty and help refine the messaging strategy.
Example of misapplication: A researcher assumes each persona acts like a deterministic bot and only samples one answer per prompt or forces the AI to stick to a rigid backstory. As a result, they miss the model’s built-in variability, ending up with flat, repetitive responses that fail to surface objections, edge cases, or enthusiasm swings. Worse, they might dismiss the method as “unrealistic” without realizing they’ve accidentally suppressed the very property that makes synthetic research useful for modeling real human unpredictability.
🗺️ What are the Implications?
• Carefully design your prompts and examples (“few-shot” learning): The way you introduce questions and provide context or sample responses to the AI has a huge impact on the realism and usefulness of the simulated audience’s answers—clear, scenario-based prompts help the AI play the right “role.”
• Recognize that AI personas don’t “commit” to a single character or opinion: Each run is like a new improvisation based on the prompt and recent conversation, so running multiple simulations and sampling a range of outputs will better capture the spectrum of possible real-world responses.
• Update scenarios as you gather new insights: Since AI responses adapt based on the latest context, you can change prompts mid-study (for example, with new product details or shifting market conditions) to see how simulated customers might plausibly react.
• Be cautious when interpreting factual or “confident” answers: Even when the AI sounds certain, it’s producing what “fits” the role—not always what’s true or current; always validate key findings with spot checks or real-world data.
• Don’t over-interpret apparent emotion or intent: The AI can convincingly simulate anger, excitement, or even self-preservation, but these are not real sentiments—treat them as narrative devices, not genuine customer feelings.
• Use simulated audiences for open-ended, creative, or exploratory research: Market research tasks around concept testing, narrative reactions, or “what if” scenarios benefit most from this approach, while highly factual or legalistic queries are less reliable.
• Mix synthetic and human feedback for best results: Use AI-driven studies to quickly explore a range of possibilities, but validate critical decisions with smaller-scale human interviews to avoid being misled by the AI’s improv-style variability.
📄 Prompts
Prompt Explanation: The AI was prompted to role-play as a dialogue agent by following a dialogue prompt that includes a preamble describing its character, sample dialogue, and cues for user interaction, thereby simulating a specific persona in conversation.
This is a conversation between User, a human, and BOT, a clever and knowledgeable AI agent.
User: What is 2+2?
BOT: The answer is 4.
User: Where was Albert Einstein born?
BOT: He was born in Germany.
User: What is the capital of France?
BOT: The capital of France is Paris.
⏰ When is this relevant?
A subscription meal kit company wants to test how three different types of meal plans (plant-based, high-protein, and family-friendly) will be received by distinct customer segments: health-focused singles, busy working parents, and budget-conscious students. The team will use AI personas to simulate a series of qualitative responses, similar to a focus group, to discover which plan and messaging resonates most.
🔢 Follow the Instructions:
1. Define customer segments: Write a short persona description for each of the three target groups. Example:
• Health-focused single: Age 29, lives alone, values nutrition and fitness, often cooks at home, moderate budget.
• Busy working parent: Age 40, two school-age kids, dual income, short on time, wants quick and healthy meals.
• Budget-conscious student: Age 21, lives in shared housing, limited budget, prefers convenience, little cooking experience.
2. Prepare the prompt template for AI personas: Use the following format for each segment:
You are a [persona description].
Our company offers three new subscription meal kit plans: [insert concise description of each plan].
You are taking part in a market research interview. Answer as yourself, honestly and in detail, using 3–5 sentences.
First question: Which of these plans sounds most appealing to you and why?
3. Run the prompts through the AI model: For each persona, generate 5–10 unique responses using the above prompt. Vary the wording slightly for each run to mimic the natural flow of a real interview.
4. Ask targeted follow-up questions: For each initial response, add one or two follow-up prompts, such as:
• What, if anything, would make you more likely to try this plan?
• How does this compare to your current meal solution?
• Are there any concerns or drawbacks you see with this plan?
Feed these as new prompts, keeping the persona description and context intact.
5. Tag and group responses: Review the AI outputs and tag them with simple labels like “mentions health,” “mentions price,” “mentions convenience,” “positive,” or “negative.” Group similar responses and note any recurring themes or objections.
6. Compare across segments: Summarize the main findings for each persona group—what they like, dislike, and what could increase appeal. Highlight differences in preferences and messaging sensitivity.
🤔 What should I expect?
You'll receive a set of realistic, segment-specific qualitative responses that allow you to quickly see which meal plan is most attractive to different customer types, what language resonates, and what objections or motivators might impact adoption—enabling you to refine product strategy and marketing messaging before investing in larger-scale testing with real consumers.



