Llm-based Robot Personality Simulation and Cognitive System
postJia-Hsun Lo, Han-Pang Huang, Jie-Shih Lo
Published: 2025-05-16

🔥 Key Takeaway:
Integrating structured short- and long-term memory, emotion appraisal, and theory-of-mind modules into an LLM-based robot (Mobi) enables it to exhibit stable Big-Five personality traits and human-like reasoning.
🔮 TLDR
This paper presents a cognitive framework for simulating personality in AI agents, combining Cattell’s 16 Personality Factors, Kelly’s Role Construct Repertory, and user preferences, and operationalizes it with ChatGPT-4 to generate human-like conversational, emotional, and intentional behaviors. The architecture integrates short- and long-term memory (using document embeddings and buffer lists), emotion generation, and intention planning to produce responses that reflect both programmed traits and context. Validation was performed by configuring a service robot (“Mobi”) to mimic a researcher’s personality and comparing its output to 30 human subjects using IPIP-NEO and Big Five personality assessments: results showed high consistency (R²=0.86) between simulated and real traits, with Cronbach’s alpha >0.75 for all dimensions, and mean cross-scale correlations for synthetic personalities (0.75) matching those for humans (0.78). The system outperformed GPT-4 on the ToMi “theory of mind” benchmark for memory and second-order belief tasks, indicating advanced social-cognitive modeling. Actionable takeaways: (1) use multi-theory trait models and prompt engineering for richer persona simulation; (2) implement both content- and time-based long-term memory retrieval with MMR for coherent recall; (3) validate persona stability with standard psychometric tests and cross-scale correlations; (4) include intention and emotion modules for more realistic and purposeful agent responses; (5) expect some increased computational latency (10–15s per turn); (6) anticipate that diversity in synthetic persona responses can match human variability, but with slightly higher spread.
📊 Cool Story, Needs a Graph
Figure 11: "Correlation between IPIP-NEO and Big Five of 30 personality compared to 31 human subjects."
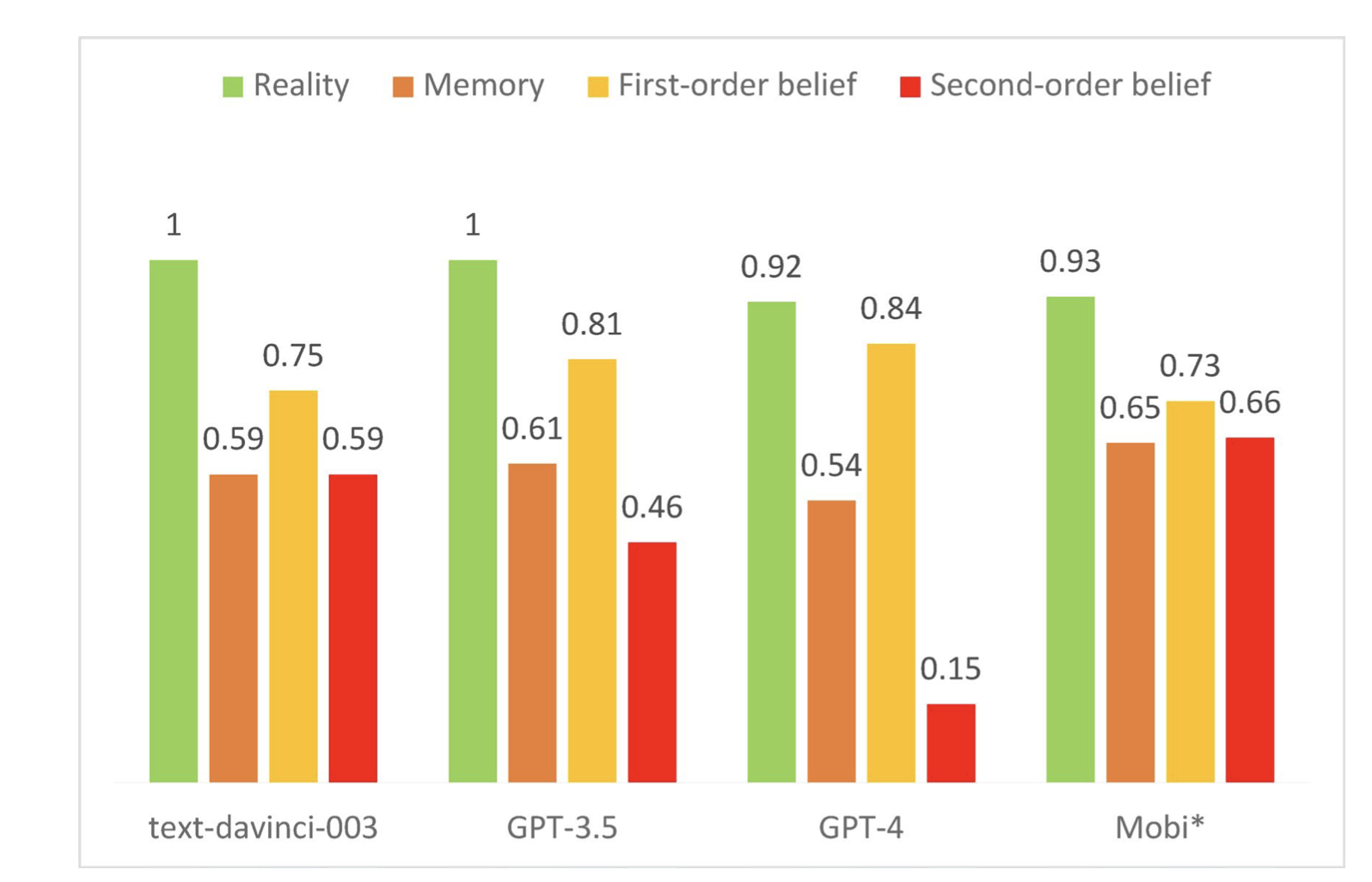
ToMi performance comparison across all LLM and agent baselines and task types.
Figure 11 (page 14) presents a grouped bar chart that compares the performance of the proposed Mobi cognitive architecture with three other LLM-based baselines (text-davinci-003, GPT-3.5, GPT-4) on the ToMi (Theory of Mind improved) benchmark, across four task categories: Reality, Memory, First-order belief, and Second-order belief. Each bar shows the accuracy for a specific agent and task, letting viewers quickly see where Mobi outperforms (notably on Memory and Second-order belief) or lags behind the other models. This single view clearly demonstrates the comparative strengths of the proposed method against all relevant baselines and across all major theory-of-mind competencies tested.
⚔️ The Operators Edge
A subtle but crucial detail in this study is that the personality simulation’s stability and realism depend heavily on validating the AI personas across *multiple independent psychometric inventories*—specifically, both the IPIP-NEO and the Big Five scales—and then statistically confirming high cross-scale agreement. This dual-assessment approach is not just for show: it puts a “stress test” on the synthetic personas, revealing whether their responses are robust to different ways of measuring personality, not just overfitting to one inventory’s quirks. The researchers even report the correlation (R² = 0.86) between the two scales for both humans and AI, and show that when this is high, the simulated results hold up much better in downstream tasks.
Why it matters: Most experts focus on getting the right persona inputs or prompt structure, but this study demonstrates that *the real check is whether your synthetic audience gives consistent answers across multiple personality frameworks*. If your AI personas only “look right” in one test but fall apart in another, their simulated feedback is likely fragile and will break if you change measurement tools or research context. Cross-scale validation acts as a hidden lever, increasing the trustworthiness and transferability of your results—especially when adapting simulations to new markets or different types of concept tests.
Example of use: A market insights team developing AI-driven focus groups for a new beverage could first generate personas using demographic and psychographic data, then run both the IPIP-NEO and a Big Five quiz on each persona and check for high agreement. If the scores line up, they can be more confident that subsequent taste test simulations, pricing reactions, or brand fit studies will generalize—because the personas are not overly tied to a single model of “consumer personality.”
Example of misapplication: A team skips this cross-validation and only tests their AI personas against one framework (say, just the Big Five), finds good alignment, and proceeds to run synthetic competitive positioning or ad reaction studies. Later, when they change research vendors or adapt the study for a new region using a different psychometric tool, the synthetic audience’s reactions suddenly diverge or lose realism—revealing that the original personas were brittle, and insights drawn from them are potentially misleading. The root cause was missing this extra validation step that would have surfaced the hidden mismatch before it became a business risk.
🗺️ What are the Implications?
• Combine multiple personality theories for richer synthetic audiences: Simulations that blend widely used models (like the Big Five) with additional frameworks (such as Cattell’s 16 Personality Factors and Kelly’s role constructs) better reflect real-world diversity and decision drivers, making results more lifelike and actionable.
• Validate your simulated personas with real psychometric tests: Before you trust survey or concept test results from a synthetic audience, run standard personality inventories (like IPIP-NEO or BFI) on your AI personas to check their consistency and realism against human benchmarks.
• Incorporate memory and experience into synthetic personas: Simulated audiences that use long-term and short-term memory (not just static demographics) produce more realistic, context-aware responses—helpful for product journey mapping, repeat purchase simulations, and storytelling research.
• Use intentionality and emotion modules for more believable responses: Personas that simulate underlying intentions and predict emotions (not just “yes/no” answers) are more likely to mimic real consumer reactions to branding, conflict, or emotionally charged propositions.
• Benchmark your AI audience against other leading models: Figure 11 (page 14) shows that different AI systems vary in their ability to match human-like responses on tasks like memory or “theory of mind”—so compare outputs from at least two models to avoid blind spots.
• Expect some variability—use larger samples or repeated runs: Synthetic personas can match human answer patterns on average, but individual responses may vary more than in real panels; running larger virtual audiences or repeating experiments helps smooth out random noise.
• Factor in practical constraints—allow for slower turnaround if using advanced features: More sophisticated personality, memory, and emotion modeling can slow down simulation speed (10–15 seconds per response), so plan accordingly if you need quick turnaround or high throughput.
• Consider “digital twin” approaches for deep-dive studies: For high-value segments, create simulation personas that mirror real customers’ past experiences, memory, and personality—not just their demographics—to better predict future reactions to new products or campaigns.
📄 Prompts
Prompt Explanation: The AI is instructed to simulate robot persona role-play using a prompt template that incorporates rules, a detailed personality model (combining Cattell’s 16PF, Kelly’s repertory, and preferences), background, and optional speaking tone, with all responses driven by LLM prompt engineering to emulate individual or scenario-specific traits.
The prompting templates comprise several components: rules, a personality model, backgrounds, and speaking tone, which is the core to simulates one’s personality. The rules confine the scope of potential responses, specifying constraints such as output type and maximum word count. The personality model and background characterize the role played, tailored to various settings. The speaking tone is an optional element that can be specified if a particular style of communication is required.
⏰ When is this relevant?
A quick-service restaurant chain wants to test customer reactions to a new digital loyalty program targeting three audience segments: tech-savvy young adults, value-focused families, and older traditional diners. The goal is to simulate qualitative interview feedback from these groups using AI personas, so the brand can understand what features excite each segment, what concerns arise, and how best to message the launch.
🔢 Follow the Instructions:
1. Define audience segments: Draft three AI persona profiles based on real customer data or marketing personas. For example:
• Tech-savvy young adult: 25, single, lives in a city, uses food delivery apps, values speed and digital rewards.
• Value-focused family: 40, married with two kids, suburban, looks for deals, wants easy family meals, open to digital but not early adopters.
• Older traditional diner: 62, retired, prefers in-person ordering, values personal service, less comfortable with apps but loyal to the brand.
2. Prepare prompt template for AI personas: Use this template to simulate realistic customer feedback:
You are simulating a [persona description].
Here is the new offer: ""We're launching a digital loyalty program in our app. Earn points for every purchase, get surprise rewards, and unlock exclusive menu items. You can track progress and redeem instantly from your phone or at the register.""
You are in a one-on-one interview with a market researcher.
Respond naturally and honestly as your persona. Give 3–5 sentences about your first impressions, what you like or dislike, and any questions you have.
First question: What is your honest reaction to this new loyalty program?
3. Run the prompt for each persona type: For each persona, generate at least 5 simulated responses using the above prompt. Slightly rephrase the question or context to encourage variety (e.g., ""Would this make you visit more often?"" or ""Is there anything that would stop you from using this?"").
4. Add follow-up questions: Based on the responses, ask logical follow-ups (e.g., ""How easy does the app need to be for you to use it regularly?"" or ""Would special family rewards or birthday bonuses make a difference?""). Capture these as conversational threads.
5. Tag key response themes: Review all responses and label them with simple tags like ""positive on convenience,"" ""concern about technology,"" ""wants more family rewards,"" ""prefers paper coupons,"" or ""excited by exclusives."" Note any emotional reactions or repeated themes.
6. Summarize findings by segment: Compare the feedback from each persona group. Identify which loyalty program features generate excitement, where skepticism or confusion arises, and what each group needs to see in messaging or design for adoption.
🤔 What should I expect?
You’ll get a clear, segment-by-segment view of how different customer types react to the new loyalty program, what features or messages are likely to drive sign-ups, and what obstacles could hinder adoption. This allows the business to prioritize messaging, refine app features, or plan follow-up research before investing in a full-scale human test or launch.



