Fine-grained User Behavior Simulation on Social Media Based on Role-Playing Large Language Models
postKun Li, Chenwei Dai, Wei Zhou, Songlin Hu
Published: 2024-12-04

🔥 Key Takeaway:
Adding more user history to AI personas actually makes them worse at simulating real people—performance peaks with just the 30 most recent behaviors, and giving the AI more data beyond that introduces so much noise that it loses focus and accuracy. In synthetic research, less (but more relevant) history really is more.
🔮 TLDR
This paper introduces FineRob, a new 78,600-record dataset built from real user histories on Twitter, Reddit, and Zhihu, designed to rigorously test whether large language models (LLMs) can accurately simulate fine-grained social media behaviors by decomposing each action into object (who/what the action targets), type (the nature of the action), and content (what is said/done). The authors benchmark nine LLMs—including GPT-4o and top open-source models—showing that even leading open models lag commercial ones like GPT-4o by about 15% in F1 accuracy, and that larger models are not always better (smaller models sometimes outperform). They identify two reasoning styles: (1) “role-stereotype” (predicts actions from user profile) and (2) “observation and memory” (compares current choices to past behaviors), finding the latter much more accurate. Their OM-CoT fine-tuning method, which explicitly structures LLM reasoning around observation of options and recall of user history (using special prompt tokens), boosts simulation F1 by 4.5–9.8% on key tasks. Crucially, ablation studies show that including around 30 recent user behaviors in prompts is optimal—more history adds noise and hurts accuracy—while user profiles alone have limited value. Takeaways: to improve LLM audience simulation, use real behavioral data, structure prompts to emphasize recent user history and option analysis (not just persona traits), and consider OM-CoT-style fine-tuning to guide models toward evidence-based, memory-driven reasoning.
📊 Cool Story, Needs a Graph
Table 4: "F1-scores of OM-COT-FT and other baselines"
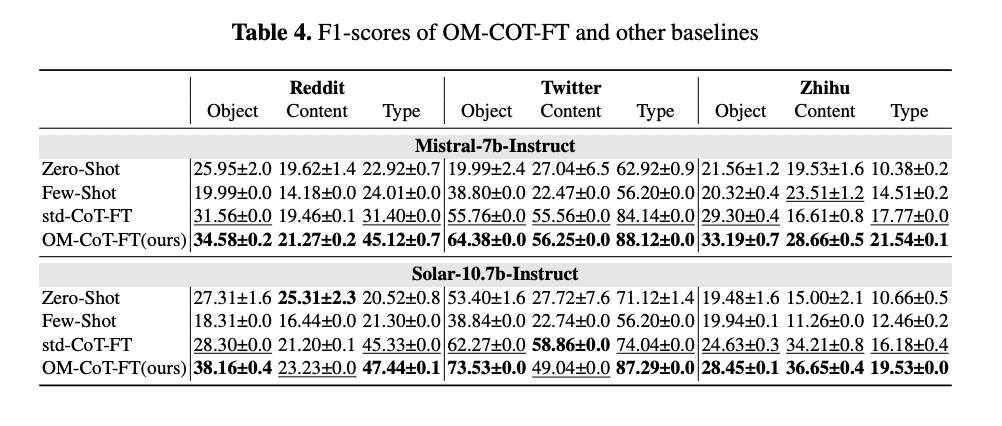
OM-CoT fine-tuning outperforms all baseline methods for simulating fine-grained user behaviors across three platforms. Table 4 presents a direct side-by-side comparison of four methods—Zero-Shot, Few-Shot, standard Chain-of-Thought fine-tune, and OM-CoT fine-tune—applied to two open LLMs (Mistral-7b-Instruct and Solar-10.7b-Instruct) across three platforms (Reddit, Twitter, Zhihu) and three behavior elements (Object, Content, Type). The results, reported as F1-scores, demonstrate that OM-CoT-FT consistently achieves the highest scores in nearly all tasks, outperforming both the zero-shot and few-shot baselines as well as standard CoT fine-tuning. This table clearly highlights the effectiveness of the OM-CoT approach in improving the accuracy of simulated user behavior, making it a compelling reference for benchmarking simulation methods.
⚔️ The Operators Edge
The real reason the OM-CoT method works so well isn’t just because it asks the AI to recall user history, but because it *explicitly separates and labels two kinds of reasoning—current option analysis (<ANA>) and memory of past actions (<MEM>)*—within the prompt, training the model to process both streams in parallel before making a prediction. This structure forces the AI to systematically weigh both immediate context and historical behavior, rather than defaulting to stereotypes or overfitting to one source of information.
Why it matters: Most experts might focus on the size or realism of the prompt, or on the value of adding more user history. But here, the key is that adding structured, labeled reasoning steps *teaches* the AI how to balance competing influences, making simulations more robust and human-like. It’s the explicit prompt architecture—not just the data—that drives accuracy.
Example of use: In a real-world product test, a team evaluating how AI shoppers would react to a redesigned checkout flow could prompt the AI with: <ANA>“Consider the new checkout features and compare them to your current experience...”</ANA> <MEM>“Recall your last 5 checkout experiences and what you liked or disliked...”</MEM> “Based on both, what would you do?” This structure ensures the AI persona doesn’t just parrot the new feature’s benefits or blindly follow past habits, but instead surfaces realistic tradeoffs and hesitations.
Example of misapplication: If the same team just dumps a long list of user actions and new features into the prompt without any structure or labeling, the AI might latch onto the most recent item, ignore history, or default to generic marketing answers. The result is less nuanced feedback, with lower predictive value for how real users might behave—missing the competitive edge that comes from structured dual-path reasoning.
🗺️ What are the Implications?
• Including recent user history in prompts is crucial: AI personas give more realistic and accurate responses when their last 30 actions or posts are summarized and included, rather than relying just on static profile traits or demographic data.
• Prompt structure matters more than model size: Carefully designed prompts that guide the AI to reason based on behavioral evidence and options outperform simply using a bigger or more expensive language model.
• Fine-tuning with realistic behavioral data improves results: Training or adjusting AI personas using real user activity (not just synthetic or generic data) significantly boosts their ability to mimic real-world patterns and decisions.
• "Observation and memory"-based reasoning is best: AIs are most accurate when instructed to explicitly analyze both current options and past behaviors before making a decision, rather than just acting “in character.”
• More history isn’t always better: Adding too much user history beyond 30 actions actually reduces accuracy by introducing noise—focus on the most recent and relevant behaviors.
• Simple prompt tokens can help: Teaching the AI to separate “current analysis” from “memory of past actions” (as done with special tokens in the study) further raises realism and accuracy in simulated responses.
• You don’t need to pay for the most advanced model: Well-structured prompts and tailored fine-tuning closed much of the performance gap between open-source models and expensive commercial AIs.
• Avoid using AI personas for brief or contextless responses: Even after fine-tuning, AIs struggle to capture nuance in very short or generic replies—use them for richer, context-heavy questions.
📄 Prompts
Prompt Explanation:
Prompt used in the OM-CoT fine-tuned example for Reddit behavior simulation.
```
<ANA>
The options presented reflect varying perspectives on the accessibility and limitations
of financial services, particularly regarding ATM withdrawals and online transactions.
Option (C) specifically mentions the inability to withdraw money using a debit card, which
aligns with the user’s concern about the limitations of their financial account. Option (D)
discusses the limitations set by financial institutions regarding ATM withdrawals and
daily debt purchases, which is relevant to the user’s inquiry about their financial situation.
</ANA>
<MEM>
- The user commented on the high fees associated with withdrawing money from an ATM,
indicating a concern about the costs of accessing their funds.
- The user also expressed frustration over the limitations of their financial account, partic-
ularly regarding the inability to withdraw money without incurring fees.
- The user has engaged in discussions about the challenges of managing finances in
Australia, which may relate to the limitations mentioned in option (D) regarding financial
institution policies.
</MEM>
Therefore, the answer is (C).
```
⏰ When is this relevant?
A food delivery startup is deciding whether to add a new “healthy meals” filter to its app and wants to know how different customer groups might react to the change, including their likely behaviors, concerns, and potential usage patterns. Rather than running time-consuming user interviews, the team uses AI personas to simulate real customer responses.
🔢 Follow the Instructions:
1. Define 3–5 realistic customer personas using business-relevant attributes. For example:
• Busy urban professional: 32, works long hours, values convenience, sometimes orders healthy food but mostly prioritizes speed.
• Health-focused parent: 40, two kids, prefers organic and balanced meals, uses the app for family dinners.
• Student on a budget: 21, lives in a shared apartment, tracks spending, open to healthy options if affordable.
2. Prepare a core product prompt explaining the new feature in clear business language. Example:
“Our app is adding a new ‘healthy meals’ filter that lets you quickly find menu items with lower calories, more vegetables, and balanced nutrition. You can use this filter to browse or search for healthier options at participating restaurants.”
3. Create a prompt template for each persona. Use this structure:
You are a [persona description]. Here is a new feature in your food delivery app: “[Insert product prompt]”.
Please answer the following as if you just learned about this update:
1) What is your honest first reaction?
2) Would you use this filter, and if so, how? If not, why not?
3) What concerns or suggestions do you have to make this feature better?
Answer in 3–5 sentences, speaking naturally in character.
4. Run the simulation: For each persona, input the prompt into your AI model (e.g., GPT-4, Claude, etc). For richer data, generate at least 5–10 independent responses per persona (vary the wording slightly or change the order of questions to avoid repetition).
5. Optional follow-up: Based on initial answers, ask one or two more targeted questions. For example, “What would make you recommend this feature to a friend?” or “How might this change how often you use the app?”
6. Analyze the responses: Tag answers for recurring themes such as “interest in health,” “ease of use,” “price sensitivity,” “skepticism,” or “potential increased usage.” Summarize the most common reactions and objections for each persona.
7. Compare across personas: Identify patterns—e.g., parents care about ingredient transparency, students want price filters, busy professionals want it integrated with quick reorder options.
8. Report findings simply: Prepare a slide or summary showing typical reactions, key feature requests, and any red flags for each group. Use direct persona quotes as examples.
🤔 What should I expect?
You will have a clear, business-focused summary of how different customer segments are likely to respond to the healthy meals filter, what would drive or block adoption, and which specific improvements could increase feature success—all generated in hours, not weeks, and ready to inform product, marketing, and design decisions.



