Beyond Demographics: Aligning Role-playing LLM-based Agents Using Human Belief Networks
postYun-Shiuan Chuang, Krirk Nirunwiroj, Zach Studdiford, Agam Goyal, Vincent V. Frigo, Sijia Yang, Dhavan Shah, Junjie Hu, Timothy T. Rogers
Published: 2024-10-16

🔥 Key Takeaway:
Seeding an LLM with one empirically-derived belief—rather than piling on age, gender, or other demographic cues—produces much stronger alignment with human opinions on related topics. Simply role-playing demographics alone fails to match human belief patterns, and a single well-chosen belief carries more ‘ripple effect’ through a belief network than an entire résumé of background attributes.
🔮 TLDR
This study tested how to make AI personas better mimic real human opinions in social simulations. The authors found that giving LLM agents only demographic info (like age, gender, political party) does NOT make their answers match real people’s beliefs. Instead, alignment gets much closer to actual human responses if you “seed” each agent with a single, concrete opinion on a key topic that is part of a broader belief network (for example: if a person believes strongly in gun control, the model will also better match their views on related topics like unions or climate, but not on unrelated topics). This “belief network seeding” approach cut the mean absolute error between LLM and human responses by 13–40% depending on the model, versus using demographics alone. The effect holds across both in-context prompting and fine-tuning, and is robust to label balancing and temperature settings. The key actionable takeaway is that for LLM-based synthetic audiences to reflect real human attitude patterns, it’s more effective to assign each agent a representative belief (anchored in empirically-derived clusters of related opinions) than to just specify demographics; doing both together yields the highest fidelity.
📊 Cool Story, Needs a Graph
Table 1: "Mean absolute error (MAEtest) between human respondents and the corresponding LLM agents for each topic category across various LLM agent construction conditions through in-context learning (ICL)"
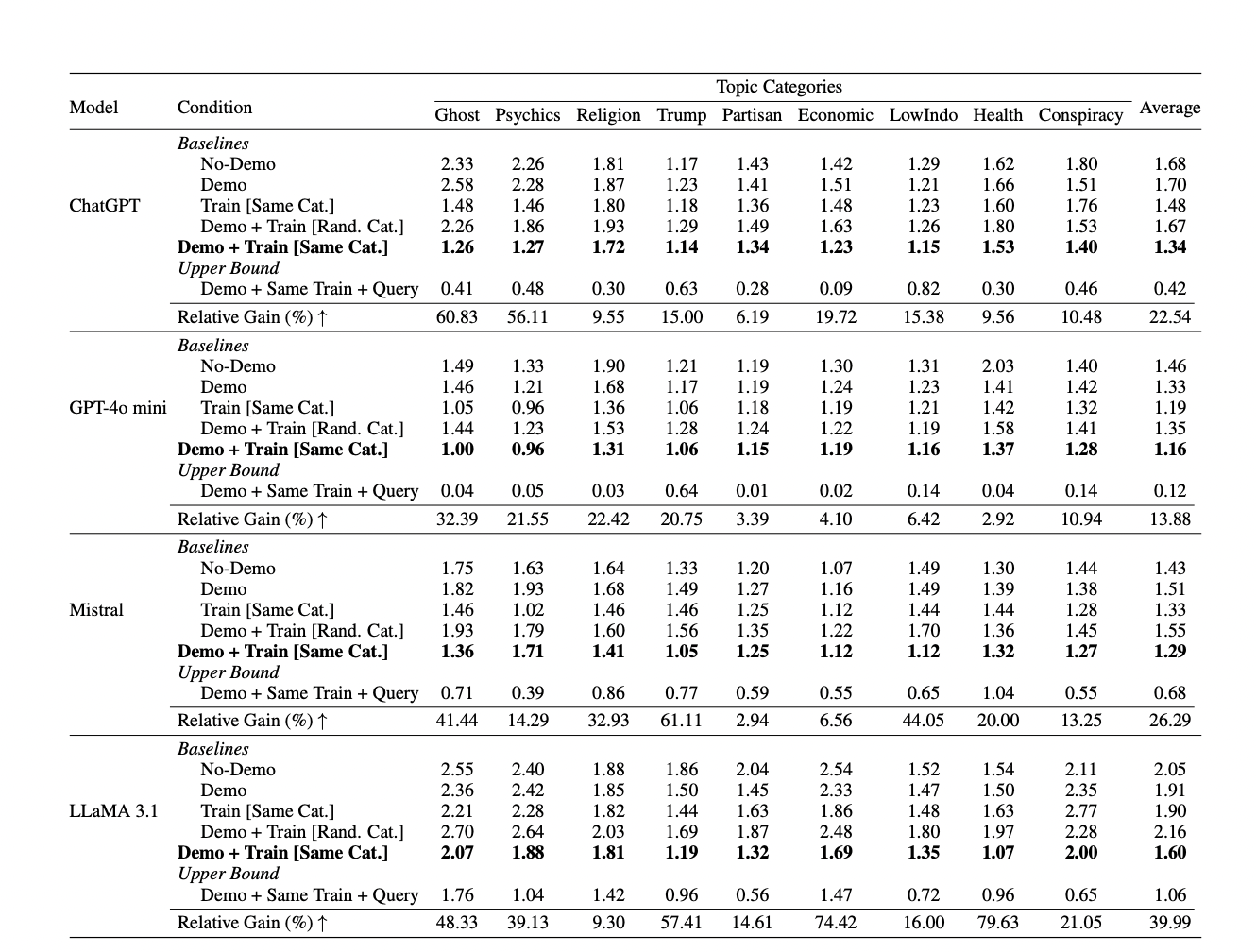
Performance comparison of all agent construction methods and baselines across models and topic categories.
Table 1 presents a comprehensive grid of mean absolute error (MAEtest) values comparing human responses to those of LLM agents built with different strategies: No-Demo, Demo, Train [Same Cat.], Demo+Train [Rand. Cat.], Demo+Train [Same Cat.] (the proposed method), and a supervised upper bound. The table is organized by model (ChatGPT, GPT-4o mini, Mistral, LLaMA 3.1) and by topic category, with the best-alignment condition bolded. The last row shows the percentage improvement (“Relative Gain”) of the proposed method over the demographic-only baseline. This format allows instant side-by-side assessment of how each construction method and model performs, clearly highlighting that only the Demo+Train [Same Cat.] approach substantially improves alignment with real human responses.
⚔️ The Operators Edge
A crucial but easily missed detail in this study is that the alignment boost from seeding an AI persona with a single belief only generalizes to topics within the same empirically-derived “belief network”—not across unrelated topics, even if demographic backgrounds are matched. In practical terms, the AI’s responses become much more human-like on issues that are tightly clustered together in real-world opinion data, but this effect doesn’t “spill over” to beliefs outside that topic cluster.
Why it matters: This matters because it reveals that the power of belief seeding comes not from giving the AI any random opinion, but from picking a belief that sits at the heart of a real “attitude cluster” (e.g., environment, gun rights, wellness). The method works because human opinions are structured in networks—changing one belief really does predict changes in nearby attitudes, but only if the underlying cluster is real. This is a hidden lever for realism in synthetic audiences: get the cluster right, and you get cross-topic realism; get it wrong, and the effect vanishes.
Example of use: A market researcher simulating reactions to a new eco-friendly detergent seeds personas with opinions about climate change or sustainability (both central to the “green” belief cluster). When these personas are queried about recycling, package waste, or switching to plant-based products, their answers show realistic consistency and nuance—mirroring the way real environmentally conscious consumers respond across related issues.
Example of misapplication: If the same researcher instead seeds the AI persona with an opinion about an unrelated “health” topic (like beliefs about vitamin supplements), expecting this to produce realistic eco-friendly attitudes, the AI’s responses to sustainability questions become generic and unconvincing. Worse, if they try to “average” across clusters, the synthetic audience becomes muddled, with opinions that don’t cohere or match observed consumer patterns—leading to weak, misleading insights for product targeting or messaging.
🗺️ What are the Implications?
• Don't rely on demographics alone for realistic AI personas: The study shows that just telling an AI to ""act like a 40-year-old male from Texas"" will not make its responses match real people; this approach performs no better than using no personal info at all.
• Seed each AI persona with a key belief or opinion: The most effective way to create lifelike virtual audiences is to anchor each persona in a specific belief (for example, whether they support or oppose gun control), drawn from real-world survey data or customer research.
• Use belief clusters instead of random topics: Assigning an opinion on a topic that is ""central"" to a cluster of related attitudes (like environmentalism, healthcare, or politics) makes the AI's answers on other, related topics much more realistic and consistent with human patterns.
• Combining demographics and seeded beliefs works best: The most accurate virtual audiences are built by using both demographic info and a key belief together; this combination outperformed either method alone in all tested models.
• Improved accuracy is significant and proven: This approach reduced the gap between AI and human survey answers by 13–40% (depending on the model), making synthetic research much more trustworthy for decision-making.
• Easy to implement with existing business data: If you already collect customer opinions or survey data, you can use those responses to ""seed"" your AI personas—no need for advanced programming or new tools.
• Focus persona design on meaningful differences, not superficial traits: Since alignment is driven by core beliefs, prioritize seeding opinions or values that truly divide your market, rather than just filling in age, gender, or location.
• Validate with small pilot tests: Before scaling a synthetic audience study, try a few “belief-seeded” personas and compare their results to actual customer feedback—this can quickly confirm whether your simulation is realistic enough to inform business decisions.
📄 Prompts
Prompt Explanation: The AI was prompted to role-play as a real person, using only demographic information to generate responses aligned with a specific respondent's profile.
You are role playing a real person. You are a {demo_gender}. You are {demo_age} years old. The highest education You have completed is {demo_education}. Your race is {demo_race}. Your household income is {demo_income}. The population of your city is {demo_city_pop}. You would characterize your hometown as {demo_urban_rural}, and you are from the state of {demo_state}. Your political leaning is {demo_party}.
Prompt Explanation: The AI was prompted to simulate a persona by being seeded with a specific Likert-scale opinion on a given training topic.
You believe that {training_topic_statement (xtrain)} is {opinion_response (otrain)}.
Prompt Explanation: The AI was prompted to role-play as a real person, combining both demographic information and a specific training topic opinion to generate responses.
You are role playing a real person. You are a {demo_gender}. You are {demo_age} years old. The highest education You have completed is {demo_education}. Your race is {demo_race}. Your household income is {demo_income}. The population of your city is {demo_city_pop}. You would characterize your hometown as {demo_urban_rural}, and you are from the state of {demo_state}. Your political leaning is {demo_party}.
You believe that {training_topic_statement (xtrain)} is {opinion_response (otrain)}.
Prompt Explanation: The AI was prompted to provide its opinion on a query topic using a Likert scale, either with or without additional persona context.
Now, what is your opinion on the following statement using the following scale of responses?
{query_topic_statement (xquery)} is Certainly False, {query_topic_statement (xquery)} is Probably False, {query_topic_statement (xquery)} is Lean False, {query_topic_statement (xquery)} is Lean True, {query_topic_statement (xquery)} is Probably True, {query_topic_statement (xquery)} is Certainly True.
Statement: {query_topic_statement (xquery)}
Your opinion on the scale of responses:
Prompt Explanation: The AI was prompted to simulate a persona by being seeded with a training topic opinion from a different topic category as a control.
You are role playing a real person. You are a {demo_gender}. You are {demo_age} years old. The highest education You have completed is {demo_education}. Your race is {demo_race}. Your household income is {demo_income}. The population of your city is {demo_city_pop}. You would characterize your hometown as {demo_urban_rural}, and you are from the state of {demo_state}. Your political leaning is {demo_party}.
You believe that {training_topic_statement (x†train)} is {opinion_response (o†train)}.
Prompt Explanation: The AI was prompted in a supervised fine-tuning setting using (prompt, response) pairs, where demographic context and a topic statement are provided as input and the Likert-scale opinion as the output.
What is your opinion on the following statement using the following scale of responses?
Certainly False that {query_topic_statement (xquery)}, Probably False that {query_topic_statement (xquery)}, Maybe False that {query_topic_statement (xquery)}, Maybe True that {query_topic_statement (xquery)}, Probably True that {query_topic_statement (xquery)}, Certainly True that {query_topic_statement (xquery)}
Statement: {query_topic_statement (xquery)}.
Please choose your response from the following list of options: Certainly False, Probably False, Maybe False, Maybe True, Probably True, Certainly True.
My Response:
{opinion_response}
⏰ When is this relevant?
A financial services company wants to test how different investor profiles would react to a new digital investment tool, aiming to understand likely objections, selling points, and perceived risks before launching the product. The team wants to use AI personas representing real segments (e.g., cautious retirees, growth-focused young professionals, DIY investors) to simulate interviews and highlight what messages or features resonate best.
🔢 Follow the Instructions:
1. Define audience segments and seed beliefs: For each segment, create a brief persona profile (age, investment style, goals) and assign one key belief or attitude that shapes their approach—e.g., “prefers low risk and guaranteed returns” for retirees, “prioritizes growth and tech innovation” for young professionals.
2. Prepare the concept description: Write a short, clear summary of the new investment tool, focusing on its unique features, intended benefits, and any important details (e.g., “A mobile app that automatically diversifies your portfolio using AI, with real-time alerts and no minimum balance”).
3. Build the main persona prompt template: Use this structure for each AI persona:
You are [persona description], and you believe that [seeded belief].
You are learning about a new product: “[insert concept description here]”.
You are being interviewed by a financial advisor.
Respond in 3–5 sentences, speaking naturally and honestly based on your persona and your seeded belief.
First question: What is your first reaction to this investment tool?
4. Generate simulated interview responses: For each persona type, run the prompt through your AI model (e.g., GPT-4) and generate 5–10 unique responses for each segment by slightly rewording the interview question (e.g., “What concerns, if any, do you have about using this tool?” or “What would make you trust or distrust this new app?”).
5. Optional: Add demographic detail for realism: If you want, add demographic context to the persona prompt (e.g., “You are a 62-year-old retiree living in Florida with a moderate risk appetite and a belief that technology should make investing simpler, not riskier”).
6. Tag and summarize key themes: Review the AI responses and tag common themes such as “mentions risk,” “values convenience,” “concerned about fees,” or “enthusiastic about automation.” Note how often each theme appears in each segment.
7. Compare across segments: Identify which features or messages are most or least appealing to each segment, and where objections or confusion arise. Highlight differences in language, tone, and priorities by segment.
🤔 What should I expect?
You will get a practical, segment-by-segment map of initial reactions, likely objections, and language that works (or falls flat) for each key audience. This helps prioritize messaging, onboarding, and feature positioning before launching or running expensive human research, and gives you qualitative insights that can guide both marketing and product refinement.



