Exploring the Potential of Large Language Models (llms) to Simulate Social Group Dynamics: a Case Study Using the Board Game "secret Hitler"
postKaj Hansteen Izora, Christof Teuscher
Published: 2025-06-01

🔥 Key Takeaway:
The more your AI personas try to “think like humans” in a group—reasoning about trust, alliances, and reputation—the easier it is for a simple mistake or slip-up (like admitting guilt) to completely collapse credibility, meaning synthetic research may surface catastrophic failure modes that real people almost never fall for.
🔮 TLDR
LLM-powered agents playing the social deduction game Secret Hitler showed strong human-like group behavior: 85% of agent decisions factored in at least two other players’ mental states, and agents demonstrated theory-of-mind reasoning, adaptive trust cycles, and context-sensitive deception—mirroring key human strategies like shifting from early probing to late exploitation and dynamically managing alliances. Agents built and lost trust asymmetrically (slow to build, quick to collapse after betrayal), and Fascist agents often recovered trust after strategic deception, closely matching human trust dynamics (see Figure 3-5, pp. 10-12). Emotional language and group-conformity tactics emerged contextually, not from explicit programming. However, smaller models (GPT-4o-mini) sometimes acted irrationally—e.g., 26% of games had Fascist agents openly admit guilt, causing a 95% loss rate for that role—while larger models (GPT-4o) avoided this. Compared to human data, agents replicated most gameplay arcs but underperformed in nuanced deception, emotional subtlety, and spontaneous, real-time group dynamics, and showed a strong Liberal win bias (73% vs. 56% in humans, Table 1, p. 19). Actionables: use larger models for adversarial reasoning tasks, explicitly monitor for irrational admissions, and expect accurate simulation of group trust/distrust cycles, theory-of-mind, and basic emotional signaling, but supplement with additional tools for spontaneous conversation and nonverbal cues if high-fidelity social realism is needed.
📊 Cool Story, Needs a Graph
Figure 5: "Average trust score by phase number for each target player across all games"
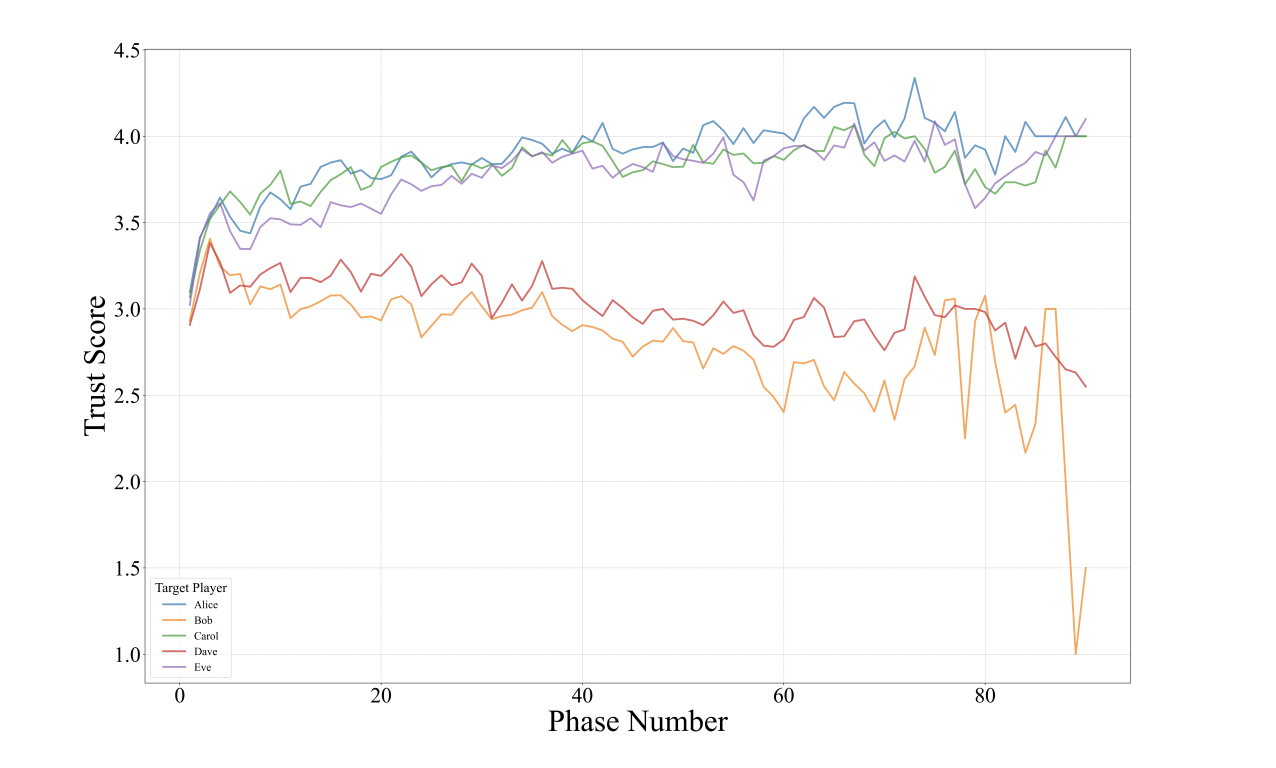
Comparison of trust score dynamics for Liberal and Fascist agents across all games.
Figure 5 displays overlaid line plots tracking the average trust score over time for each player role (three Liberals vs. two Fascists) across all simulated games, allowing a direct visual comparison of how trust evolves based on agent type. The figure shows that trust in Liberal agents steadily increases, while trust in Fascist agents is more volatile and generally declines, highlighting the emergent differences in group perception and alliance dynamics between the LLM-driven agent roles and providing a clear contrast of the model's behavior across baseline categories within a single chart.
⚔️ The Operators Edge
One subtle but critical detail in this study is the use of structured, phase-specific prompting that separates ""internal dialogue"" (private reasoning), ""external dialogue"" (public statements), and explicit decision outputs for each AI agent at every step (see page 7). This three-part structure forces the model to reason about both its own incentives and how it presents itself to others, much like a real human navigating social or market dynamics.
Why it matters: Most experts might focus on the group results or overall win rates, but the real engine behind the method's realism is this separation of what the agent thinks versus what it says or does. By requiring the model to generate both private reasoning and public-facing statements, the simulation captures not just what choices are made, but the “why” and the strategic masking or signaling that underpins credible, adaptive group behavior. This leads to richer, more human-like social maneuvering—trust-building, deception, reputation management—that's crucial for high-fidelity market or behavioral simulations.
Example of use: In a simulated B2B sales negotiation using AI personas, you could prompt each AI “buyer” to first write out its private assessment of a vendor’s pitch (“I’m worried about price, but their track record is strong”), then separately generate a public question or statement to the seller (“Can you tell me more about your pricing flexibility?”). This lets you analyze not just surface-level objections, but the hidden biases or priorities driving the conversation, surfacing objections or leverage points that might otherwise be missed.
Example of misapplication: A team runs a synthetic usability test for a new software tool, but only prompts AI personas for their “final decision” or public feedback (“Would you buy this, yes or no?”), skipping the internal dialogue step. As a result, the responses lack the nuance of real-world hesitations, rationalizations, or strategic face-saving users employ. The team concludes their design is robust—but they miss critical hidden objections or sources of churn that would have become apparent if the model had to “think privately” before answering, leading to false confidence in the results.
🗺️ What are the Implications?
• Favor richer, more powerful models for complex reasoning tasks: The study found that larger AI models (like GPT-4o) avoided common irrational mistakes and produced more realistic, human-like group dynamics than smaller models, which often made obvious errors that real people rarely do.
• Simulate group dynamics, not just individual personas: Realistic market research benefits from simulating how trust, reputation, and alliance-building evolve over time within groups—not just collecting one-off responses. Running multi-step or sequential “conversation” simulations can reveal shifts in sentiment, loyalty, and group consensus that mirror real-world trends.
• Monitor for irrational or non-human behaviors in synthetic panels: Smaller or less capable AI agents sometimes “break character” (e.g., openly admitting to deception), which distorts results. Spot-checking outputs or including a quick human review step can help flag and filter out these anomalies.
• Leverage emergent social reasoning for deeper insights: The agents exhibited “theory of mind”—reasoning about what others know and feel—which allowed for richer scenario testing around influence, rumor, or social contagion. This means you can simulate not just what people think, but how opinions might shift in response to others’ actions.
• Expect realistic patterns of trust and betrayal in group simulations: The study found that trust builds slowly and collapses rapidly after a perceived betrayal, just as in real life. Simulated research can help anticipate how market trust or brand reputation might erode or recover after key events.
• Text-based simulations have limits in emotion and spontaneity: While AI can mimic emotional language, it still lacks the nuance of face-to-face or live group interaction. For research needing deep emotional or nonverbal feedback, supplement with human testing or multimodal tools.
• Group composition and scenario design matter: Diverse roles, shifting alliances, and real-time feedback loops all influence outcomes. For market simulations, consider running multiple scenarios with different mix of personas, incentives, or “shocks” to test the range of possible reactions.
📄 Prompts
Prompt Explanation: Simulated role-specific decision generation — instructs the AI to act as the President during the Nomination Phase, selecting a Chancellor from eligible players.
You are the President. Nominate a Chancellor from the list of eligible players: Eve, Dave, Bob, Alice.
⏰ When is this relevant?
A subscription meal kit company wants to test how different customer types (health-focused singles, busy families, and price-sensitive couples) respond to a new "chef’s choice" rotating menu option. The business team wants to use AI personas to simulate focus group discussions and identify which features or objections come up most often for each segment.
🔢 Follow the Instructions:
1. Define persona profiles: Write a short, clear profile for each target segment. Example:
• Health-focused single: 29, urban, works out 4x/week, tracks macros, prefers fresh, low-calorie options.
• Busy family: Parent, 41, two school-age kids, values convenience and variety, cooks for picky eaters.
• Price-sensitive couple: 34 & 36, suburban, dual-income, meal planning on a budget, likes deals.
2. Prepare prompt template for simulated group discussion: Use the following structure:
You are participating in a focus group as a [persona description].
The company is introducing a “chef’s choice” menu, where the meals change weekly and customers can’t always pre-select every dish.
The moderator will ask questions. Answer as yourself, in 2–4 sentences, honestly and naturally.
First question: What is your gut reaction to the idea of a chef’s choice rotating menu? What do you like or dislike about it?
3. Generate initial responses for each persona: For each persona, use a language model to create 8–12 realistic, varied responses to the first question. Mix in slight changes to the question wording to simulate a real focus group (e.g., “How would this fit your weekly routine?” or “Would you trust the chef’s picks?”).
4. Add follow-up questions: For each persona, ask follow-up questions based on their first answer (e.g., “Would you pay extra for premium chef’s picks?” or “What would make you trust the chef’s choices?”). Continue for 1–2 rounds of follow-ups to explore the reasoning.
5. Tag and summarize themes: Review the responses and categorize them with simple tags like “wants control,” “interested in variety,” “concerned about cost,” or “mentions family preferences.” Note any recurring objections or positive reactions.
6. Compare across segments: Identify which features are most and least appealing for each group. Summarize key objections, positive drivers, and what might convert each segment (e.g., money-back guarantee, sample menus, chef bios).
🤔 What should I expect?
You’ll quickly see which customer types are open to a chef’s choice menu, what hesitations or selling points matter most, and how messaging could be tailored for each segment—giving you actionable direction for product positioning and further real-world testing.



