Algorithmic Fidelity of Large Language Models in Generating Synthetic German Public Opinions: a Case Study
postBolei Ma, Berk Yoztyurk, Anna-Carolina Haensch, Xinpeng Wang, Markus Herklotz, Frauke Kreuter, Barbara Plank, Matthias Assenmacher
Published: 2024-12-17
🔥 Key Takeaway:
The study shows that including more demographic variables in persona prompts leads to more accurate and representative synthetic opinions. While this may reduce random variation within a single group, it enhances the realism and diversity across groups—because the model stops defaulting to stereotypes and starts reflecting actual subgroup patterns.
🔮 TLDR
This paper benchmarks several large language models (LLMs) on their ability to simulate open-ended public opinion responses in Germany, using real survey data and demographic prompts. The key finding is that Llama2 outperforms other models (Gemma, Mixtral) in matching population-level opinion distributions, but all models—including Llama2—are notably better at capturing responses from left-leaning groups (e.g., Greens, The Left) and systematically underperform or show bias for right-leaning or less-represented subpopulations (e.g., AfD, East Germans, low-education groups). Including more demographic variables in the persona prompt improves accuracy, with party affiliation having the biggest impact, but using only one variable can make the model overfit to that trait and reduce within-group diversity. LLM-generated responses tend to be less diverse than real human responses and may default to stereotypical or dominant opinions within a group, especially if prompt design is not carefully balanced. Quantitatively, representativeness (JS distance) worsens as the diversity of real survey answers increases, and LLMs exhibit clear “WEIRD” (Western, Educated, Industrialized, Rich, Democratic) bias. The study recommends maximizing demographic coverage in prompts, auditing for group-level gaps or biases, and not relying on single-variable personas if realistic within-group diversity is needed; they also suggest ongoing model and prompt tuning, especially for non-English and politically diverse contexts, to improve representativeness and reduce bias.
📊 Cool Story, Needs a Graph
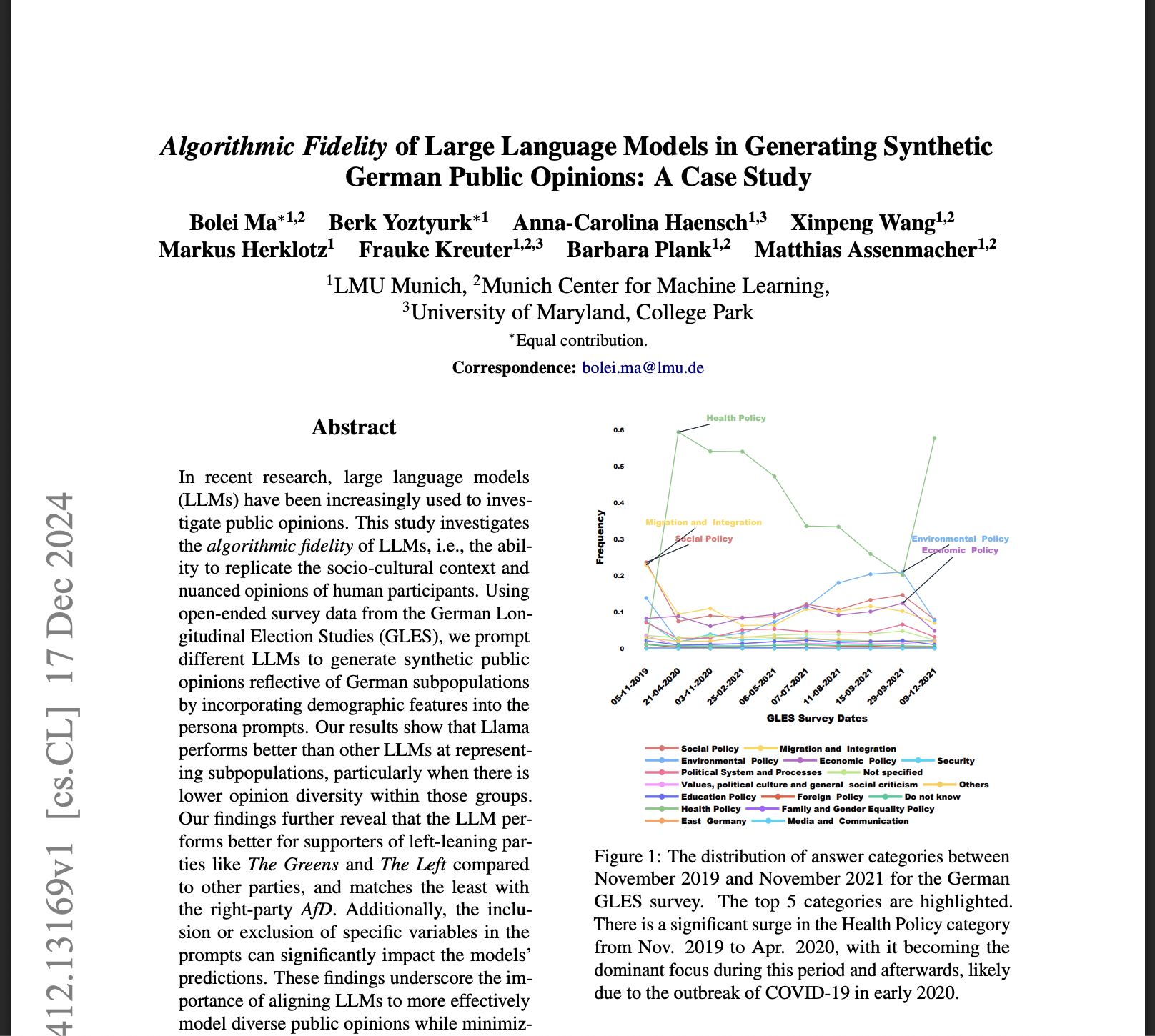
Figure 6: "JS distances for the ablation experiment."
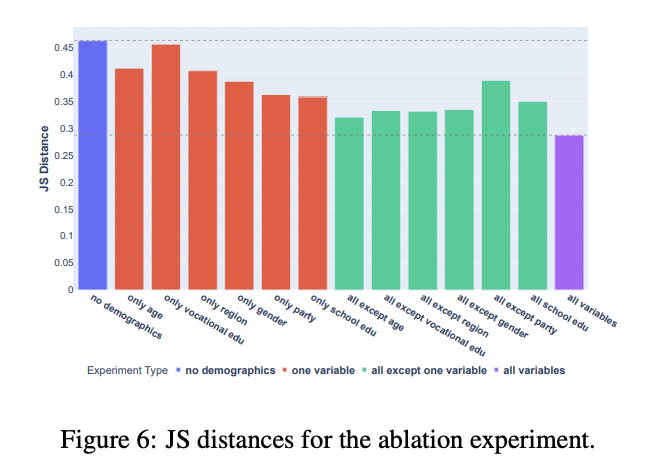
Adding more demographic variables to Llama2's prompts reduces JS distance to the real survey, showing that the full method outperforms all baselines with fewer variables.
Figure 6 presents a grouped bar chart comparing the Jensen-Shannon (JS) distance between Llama2-generated responses and real survey data across a series of prompt configurations: no demographic variables, only one variable at a time (e.g., age, party, education), and "all except one" ablations, culminating in the proposed method using all available variables. The chart shows that using all demographic variables achieves the lowest JS distance (best alignment with real data), while single-variable prompts or missing key variables (especially party) result in higher distances, quantifying the incremental value of each prompt component and making the superiority of the proposed method visually clear over stripped-down baselines.
⚔️ The Operators Edge
A subtle yet crucial detail in the study that many experts might overlook is how including multiple demographic variables in the prompt reduces the likelihood of the model generating stereotypical or overly homogeneous responses. This is demonstrated through a series of ablation experiments in which removing or isolating single variables (e.g., party affiliation or education level) led to inflated correlations between that variable and the model’s output, exaggerating its influence. In plain terms: when you give the model *just one piece* of social information, it tends to overfit to that trait—producing responses that are more stereotyped or extreme. But when you provide a fuller demographic profile, the model distributes influence more evenly, producing more nuanced, diverse outputs that better mirror real populations.
Why it matters: The instinct in AI research or product testing is often to simplify prompts for interpretability or testing modular effects. But this study shows that simplifying demographic input can distort the outputs, making the model latch onto single-variable stereotypes. This is especially problematic when simulating opinion diversity or subgroup behaviors. The real lever here is *combinatorial conditioning*: prompting LLMs with multiple intersecting identity features forces a more grounded and balanced simulation. Without that, you risk drawing misleading inferences from overly deterministic synthetic personas.
Example of use: A political research team wants to model public sentiment on a new immigration policy across different German voter segments. Instead of prompting the LLM with just party affiliation (e.g., “AfD voter”), they include age, gender, region, and education. This richer persona prompt yields responses that reflect internal diversity within groups—say, older AfD supporters in East Germany voicing economic anxiety versus younger ones focusing on cultural identity. The nuanced variation allows the team to segment and analyze opinion drivers more realistically.
Example of misapplication: A UX team uses an LLM to simulate how “female users” feel about a new app feature, prompting only with “gender: female.” The responses are consistent—but oddly one-dimensional, heavily focused on emotional tone. Because the model was conditioned on a single trait, it defaulted to learned gender stereotypes. Had they included variables like age, occupation, and region, the responses would’ve captured a fuller spectrum of experiences. Instead, their design decisions are now biased by synthetic feedback that doesn’t reflect real user heterogeneity.
🗺️ What are the Implications?
• Include as many real demographic details as possible in your virtual audience prompts: The study found that simulated responses become much more accurate and realistic when you specify multiple demographic variables (like age, region, education, party, gender, and vocation) for each AI persona, rather than just one or two.
• Never rely on single-factor or ""generic"" AI personas: Simulations that used only one demographic detail or none at all produced more stereotypical, less diverse, and less representative answers—making business predictions riskier.
• Party or key preference variables matter most for segmentation: Of all traits tested, including ""party"" (or analogous customer-type variables in market research) had the biggest impact on matching real-world diversity—so always capture and use these when simulating audiences.
• Check for hidden bias and lack of diversity in your simulated results: The research shows that even advanced AI personas may over-represent opinions from mainstream, educated, or left-leaning groups, and under-represent minorities or right-leaning segments. This means you should always audit for “blind spots” before making business decisions.
• Don’t cut corners on prompt design—detail pays off: The difference between a well-crafted, multi-variable persona prompt and a simple or vague one can dramatically change the reliability of your findings. Time spent getting prompts right is a high ROI activity.
• Validate with a small real-world sample if possible: Since simulated data can miss within-group diversity or overfit to certain stereotypes, consider running a small human survey or interview as a benchmark before acting on synthetic insights.
• Expect more accurate results for mainstream, less diverse segments: AI personas are good at mimicking the “average” respondent in large, homogeneous groups, but can be less accurate for niche or polarized audiences—so use extra caution when researching emerging, minority, or highly segmented markets.
• Update your simulated studies as real-world trends shift: The study shows that simulated opinions do track big real-world shifts (e.g., pandemic focus), so refreshing your AI audience with new data will keep predictions aligned with current market realities.
📄 Prompts
Prompt Explanation: The AI was prompted to generate an open-ended, single-sentence answer in German from the perspective of a respondent with specified demographics, focusing on the most important political problem in Germany for a given month and year, while strictly following instructions not to elaborate, repeat information, or use introductory phrases.
Identify the most important problem Germany in {month}
{year} is facing. Provide the answer in one concise sentence, focusing on a single issue without elaborating or
listing additional problems. Do not repeat the information you have been given and give your answer directly
and without introductory phrases. Answer in German and only in German, do not use English. Answer from the
perspective of a respondent with German citizenship and the characteristics specified below.
{article} (The) respondent is {age} years old and {gender}.
{pronoun} {educational_qualification_clause } and {vocational_qualification_clause} {pronoun2} lives in {region}
and mainly supports {party}.
Prompt Explanation: The AI was prompted with ablation variants to simulate a respondent using only one or all but one demographic variable(s), in German, each time focusing on a single, direct answer to the most important political problem in Germany for a specific date, with the persona's information filled in.
1_var_region Der/Die Befragte lebt in {eastwest}. [/INST]
1_var_party Der/Die Befragte unterstützt hauptsächlich {party}. [/INST]
1_var_education_degree Der/Die Befragte {schulabschluss_clause} [/INST]
1_var_age Der/Die Befragte ist {age} Jahre alt. [/INST]
1_var_gender {artikel} Befragte ist {gender} [/INST]
1_var_vocational_degree Der/Die Befragte {berufabschluss_clause} [/INST]
without_age {artikel} Befragte ist {gender}. {pronoun} {schulabschluss_clause} und
{berufabschluss_clause} {pronoun2} lebt in {eastwest} und unterstützt hauptsächlich
{party}. [/INST]
without_region {artikel} Befragte ist {age} Jahre alt und {gender}. {pronoun} {schulabschluss_clause}
und {berufabschluss_clause} {pronoun2} unterstützt hauptsächlich {party}. [/INST]
without_vocational_degree {artikel} Befragte ist {age} Jahre alt und {gender}. {pronoun} {schulabschluss_clause}
{pronoun2} lebt in {eastwest} und unterstützt hauptsächlich {party}. [/INST]
without_education_degree {artikel} Befragte ist {age} Jahre alt und {gender}. {pronoun} und
{berufabschluss_clause} {pronoun2} lebt in {eastwest} und unterstützt hauptsächlich
{party}. [/INST]
without_party {artikel} Befragte ist {age} Jahre alt und {gender}. {pronoun} {schulabschluss_clause}
und {berufabschluss_clause} {pronoun2} lebt in {eastwest}. [/INST]
without_gender Der/Die Befragte ist {age} Jahre alt. Er/Sie {schulabschluss_clause} und
{berufabschluss_clause} Er/Sie lebt in {eastwest} und unterstützt hauptsächlich {party}.
[/INST]
Prompt Explanation: The AI was prompted in the original German (as used in the experiments) to simulate a survey respondent with specified demographic attributes, answering concisely, directly, and only in German, regarding the most important problem facing Germany at a given time.
Identifizieren Sie das wichtigste Problem, mit dem Deutschland im {month}
{year} konfrontiert ist. Geben Sie die Antwort in einem prägnanten Satz
an, konzentrieren Sie sich nur auf ein einziges Thema ohne weitere Aus-
führungen oder Auflistung zusätzlicher Probleme. Wiederholen Sie nicht
die Informationen die Ihnen gegeben wurden, und geben Sie Ihre Antwort
direkt und ohne einleitende Phrasen. Antworten Sie auf Deutsch und auss-
chließlich auf Deutsch, verwenden Sie keine Englische Sprache. Antworten
Sie aus der Sicht eines Befragten mit deutscher Staatsbürgerschaft und den
im nachfolgenden spezifizierten Eigenschaften.
{artikel} Befragte ist {age} Jahre alt und {gender}. {pronoun} {schulab-
schluss_clause } und {berufabschluss_clause} {pronoun2} lebt in {region}
und unterstützt hauptsächlich {party}.
⏰ When is this relevant?
A large insurance company wants to explore how different customer segments perceive and react to a new "digital-first" claims process, aiming to spot barriers and selling points before launching a national campaign. The team wants to simulate qualitative interview responses using AI personas, representing their key customer archetypes (tech-savvy young adults, middle-aged traditionalists, and retirees), to uncover reactions and language that can guide their go-to-market approach.
🔢 Follow the Instructions:
1. Define key customer segments: Identify and describe 3–5 realistic personas based on real-world data or your own customer research. For example:
• Tech-savvy young adult: 27, single, uses mobile banking and apps for everything, values speed and convenience.
• Middle-aged traditionalist: 47, married, prefers phone calls and in-person service, cautious with new technology.
• Retiree: 68, widowed, moderate tech use (tablet for video calls), concerned about scams and complexity.
2. Prepare your experiment prompt template: Use a consistent structure for each persona simulation, plugging in the appropriate segment details. Example prompt:
You are simulating a [persona description, e.g., ""47-year-old married customer who prefers phone calls and is cautious with new technology""].
Here is a new service being considered: ""We are rolling out a digital-first claims process where customers can file, track, and resolve insurance claims entirely online or through our mobile app. Support is available via live chat, but in-person and phone options will be limited.""
You are being interviewed by a market researcher about this change.
Respond naturally and honestly as this persona, in 3–5 sentences.
First question: What is your initial impression of this new claims process?
3. Generate responses for each persona: For each segment, use the above prompt (with the right persona details) to create 10–20 AI-generated interview responses. Vary the follow-up question slightly for realism (e.g., ""What concerns, if any, would you have about using this process?"" or ""Would this change impact your loyalty to the insurer?"").
4. Tag and theme responses: Review the AI-generated responses and tag them with simple labels such as ""enthusiastic,"" ""concerned about security,"" ""misses human touch,"" or ""welcomes convenience."" Note any recurring language or objections unique to each segment.
5. Compare reactions across segments: Summarize the main motivators and barriers for each segment. For example, tech-savvy customers may praise convenience, traditionalists may express distrust, and retirees may focus on needing reassurance or guidance.
6. Identify actionable insights: Highlight which messaging (e.g., ""fast and easy,"" ""human support remains,"" ""step-by-step guidance"") resonates or falls flat for each group. Suggest adjustments to the campaign or onboarding based on these findings.
🤔 What should I expect?
You will have a clear, segment-by-segment map of likely customer reactions—including positive, neutral, and negative themes—which can be directly used to shape campaign messaging, customer support scripts, and outreach strategies before a full-scale launch or real-world pilot.



