Language Models Trained on Media Diets Can Predict Public Opinion
postEric Chu, Jacob Andreas, Stephen Ansolabehere, Deb Roy
Published: 2023-03-28

🔥 Key Takeaway:
By fine-tuning a language model on the actual articles/radio transcripts/TV scripts your target audience consumes, you can recover answer distributions that closely match real-world survey data—particularly for people who follow those media sources closely.
🔮 TLDR
This paper shows that language models (like BERT) fine-tuned on specific “media diets” (collections of news, TV, or radio content consumed by different subpopulations) can predict how those groups will answer public opinion surveys, with correlations up to r = 0.46 for COVID-19 attitudes (see page 5) and r = 0.38 for questions about national economic conditions (page 7). The models are most accurate for survey questions on topics heavily shaped by media (e.g., national issues or future expectations) and less accurate for personal or retrospective questions. The method works across online, TV, and radio news, is robust to question phrasing, and remains predictive even after controlling for demographics—media exposure is an especially strong predictor when combined with the model’s scores. Technical choices that improved model accuracy included using a strong pretrained model (BERT), fine-tuning it on recent media content, and grouping synonyms when scoring responses. The approach can supplement or forecast survey results at higher frequency and lower cost, but is only as accurate as the characterization of the group’s actual media exposure. The paper recommends: (1) fine-tune language models on realistic, time-matched media diets for each target audience, (2) combine model outputs with media exposure metrics, (3) use synonym-aggregation when probing models, and (4) focus on questions where public opinion is known to be media-sensitive.
📊 Cool Story, Needs a Graph
Figure 2: "Attitudes towards COVID-19: correlations and regressions on media diet scores and survey response proportions."
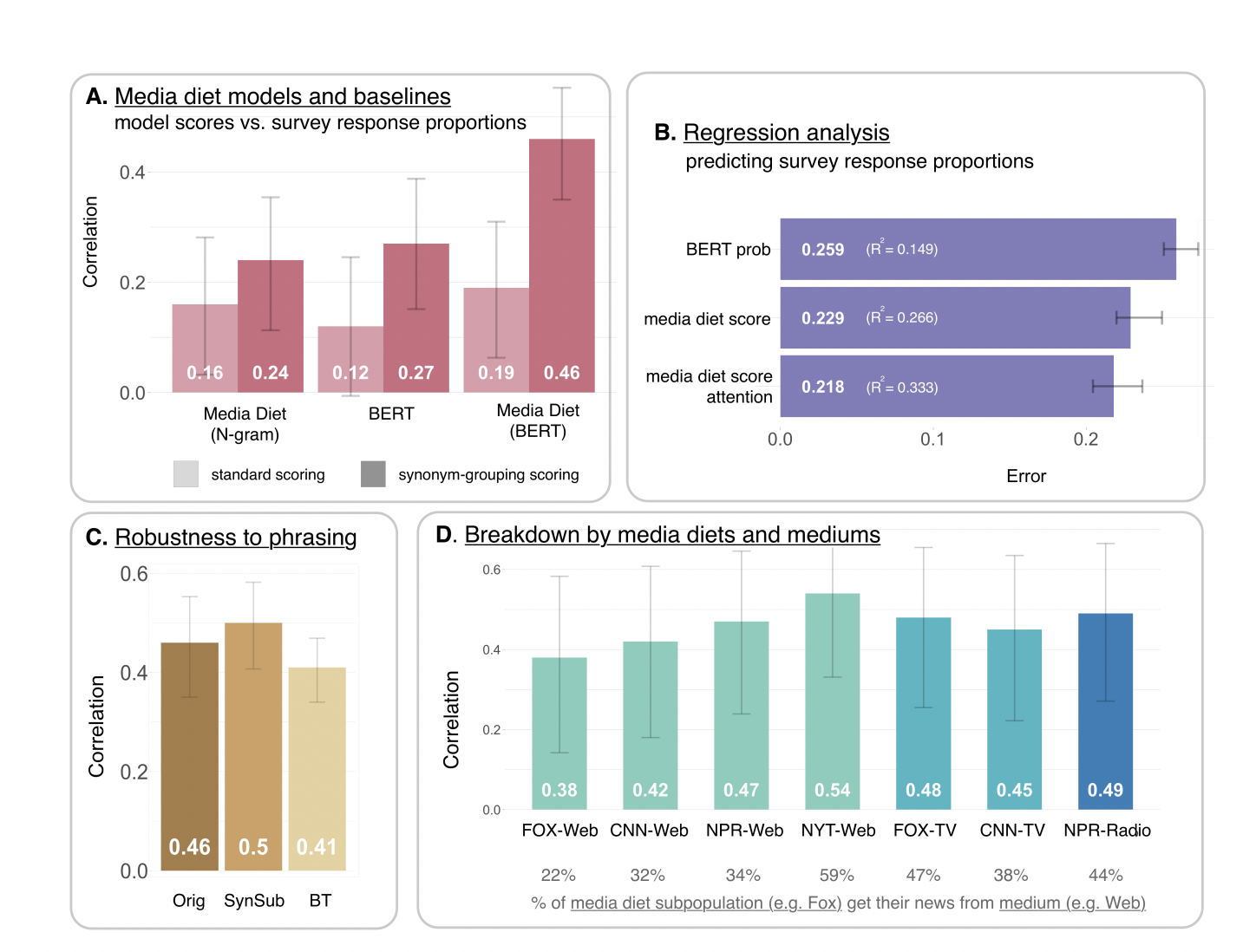
Side-by-side comparison of media diet modeling methods and baselines for predicting COVID-19 survey responses.
Figure 2 presents a comprehensive visual comparison of the proposed media diet modeling method (BERT fine-tuned on news), a simple N-gram baseline, and an unadapted BERT baseline. Panel A shows side-by-side bar charts of correlation scores for each method, highlighting the impact of synonym grouping. Panel B presents regression error and R² values for predicting survey response proportions using the three approaches (baseline BERT, media diet score, and media diet score plus attention to news). Panels C and D further explore robustness to prompt phrasing and breakdowns by media sources. This figure clearly demonstrates the superior predictive power of the media diet BERT model over both baselines and shows how added modeling choices (like synonym grouping and including attention covariates) further improve performance.
⚔️ The Operators Edge
A subtle but crucial detail in this study is the use of synonym-grouping when scoring model responses—meaning, instead of just checking if the AI picks a single “correct” word in response to a prompt, the researchers aggregate probabilities across a set of synonyms that all reasonably answer the same question (see Figure 2A and methods, pages 3–6). This addresses what’s known as “surface form competition,” where language models might spread probability mass across similar words, underestimating the true likelihood that the model “knows” the right answer.
Why it matters: This approach is important because it makes the AI’s simulated responses robust to how survey questions are worded and to the natural variation in human language. Without synonym grouping, you’d miss a lot of true signal—models might look inaccurate simply because they’re picking “required” instead of “necessary.” By capturing the full range of plausible answers, you get a much truer measure of whether your AI audience is aligned with real people—and this is a key reason the method outperforms simpler or naive scoring approaches.
Example of use: Suppose a brand manager is testing synthetic customer reactions to a new product description. Instead of measuring only whether the AI personas label it “exciting,” she aggregates across related terms like “innovative,” “interesting,” or “intriguing.” This allows her to see the total positive response, regardless of exact wording, giving a more stable and realistic read on likely customer sentiment—especially useful if the market uses varied language.
Example of misapplication: If the manager only scores for a single word—say, “exciting”—any AI persona that picks “innovative” or “game-changing” would be counted as a miss, leading to artificially low or misleading results. In practice, this could cause her to reject good messaging or underestimate product appeal just because the simulated audience didn’t use the exact terms she expected, not because they actually responded negatively.
🗺️ What are the Implications?
• Ground your simulated audience in recent, real media exposure: Market research simulations are much more accurate when virtual personas are built around the actual news, TV, and radio content recently consumed by your target audience, rather than generic or outdated information.
• Use advanced language models fine-tuned on audience-specific media: Off-the-shelf AI models don’t capture real group differences well; the study found that fine-tuning models (like BERT) on real media diets for each group increased prediction accuracy from r=0.19 to r=0.46 (see Figure 2A, page 5).
• Account for how closely people pay attention to media: The accuracy of simulated audience responses improves when you factor in how much attention the real-world group pays to the news—adding this variable to the model made predictions even more closely match survey results.
• Write survey and study prompts using synonyms and natural wording: The way questions are phrased affects AI accuracy, but using synonym grouping and multiple phrasings makes simulated results more robust and less sensitive to wording quirks (see Figure 2C, page 5).
• Don’t rely on demographic targeting alone: Demographic variables like age, gender, or education were much less predictive than recent media exposure and attention, so focus on understanding what your audience is actually seeing and reading.
• Test the approach first on issues where opinions are known to shift with the news: The method works best for questions about national trends, public health, or the future—areas where media coverage strongly shapes perceptions—rather than purely personal or retrospective topics.
• Consider supplementing traditional research with fast, low-cost simulations: Because this approach can track opinion shifts daily or weekly at much lower cost than repeated human surveys, it’s a practical way to spot early trends or test messaging before launching expensive studies.
📄 Prompts
Prompt Explanation: The AI model was probed using fill-in-the-blank prompts derived from real survey questions, with target words representing survey response options, to estimate the likelihood of each answer as a proxy for subpopulation opinions.
Requiring most businesses other than grocery stores and pharmacies to close is [BLANK] in order to address the coronavirus outbreak
⏰ When is this relevant?
A consumer bank wants to test how customers from three different segments (young adults new to credit, middle-aged homeowners, and retirees) would react to a new digital budgeting tool and its messaging. The team wants to simulate open-ended survey responses and see which features or messages most influence interest and trust in the product.
🔢 Follow the Instructions:
1. Define customer segments: Create three AI persona profiles. For each, describe age range, financial goals, digital habits, and typical concerns.
• Young adults new to credit: 23, first job, uses mobile banking, wants to build credit and avoid debt.
• Middle-aged homeowner: 45, married, owns a home, manages family expenses, uses online banking but prefers simple tools.
• Retiree: 68, on fixed income, cautious with new technology, values stability and avoiding scams.
2. Prepare prompt template for persona simulation: Use this structure for each simulated interview:
You are a [persona description].
Here is the new product being tested: ""A digital budgeting tool that links to your bank accounts, categorizes spending, offers monthly savings tips, and provides credit score updates, all in a simple mobile app.""
You are answering an open-ended survey for your bank.
Respond as yourself in 3–5 sentences.
First question: What is your first reaction to this budgeting tool? What would make you want to try it or not?
3. Run the prompt for each persona: For each segment, generate 10–15 AI responses using the prompt above. Slightly vary the question phrasing for diversity (e.g., ""What would you find most helpful or confusing about this tool?"" or ""How does this compare to how you currently manage your budget?"").
4. Add follow-up prompts: For each initial response, ask a relevant follow-up, such as ""What concerns would you have about security or privacy?"" or ""Would you use this regularly, or only for occasional check-ins? Why?""
5. Tag and summarize key themes: After collecting responses, label them with qualitative tags like ""mentions privacy,"" ""positive about savings tips,"" ""skeptical of technology,"" or ""asks about family budgeting."" Group responses by segment to see common themes.
6. Compare segments and messaging: Summarize which features and messages were most appealing or raised concerns in each group. Identify patterns (e.g., retirees care about simplicity and security; young adults want help with credit-building; homeowners focus on family or bill management).
🤔 What should I expect?
You'll get a clear view of which customer segments are most receptive to the new budgeting tool, what features or messages drive trust or hesitation, and practical guidance for prioritizing marketing angles and product design before running expensive in-person studies.



