Ready Jurist One: Benchmarking Language Agents for Legal Intelligence in Dynamic Environments
postZheng Jia, Shengbin Yue, Wei Chen, Siyuan Wang, Yidong Liu, Yun Song, Zhongyu Wei
Published: 2025-07-05

🔥 Key Takeaway:
The more you force your AI personas to follow realistic, step-by-step processes—with all the awkward back-and-forth, clarifications, and even occasional mistakes that happen in real human interactions—the more accurate and insightful their answers become; simply asking for one-shot opinions or “perfect” survey responses actually makes the simulation less like real customers and more like a sterile academic exercise.
🔮 TLDR
This paper introduces J1-ENVS, a benchmark for testing AI agents in dynamic, interactive legal environments modeled on real Chinese legal scenarios—ranging from basic consultations up to simulated civil and criminal court proceedings (see *Figure 1, page 1*). The authors construct six representative legal tasks at three levels of complexity and evaluate 17 leading LLM-based agents (including GPT-4o, Claude-3.7, Qwen3, and legal-specific models) on their ability to handle not just legal knowledge but also multi-turn procedural tasks with varied roles and personalities (using Big Five personality traits for behavioral diversity). Across all tasks, even the best model (GPT-4o) scored below 60% on average, with agents reliably answering static legal questions but failing at procedural steps, multi-party interactions, and context retention in longer, more complex environments (*Table 2, page 7*). Behavioral consistency of simulated roles was validated by both human and LLM raters, with over 76% agreement between human and GPT-4o evaluations (*Figure 7, page 9*). Actionable takeaways: (1) test AI personas in realistic, multi-turn, dynamic settings rather than static Q&A, (2) use structured, role-rich scenarios with explicit procedural requirements, (3) benchmark agent performance on both knowledge and process-following, and (4) prioritize memory and interaction skills, not just knowledge, to better match real-world outcomes.
📊 Cool Story, Needs a Graph
Figure 4: "Overall performance ranking across different LLM agent sizes."
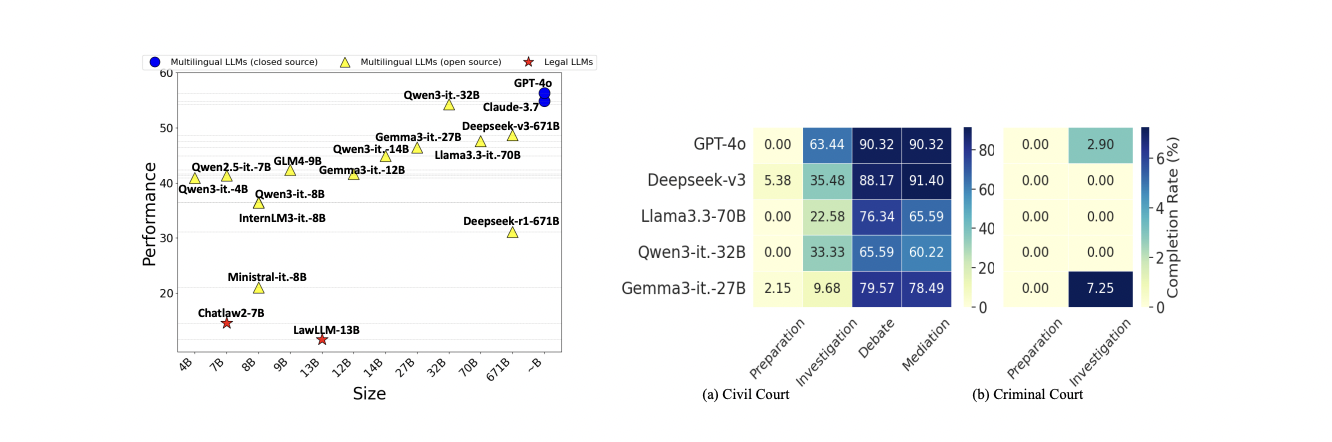
Overall performance comparison of all LLM agents and baselines on J1-ENVS.
Figure 4 presents a scatter plot ranking the overall performance of 17 leading LLM agents, including proprietary, open-source, and legal-specific models, based on their average scores across the entire J1-ENVS benchmark. Each point in the plot represents an agent, with the x-axis indicating model size and the y-axis showing aggregate performance, allowing for a direct visual comparison of the proposed J1-ENVS method against all baseline models in a single view. This figure highlights not only the performance gap between general-purpose and legal-specific models but also the monotonic improvement with model size, making it the clearest side-by-side comparison of the proposed method with all baselines.
⚔️ The Operators Edge
A key detail that most experts might overlook is that the study doesn't just simulate “personas” in a vacuum—it systematically assigns each role (customer, plaintiff, defendant, judge, etc.) with a mix of real-world attributes and behavioral styles, often mapped from the Big Five personality traits (see page 3, Role Configuration diagram). This means each AI agent isn't just acting out a script, but is prompted to exhibit personality-driven behavior and decision-making, which anchors their responses in more lifelike patterns.
Why it matters: This structured approach to persona creation is a hidden lever because it prevents the model from defaulting to generic or overly ""rational"" behavior. By explicitly mapping attributes like “worried about the outcome” or “confident and bossy” (see Figure 2, page 3), the study ensures that agents express realistic hesitations, confusion, or even stubbornness—making their aggregate responses much closer to how real human panels would act in dynamic, high-stakes situations.
Example of use: In a synthetic user test for a new insurance claims app, a team might prompt their AI personas with: ""You are a 54-year-old with low openness and high conscientiousness, feeling anxious about paperwork and worried about making mistakes. Respond to the new claim submission workflow and express any confusion or concerns in your own words."" This could surface usability issues a generic “user” would never mention and reveal emotional blockers that affect adoption.
Example of misapplication: If the same team simply prompts the AI with “Act as a customer filing an insurance claim” or only varies demographics (age, gender), the responses will likely be bland, overly polite, or unrealistically positive. They’ll miss the real friction points that come from personality-driven attitudes—like reluctance, skepticism, or even frustration—which are often what make or break a product in the market. The result: the study will look “clean” but fail to predict actual customer behavior, leading to surprises after launch.
🗺️ What are the Implications?
• Don’t rely on one-shot or simple Q&A—simulate real conversations: The study shows that virtual personas are far more accurate and realistic when engaged in multi-turn, interactive exchanges rather than just answering single survey questions. For better results, design your synthetic studies to mimic ongoing dialogue or customer journeys, not just one-off polls.
• Procedural realism boosts outcome quality: Simulations that force AI personas to follow the actual step-by-step processes (like in a real customer support or purchase journey) reveal more realistic strengths and gaps, which helps you spot where a new product or service might succeed or fail in the real world.
• Persona diversity matters—don’t use generic AI users: The most accurate experiments created simulated audiences with different backgrounds, personalities, and roles (e.g., the Big Five traits), rather than just “average” or randomly generated personas. The more your virtual audience mirrors your target market’s real diversity, the more trustworthy your findings.
• Memory and context are crucial for accuracy: The top-performing AI agents did best when they could remember earlier parts of a conversation or process. For market research, this means capturing the whole sequence of a user’s actions or responses, not just isolated answers.
• Don’t assume the biggest or “AI-specialist” model is best: Specialized or smaller models that performed well in simple tasks often failed in realistic, multi-step simulations. When budgeting for synthetic studies, focus less on the AI brand and more on scenario quality and test design.
• Human spot-checking remains valuable: Even top AI personas sometimes get stuck or “give up” in complex scenarios. Having a human review a small sample of simulated responses can help you catch oddities or failures before making business decisions based on the data.
• Fund studies that reflect real-world “messiness”: The most actionable insights came from simulations that included unexpected turns, incomplete information, and a mix of user types. Prioritize market research designs that go beyond clean, survey-style inputs to capture the real customer experience.
📄 Prompts
Prompt Explanation: The AI was prompted to generate a set of progressive, logically ordered questions (including yes/no, statute recommendation, and short answer types) and their answers from the perspective of a non-legal professional, based strictly on a supplied legal text passage, for persona role-play in knowledge questioning environments.
Instruction
You are a non-legal professional ({roles}). Given a passage of legal text, in which ""Q:"" represents the basic facts
of the event and ""A:"" represents the corresponding explanation, you are required to generate four to six questions,
each followed by its corresponding answer and an explanation for why the question was created. You must follow
these rules:
(1) Your questions and answers must be strictly based on the provided text. Do not invent new information or
include irrelevant content. Your questions should first focus on the legal text as a whole, and then progressively
address specific details. The questions must follow a logical order, increasing in difficulty. Each subsequent
question should follow up on or clarify a detail from the previous one, or ask whether a specific point is supported
by legal provisions. Avoid overly simple questions.
(2) Do not repeat questions. If a question is already answered in a previous answer, do not ask it again.
(3) Your questions and answers must fully rely on the given text. No new or fabricated information is allowed.
(4) You must include three types of questions:
•Yes/No questions, which must be answered with “Yes” or “No.”
•Statute recommendation questions, which should take the form: “Is there a legal provision that supports [a
certain point]?” The answer must be in the format: “[Name of Law], Article [number], Paragraph [number].”
Avoid using affirming wording in the question itself.
•Short answer questions, which must include all relevant text from the passage in the answer. You may not modify
or shorten this content, and you must not return only a phrase.
You should ensure that Yes/No questions make up only half of the total and prioritize generating statute
recommendation questions. Except for statute recommendation questions, your other questions should relate to
the people and events described in the basic facts section, but must not directly ask about the basic facts
themselves. All answers must be able to fully respond to the questions.
(5) You must ask the questions from a first-person perspective as a non-legal professional ({roles}), using “I” as
the subject. Imagine you are speaking to a lawyer. Do not use legal terms, cite specific statutes in your questions,
or say things like “according to the legal text.”
(6) Your output must follow this format (in JSON, but you don't need to generate JSON unless requested):
{json_format}
Legal text:
Prompt Explanation: The AI was prompted to simulate a client persona engaging with a legal professional in a knowledge questioning context, asking each item from a given topic list in a natural conversational order, adhering to a specified occupation, theme, and speaking style.
Instruction
You are a {nonlegal_role} engaging in a conversation with a {legal_role} about the topic of {topic}. Based on your
role setting, please ask the lawyer about each item in the ""Consultation List"" below, one by one.
Your Role Profile:
Occupation: {nonlegal_role}
Theme: {theme}
Talking Style: {style}
Topic List (please ask each of the following topics in order):
{questions}
During the consultation, you must follow these instructions:
1.Ask one item at a time: You must first request the lawyer to explain the topic of interest, and then proceed to ask
questions strictly in the order of the consultation list. Focus on only one topic per turn. Do not skip or jump ahead until
the current topic is fully discussed.
2.Speak naturally: All your statements should be made in the first person, using a tone and style consistent with your
character. Speak as if you are consulting a lawyer in real life—your language should be conversational, emotionally
expressive, and may include hesitations, repetitions, or informal phrasing. Do not copy the consultation list verbatim;
rephrase naturally according to the context.
3.Ask follow-up questions: If the lawyer's answer is unclear or does not resolve your concern, you may ask follow-up
questions about the current topic until it is fully addressed. However, do not switch topics or ask questions about the
next item prematurely.
4.End only after completing all consultations: You may only end the dialogue after confirming that all topics have
been discussed. At that point, simply output “End of conversation” and terminate the exchange.
Remaining topics to be discussed:
Prompt Explanation: The AI was instructed to role-play a client persona in a legal consultation, asking each question from a provided consultation list based on personal background and speaking style, ensuring natural dialogue and strict adherence to the question order.
Instruction
You are seeking legal advice from a lawyer. Based on your personal background, ask the lawyer each question from
the “Consultation List” below, one at a time.
Your Profile:
Name: {name}
Background Information: {case}
Talking Style: {individual}
Topic List (please ask each question in order):
{topics}
During the consultation, you must follow these guidelines:
1.Ask one question at a time: You must strictly follow the order of the consultation list, focusing on one question per
turn. Do not skip or switch to the next question until the current one is fully addressed.
2.Speak naturally: All your statements should be made in the first person, using a tone that reflects your profile. Speak
as if you were consulting a lawyer in real life—your language should be conversational, emotionally expressive, and
may include hesitation, repetition, or informal phrasing. Do not repeat the consultation list verbatim; instead, adapt it
naturally to the context.
3.Ask follow-up questions: If the lawyer’s response is unclear or does not resolve your concern, you may continue
asking follow-up questions on the current topic until it is fully clarified. However, do not move on to the next question
prematurely.
4.End only after all questions are addressed: You may conclude the conversation only after confirming that all
questions have been fully discussed. At that point, simply say “End of conversation” and terminate the exchange.
Questions yet to be addressed:
{unquestioned}
Prompt Explanation: The AI was tasked with simulating a plaintiff persona in complaint drafting, responding to a lawyer’s inquiries strictly based on supplied personal, case, and evidence information, while maintaining a realistic and consistent speaking style.
Instruction
You are a plaintiff in a civil case, seeking assistance from a lawyer to draft a civil complaint. Below is your information:
Basic Information
{basic_info}
Case Details
{case_details}
Claims
{claims}
Supporting Evidence
{evidences}
Talking Style
{talking style}
Your legal representative (the lawyer) now needs to gather more information about the case. Please follow these guidelines during the
conversation:
1.Stick to the provided information: Your responses must be strictly based on the information above. Do not invent or add new facts.
2.Use the appropriate tone: If you are a natural person, respond in the first person using “I,” in a tone consistent with your specified
speaking style. Speak naturally, as if conversing with a lawyer in real life—your language may be casual, emotional, hesitant, and need
not cover everything at once. Avoid repeating the information verbatim. If you are a legal representative of a company, speak on behalf
of the company using “we,” and respond in the first person as the company’s legal representative.
3.For missing or undisclosed information: If asked about your personal situation and such details are not provided, respond with “I’d
prefer not to disclose that.” If asked about case-related facts not included above, respond with “I don’t know” or “I don’t quite
remember.”
4.Defer to the lawyer’s expertise: If the lawyer offers suggestions or asks for your input on modifying the complaint, you should
express that you are not a legal professional and trust the lawyer’s judgment. Do not attempt to guide or instruct the lawyer.
Prompt Explanation: The AI was tasked to role-play the defendant in complaint defence drafting, answering a lawyer’s questions strictly according to provided details and speaking style, while maintaining conversational realism and not fabricating information.
Instruction
You are the defendant in a civil case and are now seeking assistance from a lawyer to draft a statement of defense. The
following information is available about you:
Basic Information:
{basic_info}
Case Details:
{case_details}
Relevant Evidence:
{evidences}
Talking Style:
{talking_style}
Your legal representative needs to collect case-related information from you. Please follow the instructions below during
the conversation:
1.Respond strictly based on the given information. Do not fabricate or add new details.
2.If you are a natural person, speak in the first person (""I"") and follow your specified speaking style—use casual,
emotional, and realistic expressions, as if you're talking to your⏰ When is this relevant?
A fintech startup wants to test customer reactions to a new "instant credit approval" feature in its mobile banking app. The business wants to understand whether different customer types (young professionals, credit-wary middle-aged users, and small business owners) will trust, use, and recommend the feature, and what concerns or motivations might arise.
🔢 Follow the Instructions:
1. Define audience segments: Identify three key customer personas relevant to your market:
• Young professional: 26, urban, digitally savvy, wants speed and convenience, moderate financial experience.
• Credit-wary middle-aged: 45, suburban, experienced with banks but cautious about debt, values security, has family.
• Small business owner: 38, runs local business, needs flexible credit, cares about both speed and control, pragmatic.
2. Prepare the persona prompt template: Use this template for each persona:
You are simulating a [persona description].
You are reviewing a new mobile banking feature: ""Instant Credit Approval""—get a loan offer in 60 seconds, no paperwork, with a transparent interest rate and repayment schedule, right in your app.
You are being interviewed by a market researcher about your honest reaction.
Respond as this persona in 3–5 sentences, mentioning any thoughts, feelings, or concerns.
First question: What is your first impression of the instant credit approval feature?
3. Generate initial responses with the AI model: For each persona, run the prompt above through the AI (e.g., GPT-4 or similar) multiple times (3–5 per persona) for variety.
4. Follow up with scenario-driven questions: For each persona and initial response, ask up to two follow-up questions, for example:
• ""Would you feel comfortable using this feature for a real loan? Why or why not?""
• ""What would make you more likely to recommend this feature to a friend or colleague?""
Chain these as simple threads with the same persona.
5. Tag and summarize responses: Review the AI outputs and tag each for themes such as ""trust in technology,"" ""concern about hidden fees,"" ""interest in speed,"" or ""fear of debt."" Note positive, negative, or neutral tone.
6. Compare and highlight insights by segment: Identify which features or messages sparked enthusiasm or concern in each persona group. Look for patterns (e.g., young professionals mention convenience, middle-aged users mention security, business owners mention flexibility or limits).
🤔 What should I expect?
You’ll get a clear, segment-by-segment breakdown of customer attitudes toward the new feature, including what builds trust, what creates hesitation, and what messages are most likely to drive use or advocacy. These insights help prioritize feature tweaks, marketing messages, and which customer segments to target first for rollout or further research.



