A Foundation Model to Predict and Capture Human Cognition
postMarcel Binz, Elif Akata, Matthias Bethge, Franziska Brändle, Fred Callaway, Julian Coda-Forno, Peter Dayan, Can Demircan, Maria K. Eckstein, Noémi Éltető, Thomas L. Griffiths, Susanne Haridi, Akshay K. Jagadish, Li Ji-An, Alexander Kipnis, Sreejan Kumar, Tobias Ludwig, Marvin Mathony, Marcelo Mattar, Alireza Modirshanechi, Surabhi S. Nath, Joshua C. Peterson, Milena Rmus, Evan M. Russek, Tankred Saanum, Johannes A. Schubert, Luca M. Schulze Buschoff, Nishad Singhi, Xin Sui, Mirko Thalmann, Fabian J. Theis, Vuong Truong, Vishaal Udandarao, Konstantinos Voudouris, Robert Wilson, Kristin Witte, Shuchen Wu, Dirk U. Wulff, Huadong Xiong, Eric Schulz
Published: 2025-07-02

🔥 Key Takeaway:
The more you let the AI “think like a crowd”—drawing from a giant, messy pool of real human decision data across dozens of contexts—the less you need to carefully handcraft personas or scripts, and the closer your synthetic audience will get to unpredictable, human-like responses (even outperforming classic expert models when the rules or context shift).
🔮 TLDR
Centaur is a large language model fine-tuned on Psych-101, a dataset of over 10 million trial-level human choices from 160 psychological experiments, to predict and simulate human behavior across a wide range of cognitive tasks. Compared to both generic LLMs (like Llama) and top domain-specific cognitive models, Centaur more accurately predicts held-out human responses (average log-likelihood improvement of 0.13–0.14, p < 0.0001) and robustly generalizes to new experiments, cover stories, task structures, and even novel domains not present in training, outperforming traditional models in all but one case. It captures not just average behavior but the full distribution of population trajectories, matches humans in exploration strategies, and fails to predict artificial agent behavior, confirming its human-likeness. Centaur’s internal representations align more closely with human brain activity (fMRI) after fine-tuning, and it can guide the development of interpretable cognitive models using scientific regret minimization. Actionables: train/fine-tune LLMs on richly structured, trial-level human behavioral data across many tasks; benchmark on both in-domain and out-of-distribution experiments; use model predictions to prototype, stress-test, and refine market research designs; and leverage such models for rapid in silico prototyping and reducing sample size needs in experimental pipelines.
📊 Cool Story, Needs a Graph
Figure 2: "Goodness-of-fit on Psych-101"
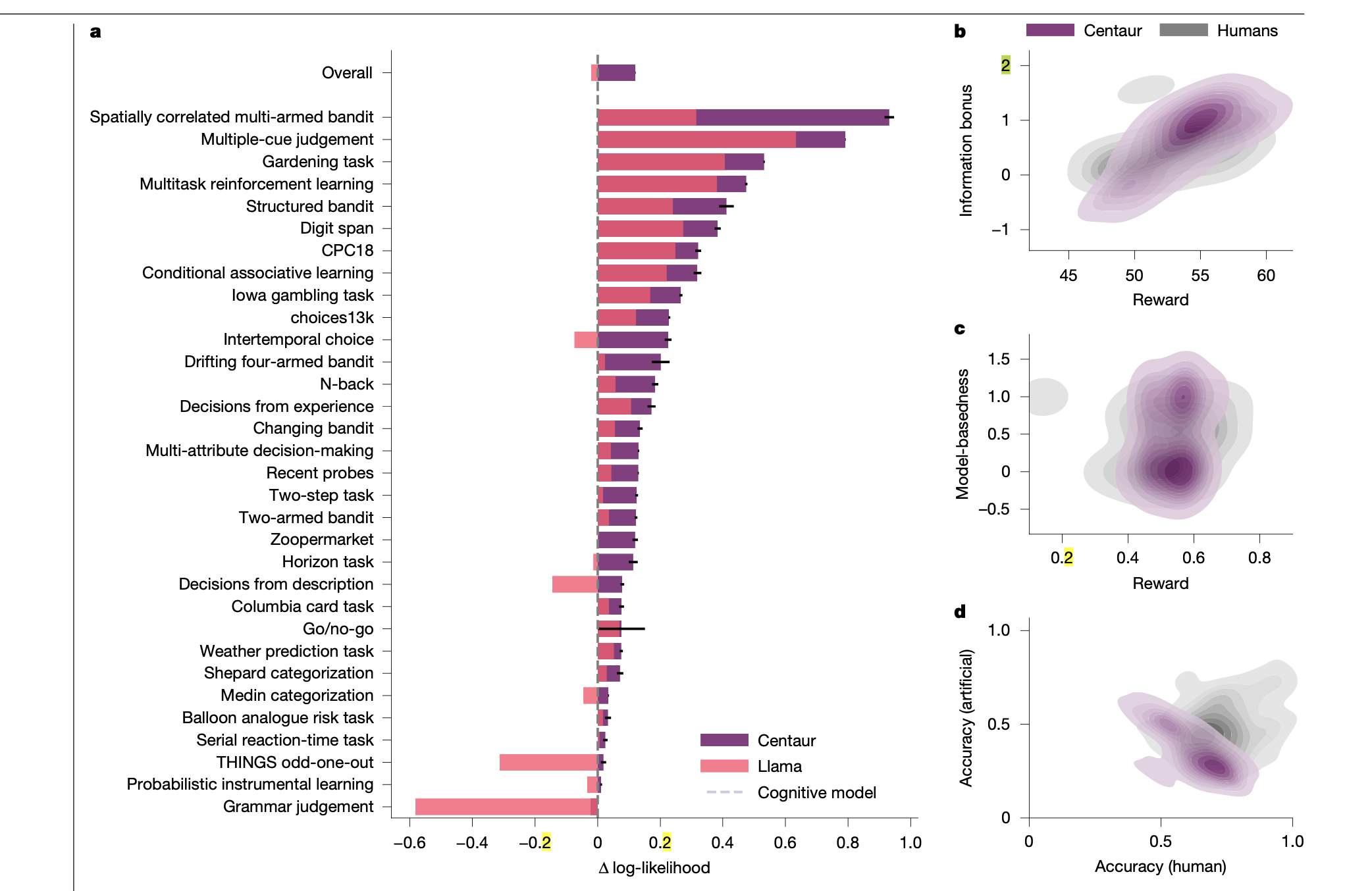
Comparison of Centaur, base Llama, and cognitive model fits across all tasks.
Figure 2a displays a comprehensive side-by-side bar chart showing the difference in log-likelihood (fit to human data) for Centaur, the base Llama model, and domain-specific cognitive models across more than 25 experiments and overall. Each bar represents an experiment, with higher values indicating better fit to human responses. The figure clearly demonstrates that Centaur consistently outperforms both the base Llama and cognitive models across nearly all tasks, providing a single, at-a-glance view of comparative accuracy and generalization.
⚔️ The Operators Edge
A detail that most experts might miss is that the model’s accuracy and realism don’t just come from the sheer size or diversity of the human behavioral dataset, but from the way each experimental prompt is structured: every single prompt includes the full, trial-by-trial interaction history for a single participant, not just summary traits or demographic labels. This means the model doesn’t just see static personas or outcomes—it learns the flow of actual decision-making, memory, and learning over time, mirroring the way people adapt and change across a sequence of choices.
Why it matters: This structure allows the AI to internalize not just what people decide, but how their thinking evolves in context—capturing the subtle, path-dependent ways that real consumers react to information, feedback, or new scenarios. It’s this temporal grounding, not just lots of data or clever prompting, that makes the synthetic audience so good at generalizing to new settings and replicating real-world patterns, even in “out of distribution” tests.
Example of use: Imagine a team testing a new app onboarding flow: by simulating AI personas with full “user journey” histories (e.g., their first, second, and third interactions with the app), the AI can reveal where users get stuck or change their minds after repeated exposure—just like a real user cohort—helping teams spot friction points or moments of delight that would be missed if only initial impressions or static profiles were tested.
Example of misapplication: A product team simulates synthetic user feedback by prompting AI personas with only their age, gender, and a single scenario (“You are a 45-year-old parent. What do you think of this app?”), ignoring any history or sequence of actions. The responses sound plausible but lack depth, adaptability, and any insight into how real users change their minds after trying features or seeing results—leading to overconfident conclusions that break down when the product goes live and real users behave very differently as they move through the journey.
🗺️ What are the Implications?
• Ground your simulated audience in real human behavior data: The most accurate simulations were achieved by training AI personas on rich, trial-by-trial datasets covering real decisions from thousands of people across many studies—not just demographics or short bios.
• Benchmark AI personas against both traditional models and real human consistency: Comparing synthetic audience outputs to both classic survey models and actual human retest rates helps validate that your simulation is capturing real-world thinking, not just generic or biased AI behavior.
• Test your study design with in-silico prototyping first: The technology now allows you to run virtual experiments with thousands of synthetic participants to estimate effect sizes, tweak designs, and reduce the number of costly human interviews needed later.
• Don’t rely on random or generic personas—use detailed behavioral histories: Simulations based on deep behavioral data (not just random attributes or simple archetypes) outperform both standard AI and most hand-crafted models in predicting how people actually respond.
• Expect strong performance even in new domains or with changed inputs: Properly trained AI personas can generalize to new scenarios, product ideas, or reworded questions better than legacy models, making them valuable for early-stage market screening.
• Invest in the richness of your input data, not just the latest AI model: The underlying dataset and behavioral sampling matter more for accuracy than using the biggest or most expensive AI engine.
• Use AI-based regret minimization to spot missed insights: By comparing where your existing models fail and the AI ""knows better,"" you can identify hidden consumer segments or decision patterns that traditional approaches overlook.
📄 Prompts
Prompt Explanation: Trial-by-trial role-play — elicits full-session human-like responses by having the AI model simulate a participant's behavior across an entire experimental session in natural language.
Each prompt was designed to include the entire trial-by-trial history of a complete session from a single participant. The instructions should follow the original study as closely as possible; simplifications were made where appropriate; and a maximum prompt length of roughly 32,768 tokens was used.
⏰ When is this relevant?
An online furniture retailer wants to test customer reactions to a new "modular sofa" line, focusing on three segments: price-sensitive first-home buyers, design-focused urban professionals, and busy parents who value durability and easy cleaning. The company wants to use AI personas to simulate customer interviews and identify which features and selling points resonate with each segment.
🔢 Follow the Instructions:
1. Define audience segments: Draft three AI persona profiles, each with a clear description:
• Price-sensitive first-home buyer: 27, just bought a small apartment, budget-conscious, prefers value and practicality.
• Design-focused urban professional: 34, lives in a city loft, cares about aesthetics, latest trends, and personalization.
• Busy parent: 41, three children, wants easy-to-clean, durable, and safe furniture, shops for family needs.
2. Prepare prompt template for persona simulation: Use this template for each AI persona:
You are simulating a [persona description].
You have just been shown this product concept: ""A modular sofa system that can be easily rearranged, upgraded with new sections, and includes washable, stain-resistant covers. Pricing starts at $599 and delivery is available nationwide.""
You are being interviewed by a market researcher. Respond honestly and naturally, using 3–5 sentences, based on your persona’s needs and values. Stay in character.
First question: What is your first impression of this modular sofa concept?
3. Generate initial responses: For each persona, run the above prompt through your AI model (e.g., OpenAI GPT or similar) 5–10 times, slightly rephrasing the product concept or first question for variety.
4. Add follow-up prompts: For each initial response, ask 1–2 follow-up questions, such as:
• ""Which feature do you find most appealing and why?""
• ""Would you consider purchasing this for your home? What concerns or hesitations do you have?""
Continue to prompt the AI for each persona, ensuring responses are realistic and detailed.
5. Tag and summarize key themes: Review all AI-generated responses and tag them with themes like ""mentions price,"" ""highlights flexibility,"" ""concerned about durability,"" or ""excited by design options.""
6. Compare across segments: Create a summary table showing which features resonate most with each persona type, and where objections or enthusiasm are strongest.
🤔 What should I expect?
You’ll have a clear, directional view of how different customer segments are likely to respond to the modular sofa, which talking points or features are most persuasive for each group, and where objections or doubts arise—providing actionable guidance for product messaging, marketing, and which segments to prioritize for launch.



