AI METROPOLIS: SCALING LARGE LANGUAGE MODEL-BASED MULTI-AGENT SIMULATION WITH OUT-OF-ORDER EXECUTION
postZhiqiang Xie, Hao Kang, Ying Sheng, Tushar Krishna, Kayvon Fatahalian, Christos Kozyrakis
Published: 2024-11-05

🔥 Key Takeaway:
Letting your simulated audience run wild—allowing each AI persona to act independently and at its own pace, instead of forcing everyone to move in lock-step—actually makes your results more realistic, more scalable, and closer to how real markets behave, even though it feels messier and less controlled.
🔮 TLDR
AI Metropolis is a new engine for running large-scale, multi-agent LLM simulations that solves a critical efficiency bottleneck: traditional step-based simulations (like GenAgent and most RL frameworks) force all agents to synchronize at each step, causing most agents to sit idle and sharply limiting parallelism. By tracking actual agent dependencies in time and space—using a spatiotemporal dependency graph—AI Metropolis lets independent agents or clusters move ahead asynchronously as soon as their dependencies are resolved, reducing unnecessary waiting. In benchmarks with 25–1000 agents, this out-of-order execution yields 1.3×–4.15× speedups over standard parallel stepwise simulation (and up to 19.5× over single-thread baselines), with parallelism rates increasing from 1.9 to 50+ as agent count grows; performance reaches 74–97% of an optimal “oracle” scheduler. The system is modular, supports both open-source and API-based LLMs, and is most effective with large agent counts or bursty workloads, with priority scheduling further boosting throughput by up to 15%. Actionable takeaway: for any large-scale LLM-based simulation, replacing global step synchronization with real-time dependency tracking and asynchronous cluster scheduling enables much higher efficiency and scalability, and these principles can be retrofitted to existing agent-based market research simulations to cut compute cost and turnaround time.
📊 Cool Story, Needs a Graph
Figure 4
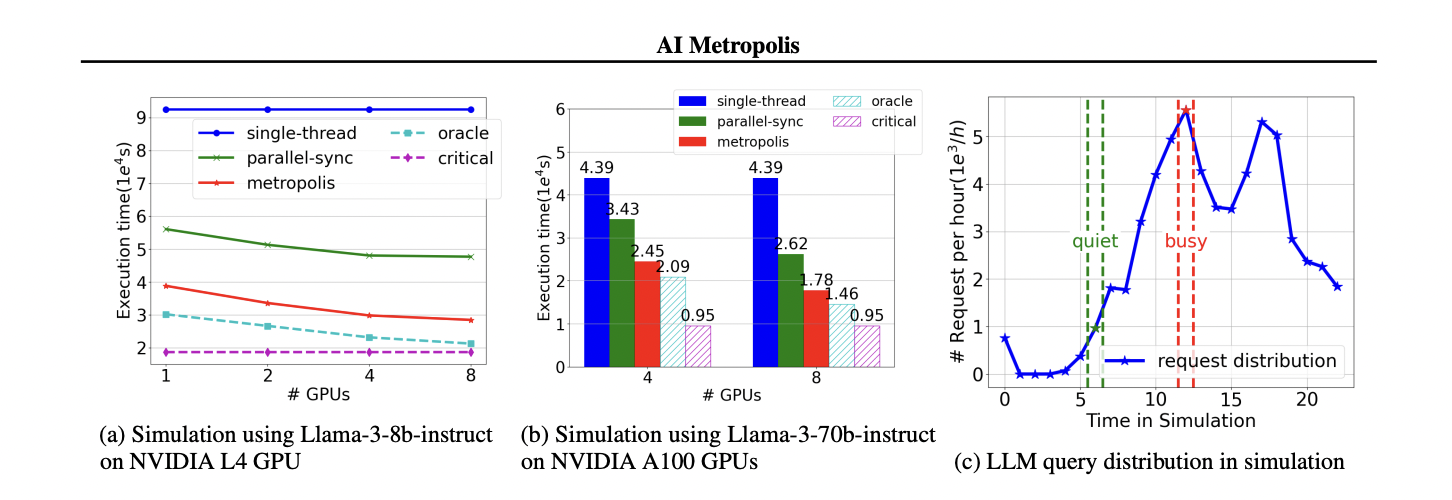
Performance comparison of AI Metropolis and all baselines across multiple GPUs for a full day simulation.
Figure 4 displays both line and bar charts contrasting the execution time (in seconds) and throughput (requests per minute) of the proposed AI Metropolis engine with single-thread, parallel-sync, oracle, and critical-path baselines for a 25-agent, full-day simulation using two Llama-3 models and increasing GPU counts. The left and center panels clearly show how AI Metropolis consistently outperforms traditional baselines, achieving lower completion times and higher throughput as hardware resources scale, with results approaching the optimal "oracle" baseline. The right panel contextualizes these results by showing the temporal distribution of LLM queries, highlighting peak and idle workload periods. This figure succinctly visualizes the efficiency and scalability benefits of AI Metropolis relative to all key alternatives.
⚔️ The Operators Edge
A subtle but critical detail in this study is that the performance gains and realism hinge on dynamically maintaining a fine-grained spatiotemporal dependency graph—tracking exactly which agents actually “see” or affect each other at every point in the simulation, rather than relying on global synchronization or static groupings (see Figure 3 and discussion on pages 5–6). This means the system only enforces dependencies where they matter, freeing up most agents to act independently, and clustering only those who are truly interacting. It’s not just that agents run in parallel; it’s that their independence is continually recalculated based on who could potentially influence whom, step by step, in both time and space.
Why it matters: Most people might assume the speedup is just from using more compute or running everything asynchronously. But the real secret sauce is this “live” dependency graph: it prevents unnecessary bottlenecks, avoids false dependencies, and lets the simulation scale up with more realism and less wasted effort. Without this, adding more agents or hardware just hits a synchronization wall—no matter how much parallelism you have available, you’re only as fast as your slowest, most entangled group. The spatiotemporal graph is what lets the simulation unlock true concurrency while preserving the logical rules of the world.
Example of use: In a synthetic customer journey simulation for a new retail experience, you can model 1,000 AI shoppers in a store, each moving independently, with checkout queues and product interactions only “coupling” the relevant agents. The dependency graph ensures that only those whose paths cross (e.g., at the same display or in a customer service line) have their timelines linked—so you can see emergent patterns like crowding or bottlenecks, without slowing everyone else down.
Example of misapplication: If a team ignores this detail and runs a synthetic A/B test by simply launching thousands of agents in lockstep “rounds” (e.g., every agent makes a decision at exactly the same time, regardless of their simulated context), they’ll create artificial chokepoints and lose the benefits of scale—output will be slow, and the simulation will miss emergent behaviors like real-time clustering or local surges in demand. Worse, the results may look mathematically valid but will fail to capture the messy, dynamic interactions that happen in real environments, leading to misleading conclusions about system robustness or market response.
🗺️ What are the Implications?
• Run larger synthetic audiences to better capture real group effects: The study shows that as the number of simulated personas grows (from 25 to 1000), the results become more reliable and approach the accuracy of an ""oracle"" (best-case) scenario—so for testing messaging, trends, or behaviors, use hundreds or thousands of AI personas, not just a small focus group.
• Don’t waste money on “faster” hardware or bigger models unless you can scale your simulation: The main performance bottleneck is how you schedule and parallelize AI persona responses, not the speed of any single computer or the sophistication of the AI model—so invest in smarter simulation design, not just more expensive tech.
• Prioritize realistic, dynamic scenarios over static or turn-based ones: Traditional step-by-step simulations force all personas to “wait their turn,” which slows things down and can distort results. The new approach—letting personas act when ready based on who they actually interact with—produces results faster and more closely matches real-world social dynamics.
• Use real-world-inspired social structures and clusters: Simulations that allow for flexible groupings (e.g., letting only those personas who actually interact coordinate their actions) better reflect how real people influence each other and avoid artificial bottlenecks or groupthink.
• Expect big gains in speed and scale—enabling more “what if” testing: By switching to smarter scheduling and dependency tracking, market researchers can run much larger, more complex experiments (dozens to thousands of personas, many scenarios) in less time and at lower cost, opening the door to rapid testing of multiple campaigns, innovations, or crisis responses before spending on real-world pilots.
• For business stakeholders: fund studies that embrace next-generation simulation engines: Backing teams that use these new methods ensures you get more data, faster answers, and a better preview of how real markets might react—making your research investment go further and reducing go-to-market risk.
📄 Prompts
Prompt Explanation: The AI model was prompted to role-play as an LLM-powered agent within a simulated environment, following a detailed multi-step behavioral loop that includes perceiving the environment, recalling memories, planning actions, and reflecting, all for the purpose of simulating realistic agent interactions.
You are an LLM-powered agent in a simulated world. At each simulation step, do the following in order:
1. Perceive your surroundings and recent events.
2. Retrieve relevant events from your memory.
3. Plan your next action based on the world state and retrieved events.
4. Follow your structured daily routine.
5. Occasionally reflect on your actions or experiences.
For each step, provide the necessary LLM call to process your tasks, using your unique personality, social relationships, and daily schedule as context.
⏰ When is this relevant?
A consumer banking provider wants to test how different customer types react to a new digital savings feature that automatically rounds up purchases and saves the change. The company wants to understand the likely response, objections, and motivators for three segments: Gen Z digital natives, mid-career professionals, and retirees.
🔢 Follow the Instructions:
1. Define audience segments: Draft short persona profiles for each segment, including attitudes, typical behaviors, and any key financial priorities. Example:
• Gen Z digital native: 23, uses mobile banking daily, values convenience and control, is skeptical of hidden fees.
• Mid-career professional: 42, busy with work and family, seeks time-saving solutions, moderate tech comfort.
• Retiree: 68, prefers simplicity, sometimes anxious about online security, focuses on protecting savings.
2. Prepare the prompt template: Use the following structure for each persona:
You are simulating a [persona description].
Here is the new banking feature: ""Our app will automatically round up every purchase you make to the nearest dollar and deposit the difference into your savings account. You can track these savings in real-time and withdraw at any time, with no fees.""
You are being interviewed by a banking product manager.
Respond as yourself in 3–5 sentences: What is your honest reaction? What do you like or dislike? Would you use this feature? Why or why not?
3. Run the prompt for each persona: For each customer type, generate 10–20 simulated answers by varying the persona's wording or slightly modifying the interviewer’s question (e.g., ""How do you feel about automation in savings?"" or ""Would this influence your choice of bank?"").
4. Add follow-up questions: Ask 1–2 follow-up questions based on typical first responses, such as ""What concerns would you have about using this?"" or ""What would make you feel more comfortable using this type of feature?""
5. Tag and summarize responses: Review the answers and note major themes like ""trust in automation,"" ""ease of use,"" ""fear of fees,"" or ""interest in building savings.""
6. Compare across segments: Summarize the key motivators and objections for each group, identifying which marketing messages or feature tweaks might increase adoption or overcome skepticism.
🤔 What should I expect?
You'll quickly get a clear, directional sense of which customer types are receptive to the new digital savings feature, what concerns matter most to each segment, and which messaging or product adjustments could drive better adoption—enabling you to prioritize outreach and future product iterations before launching to real customers.



