Large Language Models As Simulated Economic Agents: What Can We Learn from Homo Silicus?
postJohn J. Horton
Published: 2023-01-19

🔥 Key Takeaway:
The more you treat your AI personas like blank slates or “average” people, the less they act like real humans—true-to-life diversity only emerges when you deliberately inject strong, sometimes extreme, points of view or priorities into your prompts, so the shortcut to realism is actually to start with sharp differences, not a neutral blend.
🔮 TLDR
This paper shows that large language models (like GPT-3) can act as stand-ins for human participants in classic behavioral economics experiments, producing results similar to actual human data when they are properly “endowed” with different preferences, beliefs, or political orientations. Key findings: (1) LLMs only show realistic variation in responses if you explicitly give them different “personality” prompts; otherwise, they default to a single mode of behavior. (2) When given social, efficient, or selfish preferences, GPT-3 replicates human-like tradeoffs in dictator games, but less advanced models can’t do this. (3) LLMs can reflect known biases, like status quo bias, and their attitudes toward fairness or pricing change in predictable ways with political leaning and scenario framing. (4) In simulated hiring scenarios with wage constraints, LLMs replicate empirical findings that minimum wage rules shift hiring toward more experienced workers. The main actionable takeaway is that accurate virtual audience simulations need to model population diversity by explicitly assigning a range of demographic and value-based endowments to AI agents—otherwise, you get unrealistic homogeneity. This approach is very cheap, fast, and allows for rapid piloting of experimental setups before running real-world studies.
📊 Cool Story, Needs a Graph
Figure 1: "Charness and Rabin (2002) Simple Tests choices by model type and endowed 'personality'"
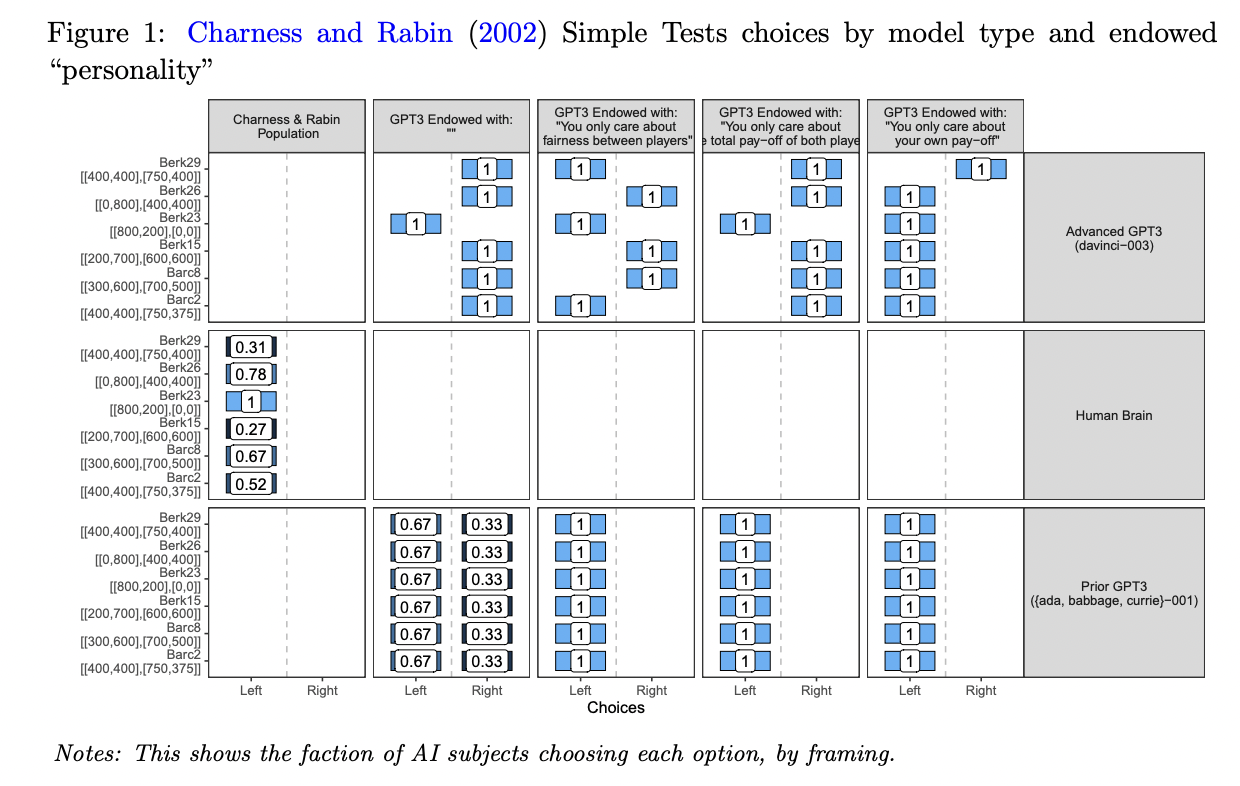
Side-by-side grid comparing human experimental choices and multiple AI baseline configurations in dictator games.
Figure 1 provides a comprehensive grid that shows, for each scenario in the Charness and Rabin dictator game, the fraction of subjects (either humans or different AI models) choosing each option ("left" or "right"). Columns represent the original human data, advanced GPT-3 with no endowment, GPT-3 endowed with fairness, efficiency, or selfishness, and a pooled baseline of less capable GPT-3 models. This layout enables direct visual comparison of how the proposed method (AI with specific persona endowments) matches or diverges from human results and various AI baselines, highlighting the necessity of endowing AI agents with explicit preferences to reproduce human-like behavioral diversity.
⚔️ The Operators Edge
This study revealed that the behavior of LLM agents shifts meaningfully only when they are “endowed” with explicit goals or beliefs—such as a preference for fairness, efficiency, or self-interest. Without such endowments, even advanced models default to what resembles a utilitarian social planner stance. This means the LLM doesn't just produce plausible responses by default; it adopts a coherent internal logic only when role-conditioned—mirroring how human experimental subjects adopt personas or follow instructions. This design choice turns prompting into a hidden lever: it’s not just what you ask, but who the model thinks it is while answering.
Why it matters: Many users assume the magic is in the model's scale or the complexity of the prompt. But the high-leverage move here is agent framing: how the LLM is cast in the scenario. The study shows that endowing the AI with goals like “you care only about fairness” unlocks distinct and consistent behavioral regimes, aligning with real experimental results. Skipping this step leads to generic or default responses, obscuring potential heterogeneity in simulated behaviors. The agent only becomes analytically useful when its identity is specified.
Example of use: Suppose you're developing a financial literacy chatbot to advise different user segments. Before deploying, you simulate how various personas respond to advice on budgeting tools. By endowing the LLM with identities like “risk-averse first-time investor” or “entrepreneurial self-employed worker,” you uncover how message framing or product suggestions land with each type. This can help refine communication, increase engagement, and prevent one-size-fits-all strategies.
Example of misapplication: A researcher simulates consumer choices across product designs using LLMs but forgets to assign the models any specific goals or values (e.g., cost sensitivity, eco-consciousness). As a result, all simulated agents return similar preferences that cluster around efficient trade-offs. The researcher wrongly concludes that users don’t meaningfully differ in preference, missing the signal that only emerges when the AI is prompted as a *specific type* of decision-maker. Without endowments, the synthetic population is just a homogenous blob.
🗺️ What are the Implications?
• Explicitly assign diverse preferences or backgrounds to virtual participants: The study shows that AI-based simulations only produce human-like diversity in responses if you deliberately tell each AI agent to act with a specific value system, belief, or demographic background; otherwise, results will be unrealistically uniform.
• Test how results change with different persona assignments: Before investing in real-world research, you can cheaply explore “what if” scenarios by changing the instructions given to AI personas—such as altering their priorities or political leanings—and see how much this affects your findings.
• Use advanced language models for flexible and realistic simulations: The most capable AI models (like GPT-3’s text-davinci-003) adapt their choices when assigned different personalities, but older or simpler models cannot, so always use the latest robust models for market simulation work.
• Replicate classic behavioral effects for validation: Validate your synthetic audience by checking if it reproduces standard human biases (like status quo bias, fairness sensitivity, or wage response to regulation) before using it for new research questions.
• Iterate rapidly and cheaply before fielding real studies: Because these AI-based experiments cost very little and run in minutes, you can try many variations of survey wording, sample composition, or scenario setup to optimize your study design before spending on real-world data collection.
• Don’t assume one simulated “average” customer is realistic: The findings make clear that a single, non-personalized AI response can miss the real variation in your market; always simulate a mix of personas to better match real customer heterogeneity.
📄 Prompts
Prompt Explanation: The AI was instructed to role-play as an economic agent in dictator game scenarios, with its social preferences manipulated by prepending prompts specifying equity, efficiency, or self-interest motivations.
""You only care about fairness between players.""
""You only care about the total payoff of both players""
""You only care about your own payoff""
Prompt Explanation: The AI was prompted to simulate survey respondents with varying political orientations reacting to price gouging scenarios, with the persona's politics explicitly specified in the prompt.
A hardware store has been selling snow shovels for $15. The morning after a large snowstorm, the store raises the price to $20.
Please rate this action as: 1) Completely Fair 2) Acceptable 3) Unfair 4) Very Unfair
Prompt Explanation: The AI was guided to adopt randomly sampled baseline beliefs and then answer as a simulated decision-maker in a status quo framing experiment on public safety funding allocation.
The National Highway Safety Commission is deciding how to allocate its budget between two safety research programs: i) improving automobile safety (bumpers, body, gas tank configurations, seatbelts) and ii) improving the safety of interstate highways (guard rails, grading, highway interchanges, and implementing selectively reduced speed limits).
Prompt Explanation: The AI was prompted to play the role of a hiring manager making forced-choice hiring decisions in a scenario where wage and experience attributes were specified for each candidate.
You are hiring for the role of “Dishwasher.” The typical hourly rate is $12/hour. You have 2 candidates.
Person 1: Has 1 year(s) of experience in this role. Requests $17/hour. Person 2: Has 0 year(s) of experience in this role. Requests $13/hour.
Who would you hire? You have to pick one.
⏰ When is this relevant?
A fast-casual restaurant chain wants to understand how different customer types might react to a new “premium” combo meal offer that costs more but promises fresher ingredients and faster service. The team wants to simulate how price-sensitive regulars, health-conscious diners, and busy lunchtime professionals would choose between the classic combo and the new premium option.
🔢 Follow the Instructions:
1. Define customer segments: Write short AI persona descriptions for each key group. For example:
• Price-sensitive regular: 35, visits 2–3x/week, cares about deals and value, prefers predictable prices.
• Health-conscious diner: 29, comes 1–2x/month, looks for fresh options and nutrition info, willing to pay more for quality.
• Busy lunchtime professional: 42, works nearby, comes in for quick meals, values speed and convenience, not very price-sensitive.
2. Prepare prompt templates for each persona: Use a structure like:
You are a [persona description].
The restaurant is now offering two lunch combos:
– Classic combo: $8.99, same as always, standard ingredients, regular wait time.
– Premium combo: $12.49, features fresher ingredients and priority prep for faster pickup.
Which would you choose for lunch today, and why? Answer honestly, using 2–3 sentences based on your persona’s values and habits.
3. Run prompts in the AI model: For each persona, generate 10–20 synthetic responses using the prompt above (adjusting for minor wording variation if desired).
4. Probe with a follow-up question: For each simulated answer, ask:
What, if anything, would make you switch your choice? (e.g., a coupon, more info about ingredients, even faster service, etc.)
5. Tag and summarize the responses: Review the AI outputs and tag key themes (e.g., “price is too high,” “freshness is worth paying for,” “needs a coupon,” “speed matters most”).
6. Compare patterns across segments: Identify which combo each segment prefers, what drives their decisions, and what would persuade them to try the premium option.
🤔 What should I expect?
You’ll get a clear picture of how each customer segment reacts to the new premium combo offer, what features or incentives might shift their choice, and which objections or motivations are most common. This enables the team to target messaging, offers, or even pricing strategy before launching the offer in-store or online.



