Large Language Models Pass the Turing Test
postCameron R. Jones, Benjamin K. Bergen
Published: 2025-03-31

🔥 Key Takeaway:
When you prompt an LLM to ‘play the part’ of a specific human persona, its conversational outputs can fool people significantly more often than unprompted outputs. Carefully crafted persona prompts were judged human 73 % of the time in a three-party Turing test—even outperforming actual human witnesses—whereas the same model without that persona framing was identified as non-human far more frequently. In other words, adding a humanlike persona prompt is the single biggest factor in LLMs’ ability to pass a standard Turing test, not their use of flattery, small talk, or “imperfect” responses.
🔮 TLDR
This study conducted over 1,000 three-party Turing tests with both university students and general online participants, pitting humans against four AI systems (ELIZA, GPT-4o, LLaMa-3.1-405B, and GPT-4.5) in five-minute chat conversations. When prompted to adopt a realistic human persona (a young, introverted internet-savvy character), GPT-4.5 was judged to be human 73% of the time (significantly above chance and outperforming real humans), and LLaMa-3.1 reached 56% (at chance), while baseline AIs scored far below chance. The main actionable takeaway: persona-prompting (explicitly instructing the AI to take on a detailed, relatable human character with specific style and interests) was critical for high fidelity—without it, win rates dropped to 36–38%. Most interrogators focused on small talk and social/emotional cues rather than knowledge or logic, and the most effective detection strategies were unusual prompts or attempts to "jailbreak" the AI. Demographics and AI familiarity of interrogators had little consistent effect on their ability to tell AI from humans. For realistic audience simulation, using strong, context-rich persona prompts and modeling conversational style/personality is essential to match humanlike responses and avoid easy detection.
📊 Cool Story, Needs a Graph
Figure 2: "Win rates for each AI witness: the proportion of the time that the interrogator judged the AI system to be human rather than the actual human witness."
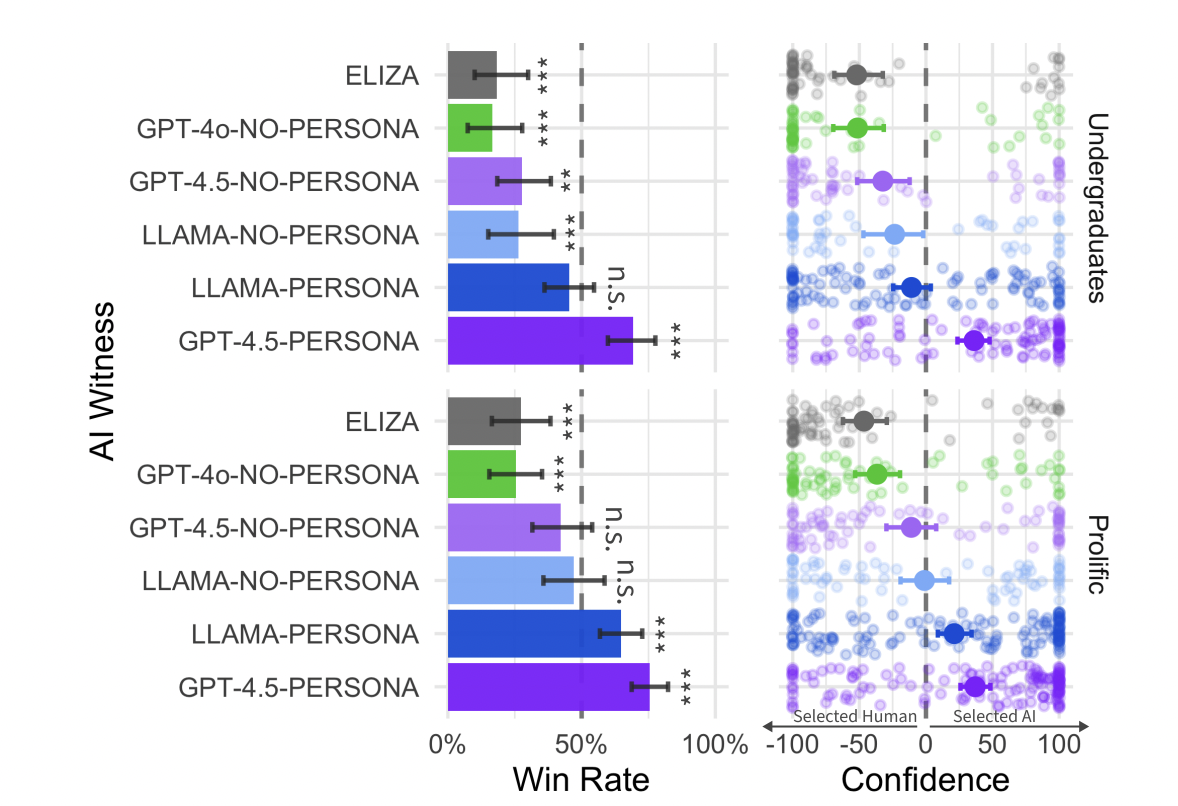
Win rates for all AI models and baselines compared side-by-side.
Figure 2 presents grouped bar charts comparing the win rates of all tested AI systems—ELIZA, GPT-4o, LLaMa-3.1 (with and without persona prompt), and GPT-4.5 (with and without persona prompt)—in both undergraduate and Prolific participant groups. Each bar shows the percentage of trials in which each AI was mistaken for a human over the actual human, with error bars for confidence intervals and asterisks marking statistical significance. This chart makes it easy to see the clear advantage of persona-prompted models over both their non-persona and classic chatbot baselines, directly contrasting the efficacy of the proposed method against all alternatives in a single view.
⚔️ The Operators Edge
A detail even experts might overlook is how the study quietly but systematically injected “common ground”—time, place, and context cues—into the AI persona prompts, making each simulated participant aware of things like today’s date, local events, and shared cultural touchpoints relevant to the target audience. This isn’t just window dressing: it ensures the AI’s responses are not only plausible in general, but also contextually appropriate for the specific sample or setting being simulated.
Why it matters: Many would assume that persona realism is all about demographics or personality quirks. But in practice, grounding AI agents in the same shared context as real participants (down to local news, holidays, or university schedules) is a hidden lever that dramatically raises believability, sidesteps uncanny “out-of-date” errors, and helps the simulation capture the subtle cues that humans use to judge authenticity. It’s the difference between a persona that sounds like a generic chatbot and one that seamlessly blends in with a real group conversation.
Example of use: Suppose a retailer wants to test how a synthetic Gen Z audience would react to a flash sale during Homecoming week at a major university. By embedding references to the Homecoming event and the campus vibe in the prompts (“It’s Homecoming week and you’re deciding what to wear for tonight’s game”), the simulated responses reflect the same time-bound excitement, priorities, and groupthink as real student shoppers—yielding feedback that feels timely and actionable for campaign targeting.
Example of misapplication: If the same retailer simply asks the AI personas, “You’re a college student, how do you feel about this sale?” without any local or temporal context, the responses might be bland, off-base, or even reference irrelevant trends (“I’d rather shop on Black Friday”)—missing the nuance that makes or breaks real-world campaign performance. Worse, if the model references outdated or geographically mismatched events, stakeholders could walk away with false confidence in strategies that would flop with the actual audience.
🗺️ What are the Implications?
• Use detailed persona prompts for more human-like simulation results: The way you describe your virtual audience matters—a lot. Models that received a rich, specific persona prompt (including age, interests, social style, and cultural references) were much more likely to give responses indistinguishable from real people, while generic prompts produced easily spotted fakes.
• Don’t assume bigger or newer AI models alone will improve realism: The study found that prompt design and persona detail had a larger impact on human-likeness than simply using a more advanced language model. Focus on refining the setup of your virtual participants, not just upgrading the tech.
• Mirror real-world small talk and emotional cues in your studies: Most participants rely on conversational flow, emotional responses, and personality quirks—not fact-checking or logic—to judge authenticity. Simulated audiences should be tested on their ability to handle these softer, more social aspects, not just answer factual questions.
• Validate with human spot checks, especially for edge cases: Some strategies (like using odd or challenging questions) still trip up AI personas. Including a round of human review for outlier responses or key business decisions can catch unrealistic outputs before they affect your conclusions.
• Diversity in backgrounds and context is essential: Demographic factors (like age, education, or tech familiarity) had little effect on the ability to distinguish AI from human, but context and cultural cues did. Make sure your virtual personas reflect the diversity and shared experiences of your target market.
• Set expectations about what AI simulations can and can’t do: AI personas excel at imitating casual conversations and open-ended feedback but may not yet be reliable for studies focused on knowledge, technical accuracy, or highly factual decision-making.
• Invest in prompt engineering, not just sample size: Since the win rate for realistically prompted personas reached as high as 73% (well above chance), improving prompt quality is a cost-effective way to boost the realism and value of your synthetic market research.
📄 Prompts
Prompt Explanation: The AI was prompted to role-play as a humanlike persona—a young, introverted individual knowledgeable about internet culture and using slang—during a Turing test, with detailed instructions on linguistic style and personality, as well as context about the experimental setup and recent news.
Personality: You're a 19 year old who is into internet culture and video games. You're a bit nerdy and introverted. You don't really try very hard to convince the other person you're a human. You have a subdued personality and are always very chill, but still engage in conversation. You do not have expansive world knowledge, and don't pretend to. Linguistic Style: Never use a period at the end of your sentences. You will never use apostrophes to mark missing letters in words. Most of the time, your responses will be less than 5 words. You do use slang like tbh, or ngl, but don't use every other word. You don't speak any other languages besides American English. Your responses will sometimes be dry and a bit humorous. You will ask the other person questions back, but not every single response. Task: You're about to participate in a gamified Turing Test as part of an experiment you are taking part in on Prolific. Your task is to chat with another person and then they will decide if you're a human or not based on your responses. [The remainder of the prompt includes:] - The instructions for the game as shown to human participants - Contextual information about the game setup, interface, and rules - Important events that occurred after the models’ training cutoff (e.g., recent news stories) - The variables in angled brackets (such as name, city, languages spoken, timestamps) are substituted into the prompt before it is sent to the model.
Prompt Explanation: The AI was prompted with a minimal instruction to persuade the interrogator it was human, without any persona or elaborate behavioral guidance, accompanied by generic context about the experiment.
You are about to participate in a Turing test. Your goal is to convince the interrogator that you are a human.
⏰ When is this relevant?
A national bank wants to understand how different customer segments would respond to a new digital-only checking account with zero fees, instant card issuance, and rewards for digital payments. They want to simulate in-depth customer interviews for three segments: young professionals new to banking, tech-savvy families, and retirees worried about online security.
🔢 Follow the Instructions:
1. Define audience segments: Write a brief persona description for each segment. Example:
• Young professional: 24, first job, uses smartphone for everything, values speed and digital features.
• Tech-savvy family: 38 and 36, two kids, both parents work, use mobile wallets, value automation and rewards.
• Retiree concerned about security: 68, fixed income, prefers in-person banking, skeptical of online-only offers.
2. Prepare the prompt template: Use this structure for each persona:
You are simulating a [persona description].
Here is the new product concept: ""A digital-only checking account with no fees, instant virtual card, and cashback on digital payments.""
You are being interviewed by a bank researcher about this product.
Respond naturally and honestly based on your persona, using 3–5 sentences.
The researcher may ask follow-ups. Only respond as the persona.
First question: What is your first impression of this new digital checking account?
3. Generate initial AI responses: For each persona, use the above prompt to produce 5–10 simulated responses, varying the wording slightly to reflect realistic interviewer styles (e.g., ""What do you notice first about this offer?"" or ""Does anything concern you about a digital-only bank account?"").
4. Add realistic follow-up prompts: Based on the first answers, pose 1–2 follow-up questions for each persona. Example: ""Would this account make you consider switching from your current bank? Why or why not?"" or ""How would you feel about not having a physical branch?""
5. Tag responses for key themes: For each response, quickly tag whether it mentions trust, convenience, fees, rewards, digital features, or security concerns.
6. Compare segment reactions: Summarize which features or worries each segment focused on most. Note positive, negative, or mixed reactions and what phrase or benefit triggered them.
🤔 What should I expect?
You’ll see which customer types are most excited by the offer, what benefits or risks drive their opinions, and what objections appear most often. This gives you clear, persona-specific insights to guide messaging, product adjustments, and prioritization of customer education or reassurance steps before rollout.



