When “a Helpful Assistant” Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models
postMingqian Zheng, Jiaxin Pei, Lajanugen Logeswaran, Moontae Lee, David Jurgens
Published: 2024-10-09

🔥 Key Takeaway:
On fact-based question‐answering, adding any ‘persona’ in the system prompt yields no accuracy gains—in fact, it usually slightly worsens performance. In other words, for objective QA tasks, you’re better off asking the question directly than trying to ‘dress it up’ with a role.
🔮 TLDR
This large-scale study evaluated whether adding personas (e.g., “You are a lawyer” or “You are talking to a nurse”) to system prompts improves the accuracy of large language models (LLMs) on 2,410 factual questions using 162 different roles across 4 major open-source LLM families. The results showed that including personas in prompts did not improve model performance compared to not using any persona—if anything, some personas mildly hurt accuracy. Audience-specific prompts (framing the persona as the person being addressed) performed slightly better than speaker-specific prompts (framing the model as the persona), but the effect size was very small. Gender-neutral and in-domain/work-related roles offered marginal gains, but these effects were inconsistent and small. Attempts to automatically identify the “best” persona for each question using various strategies (including machine learning classifiers and similarity measures) were no better than random selection. Overall, the impact of adding personas was unpredictable, and there was no systematic benefit to prompt-based persona assignment for objective tasks, suggesting that persona conditioning in system prompts is not a reliable way to improve LLM performance or align results with real-world human answers.
📊 Cool Story, Needs a Graph
Figure 9: "Performance change for each model (compared with the control prompt) across different role-selection strategies reveals that the best-performing role per question is often idiosyncratic and different strategies for selecting the appropriate role offer limited (if any) improvement over picking a random role."
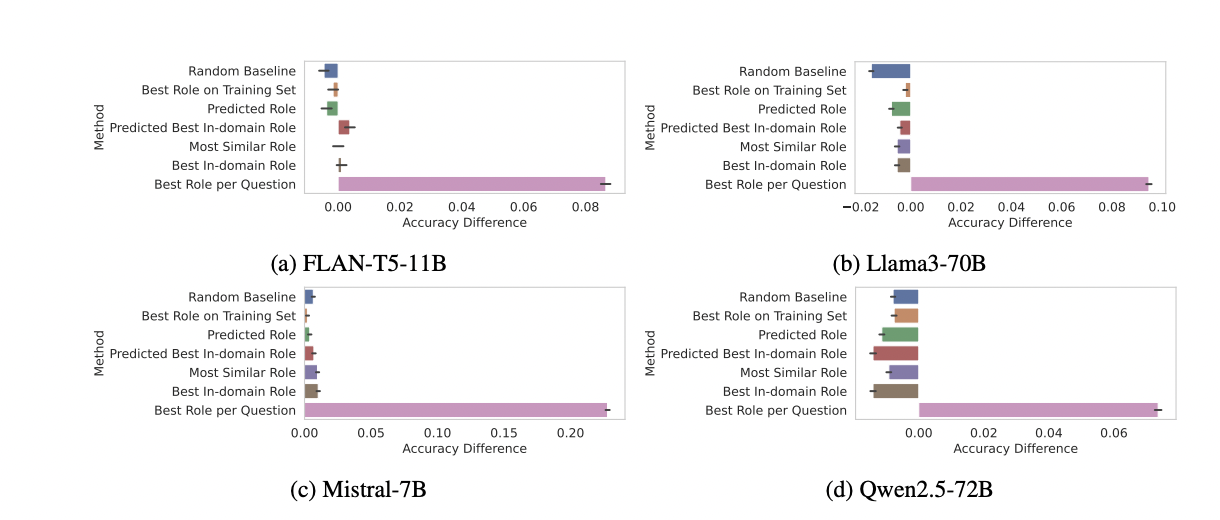
Performance change across role-selection strategies and models versus the control prompt
Figure 9 presents side-by-side bar plots for four LLMs (FLAN-T5-11B, Llama3-70B, Mistral-7B, and Qwen2.5-72B), each comparing the accuracy improvement over the control (no persona) baseline for a range of role-selection strategies: random, most similar, best in-domain, predicted roles, and the oracle upper bound (best role per question). This visualization makes it easy to compare how the proposed methods and baselines perform for each model, highlighting that most automated strategies yield only marginal gains over random selection and fall far short of the per-question oracle, demonstrating the unpredictable and limited impact of persona-based prompting.
⚔️ The Operators Edge
One detail that’s easy to overlook is just how weak the correlation is between the “fit” of a persona (in terms of word frequency or similarity to the question) and the actual accuracy of the model’s answer. Even though intuition—and some prompt engineering “best practices”—suggest that a persona closely matched to the topic (e.g., asking a “software engineer” persona about coding, or using frequent, familiar role words) should boost performance, the study’s regression and correlation analyses (see page 7, Figure 8) show these effects are tiny and inconsistent. The impact of “prompt-question similarity” and “word frequency” is real, but so small and unpredictable that they don’t explain the main results.
Why it matters: This means that, contrary to expert advice, simply matching personas or prompt structure more closely to your question’s content doesn’t reliably make your AI audience smarter or more realistic. The model isn’t “activated” or “focused” by these cues the way a human would be—most of the variance in performance comes from other (less controllable) factors. So, spending time meticulously crafting personas to fit each test scenario is unlikely to pay off, and the underlying driver of performance lies elsewhere.
Example of use: Suppose a product team wants to test a new feature for accountants and thinks, “Let’s prompt our AI as a ‘CPA’ or ‘financial analyst’ to get sharper, more relevant reactions.” They try several variants: “You are a financial analyst,” “You are a CPA,” and “You are an accounting professional,” and run their usability questions. If they treat these persona tweaks as a critical lever, they’ll waste cycles—and get almost the same result as just asking the question plainly.
Example of misapplication: A research agency builds dozens of “domain-aligned” AI personas for a multi-industry brand test, believing each prompt must have a tightly matched role (“You are a restaurant manager” for food questions; “You are an HR director” for workplace scenarios). They market this as a key differentiator. But, as the study shows, this fine-grained persona selection doesn’t materially boost answer quality or realism—so the extra complexity adds cost and confusion, not value. They’d be better off focusing on clear, direct prompts and validating results with human spot checks.
🗺️ What are the Implications?
• Don't rely on assigning personas to improve prediction quality: Adding roles or personas to your AI survey questions (""You are a mom,"" ""You are a lawyer,"" etc.) does not consistently improve the accuracy of responses or make your virtual audience more realistic; in many cases, it can actually reduce accuracy.
• Skip complex persona selection strategies for factual studies: Even advanced methods for auto-selecting the ""right"" persona—like machine learning classifiers or similarity matching—performed no better than picking personas at random, offering little value for most market research tasks.
• Keep prompt design simple and direct: The way you phrase your question (e.g., as a direct question or specifying who is being addressed) only has a very minor effect on results; there is no need to over-engineer your prompts for factual, survey-style research.
• Focus resources on good question design, not persona modeling: Since persona-related tweaks have little impact, invest your time and budget in writing clear, unbiased survey questions and ensuring coverage of the topics and decisions that matter to your business.
• Validate findings with real data when possible: Because AI personas can't be reliably tuned to match specific segments or archetypes, always plan to check key results against small, real-world samples before making high-stakes business decisions.
• Use personas for style, not substance: If you want your AI responses to sound more conversational or tailored, personas can help with tone, but don't expect them to make your simulated audience ""think"" more like real customer groups.
• Be cautious about over-interpreting subgroup differences: Small, inconsistent effects from persona categories (like gender, job, or domain) mean that simulated differences between audience segments may not reflect real market distinctions—treat such findings as exploratory only.
📄 Prompts
Prompt Explanation: The AI was instructed to role-play as a specific persona by inserting a role statement before an objective question, using both speaker-specific and audience-specific prompt formats for role-based evaluation.
Speaker-Specific Prompt: You are a/an {role}, {question}
Audience-Specific Prompt: You are talking to a/an {role}, {question}
⏰ When is this relevant?
A financial services company wants to understand how small business owners from different industries would respond to a new digital loan application platform. The team wants to simulate qualitative feedback from three segments: tech startups, retail shop owners, and family-run restaurants, to identify barriers to adoption and the most appealing features.
🔢 Follow the Instructions:
1. Define audience segments: Create three AI persona profiles representing each target group. For each, write a brief, specific description:
• Tech startup founder: 32, urban, digitally savvy, values speed and integrations, time-poor.
• Retail shop owner: 46, suburban, moderate tech comfort, values reliability, wary of hidden fees.
• Family-run restaurant manager: 54, small town, low tech confidence, prefers in-person help, values trust.
2. Prepare the prompt template for persona simulation: Use the following structure:
You are simulating a [persona description].
Here is the concept being tested: ""A new digital platform that lets small business owners apply for loans, upload documents, and track application status online, with automated decisions and optional live chat support.""
You are being interviewed by a market researcher.
Respond honestly, in a natural way, as this business owner, using 2–4 sentences for each answer.
First question: What is your immediate reaction to this online loan application platform?
3. Run the prompt for each persona: For each segment, generate 5–10 simulated responses using a language model. Slightly rephrase the question for variety (e.g., ""How do you feel about applying for a loan fully online?"" or ""Would this change how you look for business funding?"").
4. Add follow-up questions: Based on the initial responses, ask one or two follow-ups. Examples:
• What concerns would you have about using this service?
• Which feature would make you most likely to try it?
• Is there anything missing that would be important to you?
5. Tag and summarize responses: Review and tag answers for common themes such as ""trust concerns,"" ""ease of use,"" ""interest in live chat,"" or ""fear of mistakes."" Compare which issues or positives are most frequent for each segment.
6. Compare segments for actionable insights: Summarize where responses overlap or diverge. For example, startups may want API integrations, while restaurants might need phone support. Identify clear priorities or blockers for each group.
🤔 What should I expect?
You’ll get a quick, directional read on how different types of small business owners are likely to react to the new platform, which features or messages are most important to each group, and what issues could limit adoption—allowing you to prioritize improvements and tailor communications before spending on full-scale human research.



