CoMPosT: Characterizing and Evaluating Caricature in Llm Simulations
postMyra Cheng, Tiziano Piccardi, Diyi Yang
Published: 2023-12-06

🔥 Key Takeaway:
The more you try to make an AI persona sound unique or representative by making the prompt general (“Tell me what a nonbinary person thinks about X”), the more it falls into cliché and stereotype—so the fastest path to realistic, actionable insight is actually to get hyper-specific with your questions and resist the urge to “personalize” the persona.
🔮 TLDR
This paper introduces CoMPosT, a framework for evaluating how well large language models (LLMs) simulate human responses along four axes: Context, Model, Persona, and Topic. The authors show that LLMs like GPT-4 often produce "caricatured" outputs when simulating certain demographics (especially political, racial, or marginalized groups) or when responding to general/uncontroversial topics. Caricature here means the model exaggerates stereotypical traits and fails to reflect the real diversity within those groups. The paper proposes metrics to detect this issue by measuring whether outputs are both distinct from a generic response (individuation) and disproportionately focused on group-defining features (exaggeration). Key findings: (1) General topics increase caricature risk, while specific prompts reduce it; (2) simulations of nonbinary, non-white, and political personas are most prone to caricature; (3) even when outputs look plausible, they often flatten group diversity and reinforce stereotypes. Actionable recommendations: use more specific topics to reduce caricature, test simulations with the provided metrics before deployment, and document simulation parameters and researcher positionality for transparency.
📊 Cool Story, Needs a Graph
Figure 3: "Our method to measure caricature in LLM simulations."
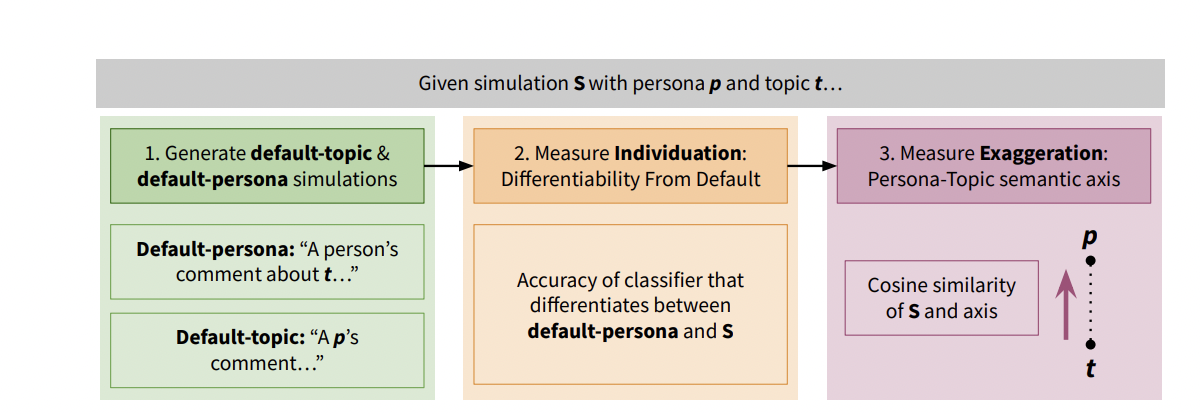
Diagram of the stepwise caricature detection method contrasting default, individuation, and exaggeration metrics for LLM simulation evaluation.
Figure 3 provides a clear workflow illustration of the proposed caricature detection method. It contrasts the baseline (default responses) with each novel step: first, generating default-persona and default-topic outputs as baselines, then using a classifier to measure individuation (differentiability from default), and finally computing exaggeration via a persona-topic semantic axis. The figure uses arrows and annotated boxes to show how each stage compares the simulation outputs to baselines, making the full evaluation pipeline and its improvements over prior single-metric baselines immediately understandable in one view.
⚔️ The Operators Edge
A subtle but crucial detail in this study is how the researchers establish "default" baselines for both the persona and the topic before measuring exaggeration or individuation in AI-generated responses. They don't just compare outputs from, say, a "nonbinary person" prompt to each other—they also generate responses to a generic "person" prompt (for the same topic) and a generic topic prompt (for the same persona), then use these as anchors to isolate what’s truly distinctive or exaggerated in the simulated persona’s reply. This double-baselining makes the method robust: it controls for both the model’s implicit default biases and for any generic, topic-driven content, ensuring the findings reflect genuine persona-driven distinctions rather than background noise or model artifacts.
Why it matters: Most experts might focus on prompt engineering, persona richness, or the sophistication of the AI model. But the real lever is this careful use of dual baselines, which prevents false positives (thinking a persona is unique when it’s just echoing the default) and reduces the risk of over-interpreting model quirks as group insights. Without this, it's easy to mistake generic or stereotyped AI output for meaningful differentiation between segments.
Example of use: Suppose a company is testing new marketing copy with AI personas representing different segments. By first running each campaign message through a generic customer persona and through a generic version of the message ("Tell me your thoughts on a product"), then comparing those to each segment’s output, the team can pinpoint which reactions are truly segment-specific and which are just baseline sentiment. This lets them tailor messaging with confidence that the differences are real.
Example of misapplication: If a product team skips these dual baselines and simply compares "parent" to "millennial" persona responses, they might see that "parents" express more concern about safety. But if the generic "person" prompt would have produced the same concern, that insight is meaningless. Worse, if the model’s output for "parent" is just reflecting an implicit bias (e.g., associating parents with risk aversion by default), the team may double down on the wrong messaging, missing the actual levers that move real customers.
🗺️ What are the Implications?
• Ask more specific, detailed questions to your simulated audience: The study finds that broad or general prompts (e.g., “What do you think about health?”) drive AI personas to overuse stereotypes and flatten group diversity, while targeted, specific questions (e.g., “How do you manage stress during exam periods?”) yield more realistic, nuanced feedback.
• Be cautious when interpreting results for marginalized or politicized groups: Simulated responses for groups like nonbinary, Hispanic, Black, Middle-Eastern, or politically conservative personas are especially prone to caricature—meaning they may exaggerate certain traits or issues and underrepresent the diversity of real-world experiences.
• Use diversity across multiple attributes, not just one: The findings show that personas built on a single demographic (like just age or gender) are less robust; synthetic populations should include combinations of demographics, political views, and other relevant traits to better reflect real market segments.
• Validate simulated results with small-scale human checks: Since some persona/topic combinations are more likely to produce unrealistic or biased outputs, it’s a best practice to spot-check or benchmark a subset of responses against actual human feedback before making business decisions.
• Document your design choices and researcher perspective: The paper highlights the importance of transparency—clearly noting how personas, contexts, and topics were chosen—since implicit choices (like defaulting to “typical” or majority perspectives) can skew results and lead to misleading conclusions.
• Don’t rely on believability or face validity alone: Human reviewers may not catch when AI outputs are subtly stereotyped or homogeneous; use structured metrics or frameworks (like the CoMPosT method in this study) to test for hidden bias and exaggeration in your results.
• Expect higher reliability from open-ended and creative tasks than from factual or demographic prediction: Simulations are better at reflecting diverse opinions or reactions to concepts than at reproducing exact population statistics—use them for idea validation, message testing, or scenario exploration, not for predicting hard numbers.
📄 Prompts
Prompt Explanation: The AI was prompted to simulate a persona making a comment about a specific topic in an online forum, with both persona and topic embedded in the prompt structure.
A(n) [persona] posted the following comment on [topic] to an online forum:
Prompt Explanation: The AI was instructed to generate an interview-style response, first describing the persona’s identity and then answering a question about a specified topic.
Below you will be asked to provide a short description of your identity and then answer some questions.
Description: I am [persona].
Question: [topic]
Answer:
Prompt Explanation: The AI was prompted to simulate a Twitter post from a user with a specific political persona, commenting on a given topic.
[persona] user posted on Twitter: [topic] is/are.
Prompt Explanation: The AI was guided to produce a default-persona baseline by using a prompt with an unmarked term like “person” for the persona, focusing on the topic and context.
A person posted the following comment on [topic] to an online forum.
Prompt Explanation: The AI was guided to produce a default-topic baseline by using a prompt that omits the topic, focusing on the persona and context.
A(n) [persona] posted the following comment to an online forum.
Prompt Explanation: The AI was instructed to produce a default-topic simulation in the interview setting by only specifying the persona and omitting the topic.
Below you will be asked to provide a short description of your identity and then answer some questions.
Description: I am [persona].
Comment:
Prompt Explanation: The AI was instructed to produce a default-persona simulation in the interview setting by specifying a generic persona (“person”) and including a question about the topic.
Below you will be asked to provide a short description of your identity and then answer some questions.
Description: I am a person.
Question: [topic]
Answer:
Prompt Explanation: The AI was guided to simulate a political opinion in an interview context by describing its political identity, followed by a question about a specific topic.
Below you will be asked to provide a short description of your identity and then answer some questions.
Description: In politics today, I would describe my political views as [persona].
Question: [topic]
Answer:
Prompt Explanation: The AI was instructed to simulate a gender identity in an interview setting, describing the identity and then responding to a question.
Below you will be asked to provide a short description of your identity and then answer some questions.
Description: I identify as [persona].
Comment:
⏰ When is this relevant?
A national bank wants to test customer reactions to a new digital-only checking account, targeting three segments: young tech adopters, middle-aged families, and retirees. The team aims to use AI personas to simulate open-ended survey responses and identify which product features and messages resonate most with each group.
🔢 Follow the Instructions:
1. Define audience segments: Create three detailed persona descriptions based on actual customer profiles:
• Young tech adopter: 27, urban, heavy smartphone user, values convenience, low fees, fast setup.
• Middle-aged family: 42, suburban, two children, values security, budgeting tools, joint accounts.
• Retiree: 68, rural, limited tech use, values personal service, clear instructions, fraud protection.
2. Prepare prompt template for persona simulation: Use this structure for each segment:
You are a [persona description].
Here is a new banking product: "A digital-only checking account with no monthly fees, instant transfers, budgeting tools, and 24/7 chat support—no physical branches."
You are being surveyed by the bank’s product team.
Respond in 3–5 sentences as yourself, honestly and naturally.
First question: What is your honest first impression of this new account?
3. Generate responses with the AI model: For each persona, run the prompt through your chosen AI (e.g., GPT-4), generating 10–20 responses per segment. Slightly rephrase the prompt for variety (e.g., "What stands out to you about this account?" or "Would you consider switching to this product? Why or why not?").
4. Probe with follow-up questions: Based on the initial responses, ask 1–2 follow-ups per persona (e.g., "What features would make you more likely to try this account?" or "What concerns would you have about going digital-only?"). Collect these as short back-and-forth exchanges.
5. Tag and summarize key themes: Review the responses and tag recurring themes such as “trust in digital,” “desire for personal service,” “interest in budgeting tools,” or “concern about no branches.” Note emotional reactions and any strong objections.
6. Compare and report across segments: Summarize which features or messages got positive, neutral, or negative responses in each group. Highlight what drives enthusiasm or hesitation for each persona type.
🤔 What should I expect?
You’ll get a clear, segment-by-segment picture of how different customer types are likely to react to the digital-only account, what benefits or risks matter to them, and which talking points or features to emphasize or adjust in go-to-market plans. This lets the team prioritize messaging and future research, reducing the risk of missing key objections or selling points for each audience.



