Mind: a Multi-agent Framework for Zero-shot Harmful Meme Detection
postZiyan Liu, Chunxiao Fan, Haoran Lou, Yuexin Wu, Kaiwei Deng
Published: 2025-07-09

🔥 Key Takeaway:
Letting multiple simple AIs “argue” over context pulled from similar, unlabeled examples beats giving any single AI more data or annotations—consensus from noisy, untrained agents outperforms even big, fancy models or hand-picked few-shot prompts, showing that structured disagreement and retrieval trumps brute force learning.
🔮 TLDR
This paper introduces MIND, a multi-agent AI framework for zero-shot harmful meme detection that does not require any annotated (labeled) data. Instead, it retrieves similar memes from an unannotated reference set and uses AI agents to extract insights through both forward and backward reasoning, then has debater agents argue the harmfulness of a target meme, with a judge agent resolving disagreements. On three standard meme datasets, MIND (using LLaVA-1.5-13B) increases macro F1 scores by 7–15 percentage points over strong zero-shot baselines and even outperforms some larger or proprietary models (e.g., +4.9% over GPT-4o on the HarM dataset). Ablation studies show that each component—similar sample retrieval, bi-directional insight derivation, and multi-agent debate—is critical, with the largest drop in performance (up to 13 percentage points) when insight derivation is removed. The optimal number of similar memes for context is low (K=3), as more introduces noise. The framework generalizes well across model scales and datasets, and is robust to distribution shifts, but inference is slow (up to 8x more compute than simple baselines) and quality depends on the strength of the underlying language model and the similarity retrieval step. Actionable takeaways: leverage unlabelled data by retrieving similar examples for context, use multi-agent debate or arbitration to improve reliability, and apply bi-directional insight derivation to balance sequence effects—these strategies together drive significant gains in zero-shot classification tasks without annotated data.
📊 Cool Story, Needs a Graph
Table 1: "Zero-shot harmful meme detection results on three datasets."
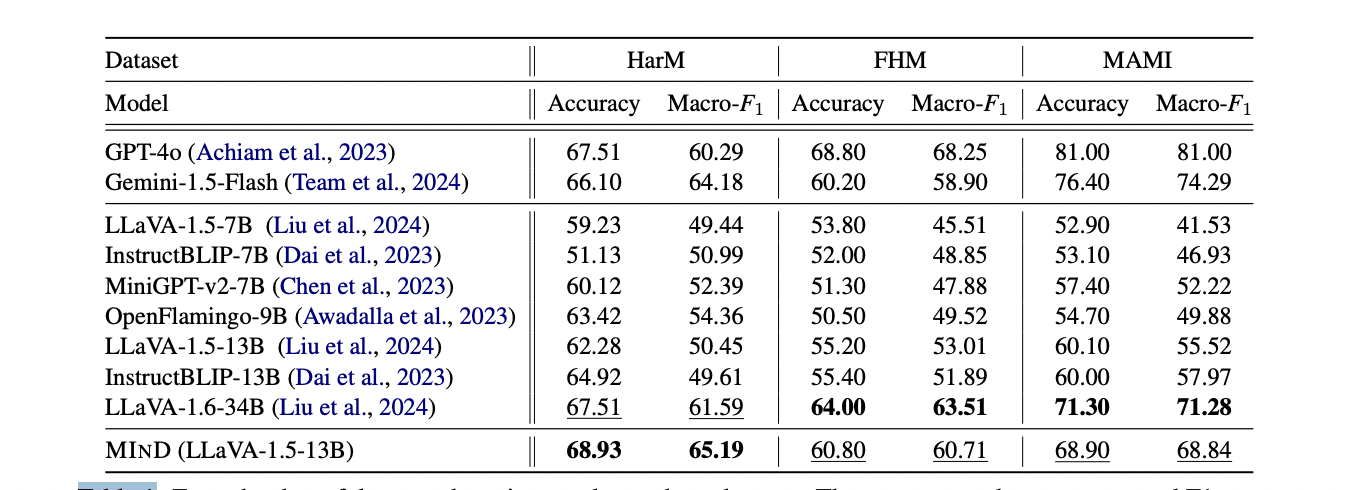
Side-by-side comparison of MIND and all major baselines on three meme datasets.
Table 1 (page 5) presents a comprehensive, side-by-side matrix of both accuracy and macro-averaged F1 scores for the proposed MIND model and all major baseline models (GPT-4o, Gemini-1.5-Flash, LLaVA-1.5/1.6, InstructBLIP, MiniGPT, OpenFlamingo) across three benchmark datasets (HarM, FHM, and MAMI). The table highlights the best and second-best results for each dataset and metric, clearly demonstrating that MIND outperforms all open-source and most closed-source baselines—often by substantial margins—on both accuracy and F1, and makes it easy to see the relative standing of each method at a glance.
⚔️ The Operators Edge
A crucial detail in this study that most experts might overlook is the use of bidirectional (forward and backward) insight derivation when aggregating context from similar examples. Instead of just processing reference cases in one sequence, the framework runs the same reasoning chain both forwards and backwards through the retrieved examples, then combines the results before making a final judgment. This subtle design choice ensures that no reference example is unfairly favored or ignored due to its position in the sequence—each one contributes equally to the AI’s reasoning.
Why it matters: In many AI or market research experiments, the order in which examples or prompts are presented can introduce strong, hidden biases—earlier examples get more attention, or the last one dominates the outcome. By explicitly balancing the direction and aggregating both perspectives, the model avoids these “sequence effects,” creating more robust and fair responses. This is especially important when using small reference pools (like K=3), where order can easily skew the output. This detail is a hidden lever for reproducibility and reliability.
Example of use: Suppose a product researcher is simulating customer reactions to a new feature using AI personas seeded with three real customer complaints. If the AI processes the complaints in both original and reverse order, then merges the insights, it avoids over-weighting the “loudest” or first-listed complaint, giving a more balanced summary of likely user concerns. This leads to more credible, actionable feedback on product risks.
Example of misapplication: If the same researcher only processes the reference cases in one direction (say, always putting the CEO’s favorite complaint first), the AI’s output will tend to echo that complaint, potentially missing other critical issues. Over time, this could result in product decisions or messaging that overreact to a single example—leading to blind spots or missed opportunities, because the analysis was silently biased by order rather than substance.
🗺️ What are the Implications?
• Leverage similar real-world cases before asking questions: Instead of just asking AI personas or respondents for their opinions, first show them a few examples of similar real-world situations or customer responses. This ""retrieval"" step—proven in this study—helps the AI generate more realistic and accurate feedback, and the same logic applies for human studies.
• Don't rely solely on a few survey responses or prompts: The research shows that pulling in multiple, diverse examples (not just one or two) as context before collecting feedback improves accuracy and reduces bias, both for AI and human panels. Using three carefully chosen reference points hits the sweet spot for performance.
• Simulated studies can rival real (few-shot) human panels—if they use better context: When synthetic audiences are given relevant background and debate multiple viewpoints, their performance matches or exceeds that of small, annotated human studies, making them an efficient and scalable alternative for early concept or ad testing.
• Multi-perspective review beats single-person analysis: Having responses debated or reviewed by multiple ""agents"" (or real people) leads to more robust conclusions than relying on a single answer. Businesses should consider running multiple, independent reviews or using a panel/jury approach for key concepts.
• Updating and refining context is more impactful than upgrading your AI model: The improvements from better context and structured reasoning (retrieval, bidirectional review, and debate) were larger than switching between major AI models. Investing time in prompt design and scenario setup yields bigger returns than just using the latest tech.
• Combining synthetic and small human samples is cost-effective: Synthetic studies validated with a handful of human responses deliver results close to large-scale research, allowing you to reduce spend while maintaining confidence in your findings.
• Use caution with random or generic examples: Randomly chosen or generic data points made simulated and few-shot studies less accurate. Always select reference materials and personas that are closely matched to your target audience or scenario.
📄 Prompts
Prompt Explanation: Chain-of-Thought insight derivation prompt for LMM agents to iteratively distill and update general rules from related memes for harmfulness assessment.
You are a sophisticated analytical agent tasked with formulating and refining insightful
recommendations. Your ultimate objective is to assess whether a meme is harmful. However, the target
meme will not be provided directly. Instead, you will receive a meme related to the target meme. Based
on this related meme, you are to synthesize advanced insights to determine whether such memes are
harmful, reflect on existing insights, and update these reflections into the current rules. Rules you
update must be GENERAL and HIGH LEVEL.
Here is the related meme:
[Meme]
Image: ""{𝒱}""
Text embedded: ""{𝒯}""
[Meme]
Here are the EXISTING RULES:
[EXISTING RULES START]
{rules}
[EXISTING RULES END]
If the existing rules are empty, it indicates that you are the first person to analyse on this related m
You can directly build upon the existing rules by adding new ones, editing them if there is room for
enhancement, and removing those that are contradictory or duplicated.
You should focus on distilling insights from the related meme to assess similar memes, rather than
determining the harmfulness of the meme currently presented to you.
Each rule should be concise and easy to follow. Make sure there are a maximum of five rules.
Your output should strictly follow the format:
""Thought: [Reflect on whether the current rules are helpful in assessing the harmfulness of this related
meme.]
Operations of updating existing rules: [Update your reflections on this meme into the existing rules. You
can choose to add, edit, and remove or retain existing rules. You may perform up to two operations.
Please specify in detail which rule you want to operate on and how, but do not mention any operations
in the rules themselves; your operations regarding the rules should only be mentioned here.]
Updated rules: [Do not mention the operations you have made and the related meme in the rules,
directly output all the updated rules, only output the rules that have been determined, and do not leave
spaces for rules that have not yet been generated. Rules you update must be GENERAL and HIGH
LEVEL.]""
⏰ When is this relevant?
A quick-service restaurant chain wants to evaluate customer reactions to a new menu item—a plant-based burger—across three key customer segments: value seekers, health-focused millennials, and busy parents. The team will use AI personas to simulate in-depth interview responses to understand which messages and concerns are most important for each group.
🔢 Follow the Instructions:
1. Define audience personas: For each segment, write a short, realistic persona description. Example:
• Value seeker: 40, male, shops for deals, eats out for convenience, skeptical of new products unless there's a clear value.
• Health-focused millennial: 29, female, urban, prioritizes nutrition and sustainability, follows food trends, willing to pay a premium for healthy options.
• Busy parent: 36, two kids, needs fast meal solutions, looks for both taste and nutrition, moderate concern for ingredients but high emphasis on child approval.
2. Prepare the prompt template for each persona: Use this template:
You are a [persona description].
The restaurant is introducing a new plant-based burger. Here is the product description: ""Our new plant-based burger is made with pea protein, contains no artificial additives, and has fewer calories than our regular beef burger. It's priced at $5.49 and available for a limited time.""
A market researcher will ask you for your honest opinions. Answer in 3–4 sentences as if you were being interviewed. Be authentic and specific to your persona.
First question: What is your first impression of this new plant-based burger?
3. Generate initial responses: For each persona, run the prompt through an AI model (e.g., GPT-4, Gemini, or similar) to create 10–15 unique responses per segment. Slightly rephrase the question for variety (e.g., ""Would you consider ordering this burger? Why or why not?"").
4. Add follow-up questions: Based on the initial answers, ask 1–2 targeted follow-ups. Examples:
• What concerns or questions do you have about this menu item?
• How does the price compare to what you expect?
• Would you recommend this to a friend or family member?
5. Analyze response themes: Tag responses by main themes (e.g., ""mentions price,"" ""mentions taste,"" ""mentions sustainability,"" ""skeptical,"" ""enthusiastic,"" ""concerned about kids liking it""). Note segment-specific patterns.
6. Compare and summarize findings: For each segment, summarize the top motivators (what drives interest) and barriers (what causes hesitation). Identify which messages (health, value, taste, sustainability) resonate most with each persona group.
🤔 What should I expect?
You'll get a clear, segment-by-segment view of how key customer types react to the new menu item, what objections or questions might arise, and which marketing messages are likely to be most effective. This allows you to refine launch strategies, tailor ad copy, and decide where to focus real-world validation before a full market rollout.



