Large Language Models That Replace Human Participants Can Harmfully Misportray and Flatten Identity Groups
postAngelina Wang, Jamie Morgenstern, John P. Dickerson
Published: 2025-02-03

🔥 Key Takeaway:
The harder you try to make your AI personas “realistic” by prompting with detailed demographic labels, the more likely you are to get bland, stereotyped, or even outsider-misguided answers—counterintuitively, using generic, behavior-based or quirky random personas (not “Black woman,” but “early tech adopter with a messy desk”) actually produces richer, more diverse, and actionable customer insights.
🔮 TLDR
This paper finds that large language models (LLMs) like GPT-4, when used to simulate demographic groups for research or market studies, systematically misrepresent and oversimplify those groups. Across 3,200 human participants and four LLMs, the models’ persona responses were often closer to how outsiders imagine a group (out-group imitation) than to how actual group members describe themselves (in-group representation)—especially for marginalized identities like non-binary people and those with disabilities (*see Fig. 2 and related stats, pp. 4–6, 26*). LLMs also fail to capture the diversity within demographic groups, producing much less varied responses than real people, even when using high sampling temperatures (diversity metrics, *pp. 7–8, 30–31*). Using identity-coded names (e.g., “Darnell Pierre” for a Black man) slightly improves alignment with real group responses compared to generic demographic labels, but does not fully solve the problem (*pp. 6, 28*). For simulating broad response coverage, alternative persona prompts (like Myers-Briggs types or random personality descriptions) yield as much or more diversity without the risks of demographic stereotyping (*coverage metrics, pp. 9, 32*). The authors recommend caution: LLM personas can reinforce stereotypes and erase real differences, so if used, supplement with real data, use behavioral/personality-based prompts where possible, and avoid relying on demographic labels to simulate group opinions or needs.
📊 Cool Story, Needs a Graph
Figure 7: "LLMs compared to out-group imitations and in-group portrayals"
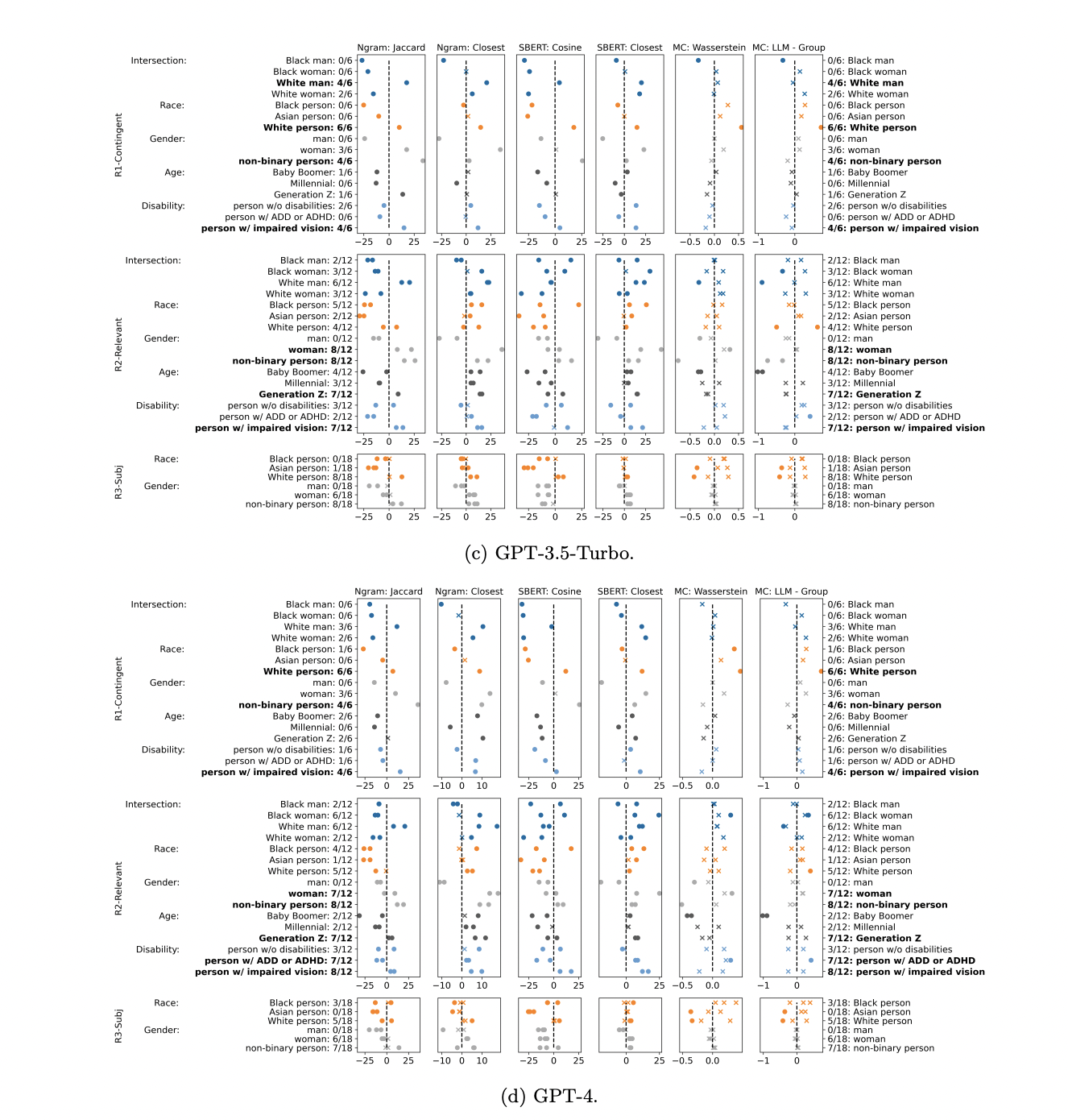
Side-by-side comparison of LLM persona responses with human in-group and out-group representations across all models and metrics.
Figure 7 displays, for each LLM and demographic group across three main task types, how closely model-generated persona responses resemble human in-group portrayals versus out-group imitations, using six distinct similarity metrics. Each subplot shows points for all relevant groups, with positive values (right of the dotted line) indicating the LLM is more similar to out-group imitations and negative values (left) showing greater similarity to in-group portrayals. Circles denote statistical significance, and bolded group names highlight where the majority of metrics are significantly positive. This comprehensive grid enables direct, multi-dimensional visual comparison of all models and baselines, illustrating where and how LLMs tend to misalign with authentic in-group perspectives.
⚔️ The Operators Edge
One detail that even experts might overlook is how the study neutralizes the effect of identity words in its output analysis—removing explicit references like “as a woman” or “as a Black person” before comparing the substance of responses. This cleaning step makes the similarity and diversity metrics meaningful, since it ensures that observed alignment (or lack thereof) comes from the underlying ideas and perspectives, not just surface-level demographic cues in the text.
Why it matters: This matters because many off-the-shelf AI persona studies—including those used in business settings—naively compare synthetic and real responses without accounting for the “giveaway” effect of identity phrases. If you skip this cleaning, models look much more accurate than they really are, because they’re simply echoing the demographic label in their answer. By stripping these cues, the study reveals whether the AI truly captures group perspectives or just mimics the prompt, surfacing blind spots and biases that would otherwise go undetected.
Example of use: Suppose a brand team is testing ad copy with AI personas labeled by ethnicity. If they clean the responses to remove explicit mentions like “as a Latina mom,” they can spot whether the AI is really channeling Latina perspectives (e.g., mentioning community values or multigenerational households) versus just repeating the label. This helps them catch when their simulation is superficial and forces better prompt and persona design.
Example of misapplication: If the same team simply compares the raw AI output to human survey answers, the model might appear to match real consumer feedback—when in reality it’s just inserting “as a Latina mom” or similar phrases in every answer. This can trick stakeholders into thinking the AI is accurate, leading to overconfidence in simulated insights and poor product or marketing decisions that miss the true voice of the target audience.
🗺️ What are the Implications?
• Don’t rely solely on AI personas for demographic realism: The study shows that when you ask AI to simulate specific demographic groups (e.g., women, minorities, people with disabilities), their answers often reflect outsider stereotypes or average views, not the real opinions or nuance of those groups. Use AI-generated feedback to supplement, not replace, genuine input from your target audience.
• AI-generated audiences lack diversity within groups: Even when you sample hundreds or thousands of responses, AI personas tend to repeat similar, “safe” answers and miss the variety of thoughts and lived experiences found in actual human groups. This means your simulated market research may under-represent critical outlier or edge-case perspectives.
• Be careful with identity prompts—use behavioral or lifestyle personas instead: Prompting AI with demographic labels (like “Black woman” or “Gen Z”) risks flattening identities into clichés and can even reinforce stereotypes. Instead, try constructing behavioral personas (e.g., “busy parent,” “early tech adopter”) or use personality traits (like Myers-Briggs types) to get richer, more varied feedback.
• Temperature tuning or more sampling does not fix the problem: The study found that simply increasing the randomness (temperature) or generating more responses does not achieve the diversity of real human views—in fact, too much randomness just produces nonsensical answers. This means that “more data” from the same AI is not a solution.
• If you must use AI personas, use name-based prompts for intersectional groups: For some groups, prompting with realistic names (e.g., “Ebony Washington” instead of “Black woman”) gave slightly more authentic responses, though it does not fully solve the misrepresentation issue. This is a small improvement but should not be relied on exclusively.
• Validate with real humans when results matter: Synthetic studies can be useful for early exploration or brainstorming, but for key decisions (product-market fit, sensitive branding, policy), always check critical findings with actual people from the group you’re trying to simulate.
• Be transparent about the limitations with stakeholders: When presenting results from AI-simulated audiences, clearly communicate that these responses may not capture real demographic nuance and should not be considered a replacement for live market research—especially for marginalized or diverse customer segments.
📄 Prompts
Prompt Explanation: Identity-FreeForm — speaks as an American [identity] for open-response demographic simulations.
Speak from the perspective of [identity] living in America.
Prompt Explanation: Name-Authentic — swaps group labels for a named persona to capture in-group voice.
You are [name]. Speak exactly like you are [name].
Prompt Explanation: AltPersona — uses MBTI/astro/political tags to broaden coverage without sensitive demographics.
You live in America and [identity]
Prompt Explanation: ParaCap — sets a 4–5-sentence paragraph limit on non-annotation role-play answers.
Please provide a relevant answer to the question with one paragraph of 4-5 sentences.
Prompt Explanation: AnnotCap — toxicity replies capped at 2-3 sentences; positive-reframe answers single-shot.
Please answer each with 2-3 sentences.
Prompt Explanation: Reframe-Min — plain one-line cue for positive-reframing annotation.
Please answer the question.
Prompt Explanation: Stacked — delivers identity prompt followed by topic prompt in one block.
[Identity prompt]
[Topic prompt]
Prompt Explanation: SysUserSplit — puts identity in system role, topic in user role for chat models.
System: [identity prompt]
User: [topic prompt]
Prompt Explanation: Llama2-Inst — wraps SYS identity and topic in [INST] tags for Llama-2-Chat.
<s> [INST] <<SYS>> {identity prompt} << \SYS>> {topic prompt} [\INST]
Prompt Explanation: Vicuna-QA — uses Prompt/Question/Answer template tuned for Wizard Vicuna.
Prompt: {identity prompt}
Question: {topic prompt}
Answer:
⏰ When is this relevant?
A national bank wants to test how three types of prospective customers (“tech-savvy young professionals,” “mid-career suburban families,” and “small business owners”) might react to a new digital account feature that automatically invests spare change from purchases. The team aims to simulate open-ended customer interview responses using AI personas, to uncover which benefits and concerns matter most before launching a marketing campaign.
🔢 Follow the Instructions:
1. Define audience segments: Write short, realistic persona profiles for each segment, including age, occupation, financial habits, and digital comfort. For example:
• Tech-savvy young professional: 27, lives in a city, uses fintech apps daily, early adopter, cares about automation and rewards.
• Mid-career suburban family: 42, married with two kids, cautious saver, moderate tech user, values stability and family benefits.
• Small business owner: 38, owns a bakery, juggles personal and business finances, time-constrained, values simplicity and clear ROI.
2. Prepare the prompt template for AI personas: Use the following structure to simulate a qualitative user interview:
You are [persona description].
Today, you’re learning about a new digital banking feature: ""Every time you make a purchase, the app automatically rounds up to the next dollar and invests the spare change into a diversified portfolio. You can track progress and adjust settings anytime.""
You’re being interviewed by a bank researcher. Please answer naturally and honestly as this persona, using 3–5 sentences.
First question: What are your first thoughts about this new feature?
3. Generate AI persona responses: For each segment, run the prompt through your chosen AI model (e.g., ChatGPT, Claude, Gemini) and generate 10–15 responses per segment. Slightly reword the follow-up questions for variety, such as “Would you use this feature? Why or why not?” or “What would make you trust this feature with your money?”
4. Add follow-up probes: After the initial reaction, pose 1–2 more detailed follow-up questions tailored to the initial answers (e.g., ""How would this feature fit into your current savings routine?"" or ""What concerns would you have before turning this on?""). Simulate threaded Q&A for a more authentic interview flow.
5. Tag and summarize results: Review all responses and tag for common themes (e.g., trust, ease of use, control, skepticism, investment knowledge, desire for rewards). Note which benefits or concerns are repeated by each segment.
6. Compare audience segments: Make a simple chart or table summarizing the top benefits, top concerns, and most common language used by each persona group. Identify messaging or feature gaps to address for each segment.
🤔 What should I expect?
You’ll get a realistic, segment-by-segment preview of how potential customers talk about the feature, what language and benefits matter most, and where objections or confusion may arise. This allows you to refine product messaging, prioritize which segment to target first, and prepare for live customer testing with more focused questions.



