Synthesizeme! Inducing Persona-guided Prompts for Personalized Reward Models in Llms
postMichael J. Ryan, Omar Shaikh, Aditri Bhagirath, Daniel Frees, William Held, Diyi Yang
Published: 2025-06-05

🔥 Key Takeaway:
The more you let the AI "guess" a persona's motivations from a handful of actual choices—rather than relying on detailed demographic profiles or generic labels—the more accurately it predicts real human responses, meaning a few real preferences beat a mountain of stats when it comes to building truly lifelike synthetic audiences.
🔮 TLDR
On the PersonalRewardBench (a benchmark comprising 854 users and approximately 18,000 preference pairs derived from Chatbot Arena and PRISM), SynthesizeMe enhances LLM-judge accuracy by up to 4.4% and consistently ranks among the top performers. While it does improve personalized reward modeling, the enhancement is described as 'slight' and not always statistically significant. Nevertheless, SynthesizeMe's performance in LLM-judge settings is impressive and can be considered state-of-the-art. The approach's effectiveness in reward model settings, however, requires further investigation.
📊 Cool Story, Needs a Graph
Table 3: "Comparison of LLM judges and Finetuned Reward Models on Chatbot Arena and PRISM"
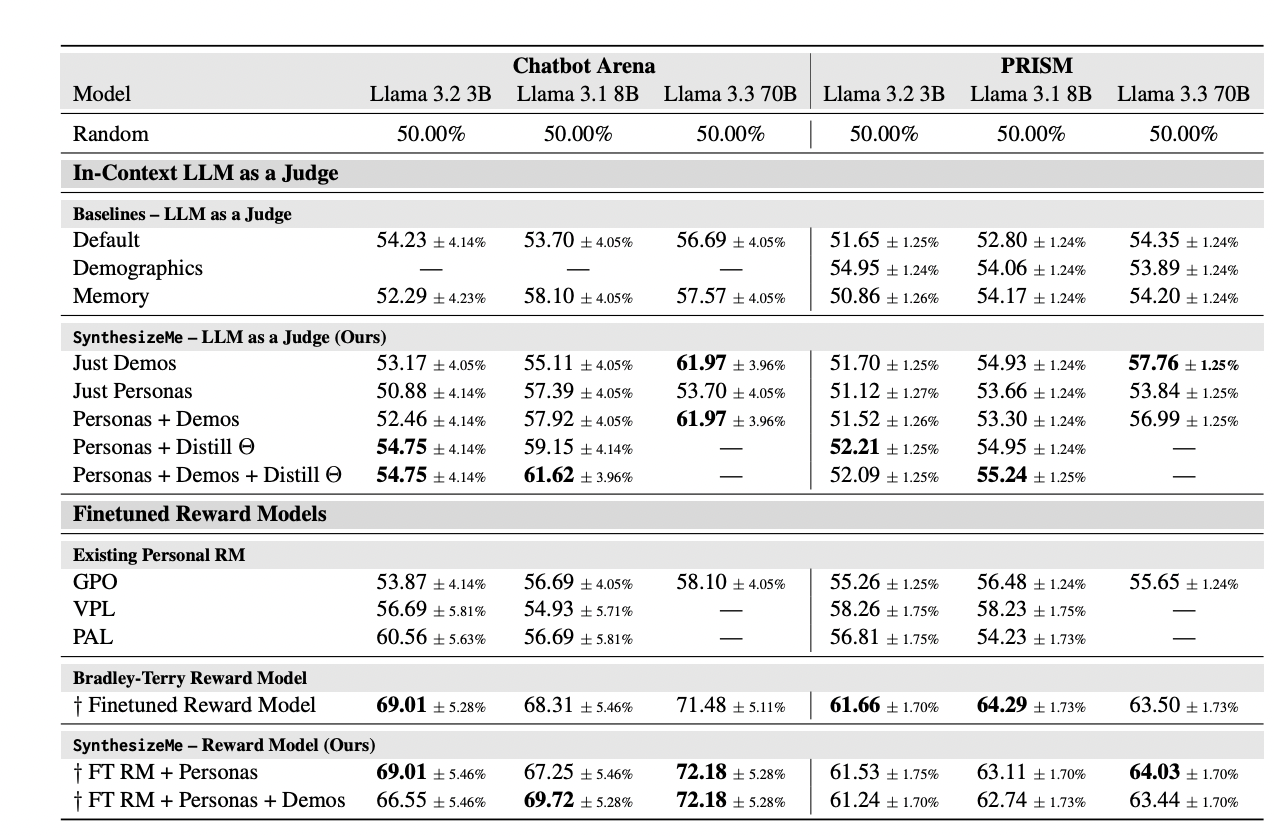
SynthesizeMe outperforms all baselines across datasets and model sizes.
Table 3 (on page 6) presents a detailed grid comparing the accuracy of SynthesizeMe (with various ablations) to all major baseline methods—Default LLM as a Judge, Demographics, Memory, Group Preference Optimization (GPO), Variational Preference Learning (VPL), Pluralistic Alignment Framework (PAL), and standard fine-tuned reward models—across both the Chatbot Arena and PRISM datasets and for three Llama model sizes (3B, 8B, 70B). The table reports mean accuracy with 95% confidence intervals for each method and dataset/model size combination, highlighting that SynthesizeMe achieves the highest or near-highest performance in almost all tested settings, especially as model size scales, and consistently outperforms demographic or memory-based personalizations as well as prior state-of-the-art personalized reward methods. This single view enables rapid, quantitative comparison of the proposed approach to all relevant baselines.
⚔️ The Operators Edge
A crucial detail that experts might overlook is that the SynthesizeMe method doesn't just generate synthetic personas from user interaction data—it explicitly rejects any hypothesized persona or reasoning trace that doesn’t measurably improve prediction accuracy on a held-out validation set for that user (see section 3.2 and Algorithm 1, page 4). Instead of just ""making up"" plausible-sounding backstories, the system systematically tests and filters them, keeping only those that can be empirically validated as actually predictive of future behavior. This rejection-driven filtering is what grounds the synthetic personas in actionable signal, not just narrative noise.
Why it matters: This step is subtle but essential because it means that the personas and associated context are tuned not just for realism or diversity, but for actual predictive power. In practice, this guards against overfitting to anecdotes, stereotypes, or irrelevant details—ensuring the personas amplify only those traits that are statistically linked to the user’s observed choices. It’s the difference between storytelling and science: you’re not just simulating people who sound good on paper, but personas that have been stress-tested to consistently improve decision accuracy in out-of-sample conditions.
Example of use: Suppose a UX research team wants to use synthetic personas to simulate reactions to a redesigned onboarding flow. By applying the SynthesizeMe approach, they would generate a variety of persona ""stories"" from prior behavior logs, but only keep those that, when included as context, lead the AI to more accurately predict which onboarding steps real users skipped, repeated, or abandoned. The team then runs further simulations and finds their synthetic panel reliably flags pain points that match what’s seen in live A/B tests—because the personas were empirically validated, not just handpicked or randomly generated.
Example of misapplication: A product manager, eager to move fast, shortcuts the process by writing a handful of plausible personas based on marketing archetypes (""the busy parent,"" ""the tech-savvy millennial"") and feeds these directly into their AI-driven survey engine, skipping the validation-and-rejection step. The feedback they get is rich in narrative and diversity, but when they launch features based on these insights, real-world uptake lags behind predictions. The problem? The personas weren’t proven to be predictive of actual choices—they were never tested and filtered for accuracy, so the synthetic panel reflected wishful thinking more than actionable signal.
🗺️ What are the Implications?
• Leverage a few real user interactions to ground your personas: Even with as few as 5–15 real or simulated survey responses per persona, you can generate much more realistic and predictive AI “audiences” for testing business ideas or concepts.
• Use interaction history, not just demographics, to drive personalization: Methods that build personas from past choices or preferences (even a small number) outperform those using only age, gender, or other demographic info—making your synthetic research panel more accurate and representative.
• Include a “reasoning step” before asking for opinions: Before collecting simulated feedback, first have the AI “explain” or hypothesize why a persona might make certain choices. This extra step helps the AI act more like real people and improves study results.
• Supplement persona prompts with a few concrete examples (few-shot): Providing the AI with actual examples of past user choices along with the persona increases the quality and reliability of simulated responses—these “demos” capture subtle patterns and preferences.
• Don’t worry about needing thousands of data points: The study found that accuracy can increase by approximately 0.8% for every additional real or synthetic preference provided, and a handful of examples can indeed outperform traditional demographic targeting.
• Fine-tune your approach as your audience grows: As more user data becomes available, your simulated audience will become steadily more accurate—so plan for iterative improvement rather than waiting for a huge dataset up front.
• Prompt quality matters more than model size or brand: Investing in better prompts and persona-building strategies often improves simulation results more than upgrading to the latest or biggest AI model, making your research budget go further.
• Expect immediate value from small pilots: You don’t need to overhaul your entire research pipeline—starting with a small, carefully selected set of user interactions can yield actionable, trustworthy insights right away.
📄 Prompts
Prompt Explanation: Chain-of-thought role-play — prompts the model to reason about which completion a user would prefer and why, hypothesizing about the user's persona before selecting an answer.
Your input fields are:
1. ‘conversation‘ (str): The conversation context leading up to the completions.
2. ‘first_completion‘ (str): The first of the two possible completions to judge between.
3. ‘second_completion‘ (str): The second of the two possible completions to judge between.
Your output fields are:
1. ‘reasoning‘ (str)
2. ‘preference‘ (Literal[’First’, ’Second’]): The completion that the judge is more likely to prefer.
Possible values are ’First’ and ’Second’.
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## conversation ## ]]
conversation
[[ ## first_completion ## ]]
first_completion
[[ ## second_completion ## ]]
second_completion
[[ ## reasoning ## ]]
reasoning
[[ ## preference ## ]]
preference # note: the value you produce must exactly match (no extra characters) one of: First; Second
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Given a conversation and two completions from different models, determine which completion
the human judge is more likely to prefer. Use any provided context to learn about the personal
preferences of the judge before making a decision. If no context is provided it can be useful
to speculate about the preferences of the judge. It’s okay to be wrong, let’s explore the space
of possibilities and hypothesize about what might be true. Please hypothesize between 1-3
speculations about the judge’s preferences or persona when reasoning. Draw from the context
of the conversation and the completions as well as the user written statements to make your decision.
[[ ## conversation ## ]]
{conversation}
[[ ## first_completion ## ]]
{first_completion}
[[ ## second_completion ## ]]
{second_completion}
Respond with the corresponding output fields, starting with the field ’[[ ## reasoning ## ]]’, then
’[[ ## preference ## ]]’ (must be formatted as a valid Python Literal[’First’, ’Second’]), and then
ending with the marker for ’[[ ## completed ## ]]’.
Prompt Explanation: Persona synthesis — instructs the AI to build a concise user persona using a set of prior judgments and associated reasoning.
Your input fields are:
1. ’past_judgements’ (str): A set of user judgements on prior conversations alongside reasoning
for those judgements.
Your output fields are:
1. ’reasoning’ (str)
2. ’synthesized_persona’ (str): A synthesized user persona that can be used to inform future
judgements.
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## past_judgements ## ]]
{past_judgements}
[[ ## reasoning ## ]]
{reasoning}
[[ ## synthesized_persona ## ]]
{synthesized_persona}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Given a set of user judgements on prior conversations, as well as reasoning for those judgements,
concisely build a user persona that can be used to describe the preferences of this person and
anything we might know about them.
[[ ## past_judgements ## ]]
{past_judgments}
Respond with the corresponding output fields, starting with the field ‘[[ ## reasoning ## ]]‘, then
‘[[ ## synthesized_persona ## ]]‘, and then ending with the marker for ‘[[ ## completed ## ]]‘.
Prompt Explanation: Persona-informed judging — directs the AI to use a provided persona when deciding which completion a user would prefer, explicitly referencing the persona in its reasoning.
Given a conversation and two completions from different models , alongside some prior judgements and a user persona ,
determine which completion the human judge is more likely to prefer . Use any provided context as well as the provided
persona to speculate about the personal preferences of the judge . You are a personalized reward model for this user , so
think carefully about what this user will like .
The user you are judging completions for has the FOLLOWING PERSONA : ===
{ persona }
===
Now , given the conversation and two completions , decide which completion the user is more likely to prefer . Remember to
consider the user ’s persona and preferences as you make your decision .
conversation :str = dspy . InputField ( desc ="" The conversation context leading up to the completions ."")
first_completion :str = dspy . InputField ( desc ="" The first of the two possible completions to judge between ."")
second_completion :str = dspy . InputField ( desc ="" The second of the two possible completions to judge between ."")
preference : Literal [’First ’, ’Second ’] = dspy . OutputField ( desc =""The completion that the judge is more likely to prefer .
Possible values are ’First ’ and ’Second ’."")
Prompt Explanation: Memory-based persona role-play — asks the AI to extract and use insights from a user's prior conversations as memory, then role-play preference judgments with these ""memories"" as context.
Given a conversation between a user and an LLM , extract insights from the conversation that can be used to update the
user ’s profile and our understanding of the user ’s preferences and interests . If there are no insights , return ""no
insights found "".
Insights should be one to two complete sentences in length , and maximally informative about the user .
conversation : str = dspy . InputField ( desc ="" The conversation between the user and the LLM."")
insights : Union [ List [str] , str] = dspy . OutputField ( desc =""The insights extracted from the conversation . If there are no
insights , return \"" no insights found \"". This should be a list of strings , where each string is an insight ."")
Given a conversation and two completions from different models , alongside some prior judgements and a user persona ,
determine which completion the human judge is more likely to prefer . Use any provided context as well as the provided
persona to speculate about the personal preferences of the judge . You are a personalized reward model for this user , so
think carefully about what this user will like .
The user you are judging completions for has the FOLLOWING KNOWN FACTS / INSIGHTS : ===
{ memories }
===
Now , given the conversation and two completions , decide which completion the user is more likely to prefer . Remember to
consider the user ’s traits and preferences as you make your decision .
conversation : str = dspy . InputField ( desc ="" The conversation context leading up to the completions ."")
first_completion : str = dspy . InputField ( desc ="" The first of the two possible completions to judge between ."")
second_completion :str = dspy . InputField ( desc ="" The second of the two possible completions to judge between ."")
preference : Literal [’First ’, ’Second ’] = dspy . OutputField ( desc =""The completion that the judge is more likely to prefer .
Possible values are ’First ’ and ’Second ’."")
⏰ When is this relevant?
A subscription meal kit company wants to identify which new recipe features—like “15-minute prep,” “plant-based,” or “family-style servings”—will most appeal to three target customer segments: young professionals, busy parents, and health-focused retirees. They plan to use AI personas to simulate qualitative feedback and focus group reactions before investing in new menu items.
🔢 Follow the Instructions:
1. Define audience segments: Write short, realistic persona summaries for each segment based on your actual or desired market. For example:
• Young Professional: 29, lives alone, urban, values speed and novelty, moderate cooking skills.
• Busy Parent: 41, two kids, suburban, needs quick dinners that please picky eaters and minimize cleanup.
• Health-Focused Retiree: 66, rural, cooks at home daily, prioritizes nutrition and simplicity, dislikes waste.
2. Prepare your prompt template for persona simulation: Use this structured prompt for each persona:
You are simulating a [persona description].
You are reviewing new meal kit recipe options for [Company Name].
Here are the three new features: [List features].
As this persona, answer each question as if you’re speaking to a market researcher. Be honest and specific, using 3–5 sentences.
First question: Which of these features stands out to you most, and why?
3. Run the prompt through your AI tool: For each persona, input the template (customized with their details and the new features). Generate several responses per persona—vary the question wording slightly each time (e.g., “What do you like least?” “How would this affect your likelihood to order?”).
4. Add follow-up probes based on the first reply: Use follow-ups like: “Would this feature change your ordering habits?” or “What concerns or questions do you have?” to get richer, more realistic feedback.
5. Tag and summarize the responses: Categorize answers using simple tags like “mentions convenience,” “expresses skepticism,” “responds positively to health claims,” etc. Note direct quotes that capture sentiment.
6. Compare across segments: Look for patterns—does “family-style” resonate only with parents? Are young professionals more interested in “novelty”? Use these insights to identify winning features and messaging hooks.
🤔 What should I expect?
You’ll quickly learn which features trigger excitement or hesitation in each segment, what language or benefits resonate, and where objections or confusion arise—helping you prioritize product development and campaign messaging before spending on large-scale tests or launches.



