Large Language Models Empowered Agent-based Modeling and Simulation: a Survey and Perspectives
postChen Gao, Xiaochong Lan, Nian Li, Yuan Yuan, Jingtao Ding, Zhilun Zhou, Fengli Xu, Yong Li
Published: 2023-12-19

🔥 Key Takeaway:
Give each LLM-driven agent its own evolving memory, a scheduled “reflection” step, and a distinct set of bounded-rational goals; that mix of memory + reflection + heterogeneous preferences reliably produces the messy, adaptive behaviour you see in real customers—while still enforcing internal coherence instead of hard-coding contradictions.
🔮 TLDR
This survey reviews how large language models (LLMs) are being used to make agent-based simulations more realistic, flexible, and capable of modeling complex human and market behaviors. It finds that LLM-powered agents can better replicate human traits like autonomy, social interaction, adaptivity, and decision-making than traditional rule-based or machine learning agents, and are able to simulate individual or group behaviors in social, economic, cyber, and physical domains. The paper highlights that LLM agents can be customized with prompts or fine-tuning to match specific personas, roles, or preferences, and that memory and reflection modules help them generate more coherent, human-like responses over time. Key challenges are making sure agents align with real human knowledge and values, scaling up simulations to thousands of agents efficiently, and evaluating the realism of simulated behaviors against real-world data at both individual and population levels (using micro- and macro-level validation). It recommends using prompt engineering, in-context learning, and memory/reflection architectures to improve agent realism, and stresses the need for benchmarking, open platforms, and careful monitoring of bias, ethics, and robustness. The paper lists dozens of recent projects and benchmarks that show LLM agents can replicate market dynamics, social phenomena, and economic decision-making patterns similar to real humans, but warns that computational cost and ethical risks remain open issues. Actionable takeaways: use prompt-based persona conditioning and memory modules for diverse, adaptive agents; always validate outputs with human or real-world data; plan for scalability and ethics from the start.
📊 Cool Story, Needs a Graph
Table 1: "A list of representative works of agent-based modeling and simulation with large language models"
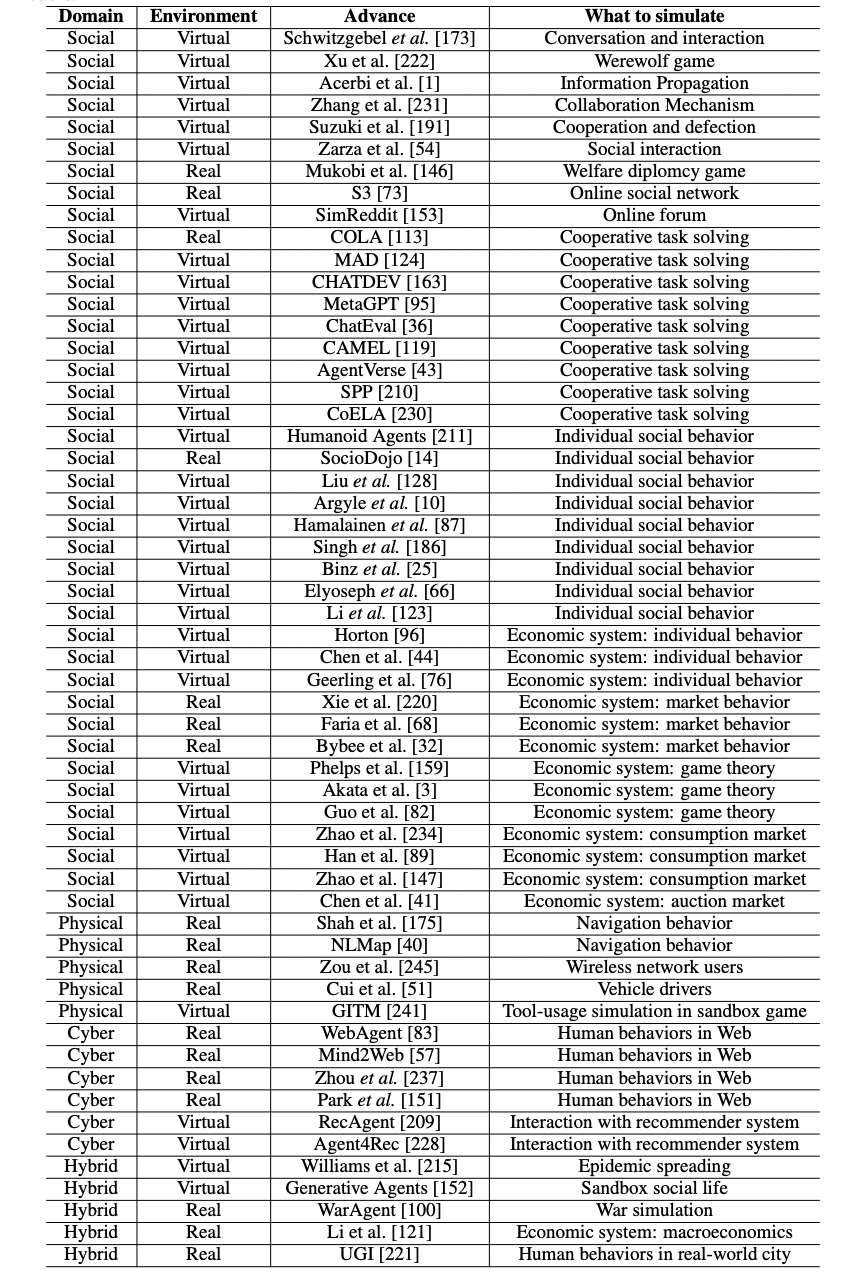
Representative LLM-based agent simulation methods and applications compared across domains.
Table 1, found on page 14, presents a matrix-style overview that contrasts dozens of recent and baseline methods for agent-based modeling and simulation using large language models. It organizes each approach by domain (social, physical, cyber, hybrid), simulation environment (real or virtual), the specific research advance or method, and the corresponding simulation task. This side-by-side format enables direct comparison of the breadth and variety of LLM-based methods with traditional approaches across all major simulation domains, making it easy to see which methods and environments are addressed by each technique and where LLM-empowered models are being used as baselines or improvements.
⚔️ The Operators Edge
A detail most experts might overlook is the importance of equipping AI personas with both memory and reflection modules—allowing them to not just recall past interactions, but to actively critique and update their own responses over time. This feature, discussed as “reflection” and “memory” in the study (see Section 4.3.2 and 4.3.3; also exemplified by the Generative Agents and Reflexion works), turns out to be a hidden lever for producing more realistic, adaptive, and human-like synthetic participants.
Why it matters: Many believe that the power of LLM-based simulation comes from sheer scale or prompt diversity, but it’s the ability for synthetic agents to learn from their own simulated experience—adjusting behaviors, revisiting assumptions, and explaining their reasoning—that makes their outputs robust and life-like, especially in longitudinal or multi-step business scenarios. This isn’t just a technical flourish; it’s essential for mirroring the way real customers update their opinions, preferences, or routines over time.
Example of use: In a digital product test, suppose you want to see how users’ willingness to try a new checkout feature changes after repeated exposures (e.g., after a successful or failed attempt, or after seeing a coupon). By building AI personas with memory and reflection, you can simulate not just one-off reactions but evolving behaviors—like growing trust after a good experience, or increasing skepticism after a failure. The AI can “remember” its last session, reflect on what went well or poorly, and adapt its future answers, mirroring real customer learning curves or resistance to change.
Example of misapplication: A team runs a synthetic focus group for a new product but resets the AI agent context between questions, so each response is independent and has no memory of prior opinions or outcomes. As a result, the simulation only captures static, one-shot reactions—missing the churn, habit-formation, or loyalty effects that actually drive business outcomes over time. They might falsely conclude that a feature is universally liked or disliked, overlooking how real customers often “warm up” or “cool off” based on their ongoing experience, which only memory- and reflection-enabled AI personas can reproduce.
🗺️ What are the Implications?
• Simulate diverse personas with real-world data, not just random traits: Simulations that mirror actual customer segments and behaviors—using real demographic or behavioral data—deliver more reliable, market-relevant insights than generic or randomly generated audiences.
• Invest in prompt design and scenario realism: The way you ""ask"" questions and set up situations for virtual respondents has a major impact on how lifelike and actionable the responses are. Well-crafted prompts that include relevant context produce more accurate feedback.
• Use memory and reflection modules in your simulations: AI personas that can remember past interactions and reflect on outcomes over time behave more like real people, leading to better predictions of long-term trends, repeat engagement, or customer journey shifts.
• Scale up your virtual audience for group dynamics: Many social and market effects—like trend adoption, word-of-mouth spread, or polarization—only appear when you simulate larger groups (hundreds or thousands), so running bigger virtual studies can reveal insights missed by small samples.
• Benchmark against real-world or past data when possible: Always compare your simulation outputs to actual customer responses or known market patterns to check if your virtual audience is realistic; this helps catch errors and build business confidence in the results.
• Be alert to ethical risks and bias in simulated results: AI personas can reflect or even amplify existing biases present in their training data. Regularly review simulations for unintended stereotypes or unfair outcomes, especially if your study informs product or policy decisions.
• Custom scenarios can test new business ideas at lower risk: You can quickly prototype different customer segments, competitive moves, or market shocks in a virtual environment before spending on real-world pilots, helping to de-risk innovation investments.
• Don’t over-rely on the latest or biggest model: The setup and realism of your simulated experiment matter more to output quality than using the absolute newest AI model, so focus budgets on scenario design and validation rather than just upgrading the tech.
📄 Prompts
Prompt Explanation: The AI was instructed to simulate agents with distinct personalities by customizing prompts, enabling them to act competitively, altruistically, or self-interestedly in repeated game scenarios to observe cooperation levels.
Phelps et al. [159] found that incorporating individual preferences into prompts can influence the level of cooperation of LLMs. Specifically, they construct LLM agents with different personalities like competitive, altruistic, self-interested, etc., via prompts. Then, they let the agents play the repeated prisoner’s dilemma game with bots with fixed strategies (e.g. always cooperate, always defect, or tit-for-tat) and analyze the agents’ cooperation rate. They find that competitive and self-interested LLM agents show a lower cooperation rate, while altruistic agents demonstrate a higher cooperation rate, indicating the feasibility of constructing agents with different preferences through natural language.
Prompt Explanation: The AI was directed to simulate agents’ economic decision-making by being prompted with scenarios from classic behavioral economics experiments and asked to respond as a human would.
Horton [96] replicated classic behavioral economics experiments using LLMs, including unilateral dictator games, fairness constraints [106], and status quo bias [170], confirming the human-like nature of LLMs in aspects such as altruism, fairness preferences, and status quo bias [96]. Although the experiment was conducted simply by asking GPT questions and analyzing responses, this represents a preliminary attempt to explore the use of LLMs for simulating human economic behavior.
Prompt Explanation: The AI was prompted to respond as a human subject in social science research, conditioned on specific socio-demographic profiles.
Argyle et al. [10] use LLM agents as proxies for specific human populations to generate responses in social science research. The authors show that, conditioned on socio-demographic profiles, LLM agents can generate outputs similar to human counterparts.
Prompt Explanation: The AI was guided to simulate participants filling in open-ended questionnaires to match distributions and content of real human data.
Hamalainen et al. [87] construct LLM agents to simulate real participants to fill in open-ended questionnaires and analyze the similarity between the response and real data. The results show that synthetic responses generated by large language models cannot be easily distinguished from human data.
Prompt Explanation: The AI was instructed to simulate psychological test-takers, generating responses to cognitive and emotional intelligence assessments as if they were human participants.
Some researchers have also studied LLM agents’ ability to simulate human behavior in social psychological experiments. Specifically, they [186, 25] use psychological tests to simulate the human response to test the cognitive ability, emotional intelligence [66], and psychological well-being [123] of LLMs, demonstrating that LLM agents have human-like intelligence to a certain degree.
Prompt Explanation: The AI was directed to role-play as agents with role-specific backgrounds and goals in multi-agent collaborative frameworks for task solving (such as software development), communicating and making decisions in line with those roles.
CHATDEV [163] is a virtual software development company where LLM Agents collaborate to develop computer software, with different roles for agents including CEO, CTO, designers, and programmers. The cooperation process encompasses designing, coding, testing, and documenting, with agents engaging in role-specific tasks like brainstorming, code development, GUI designing, and documentation.
Prompt Explanation: The AI was instructed to simulate a debate among multiple agents with opposing views to reach a reasoned conclusion, with each agent role-playing a different perspective and a judge agent determining the final answer.
MAD [124] proposed to use LLM agents to engage in reasoning-intensive question answering through structured debates. LLMs adopt the roles of opposing debaters, each arguing for a different perspective on the solution’s correctness. MAD enforces a “tit for tat” debate dynamic, wherein each agent must argue against the other’s viewpoint, leading to a more comprehensive exploration of potential solutions. A judge agent then evaluates these arguments to arrive at a final conclusion.
Prompt Explanation: The AI was prompted to simulate agents assigned different personas or roles in collaborative problem-solving, with the ability to adaptively generate and coordinate diverse agents for a wide range of tasks.
AgentVerse [43] simulate human group problem-solving focusing on adaptively generating LLM agents for diverse tasks. It involves four stages: 1) Expert Recruitment, where agent composition is determined and adjusted; 2) Collaborative Decision-Making, where agents plan problem-solving strategies; 3) Action Execution, where agents implement these strategies; 4) Evaluation, assessing progress, and guiding improvements.
Prompt Explanation: The AI was guided to simulate multi-persona collaborative reasoning within a single LLM, with each persona contributing to problem-solving as if they were separate agents.
Wang et al. [210] introduce Solo Performance Prompting (SPP) to emulate human-like cognitive synergy, which transforms a single LLM into a multi-persona agent, enhancing problem-solving in tasks requiring complex reasoning and domain knowledge.
Prompt Explanation: The AI was instructed to simulate a chain of information transmission, reflecting and amplifying biases or stereotypes as would occur in human social communication.
Acerbi et al. [1] demonstrate that the information transmitted by large language models mirrors the biases inherent in human social communication. Specifically, LLM exhibits preferences for stereotype-consistent, negative, socially oriented, and threat-related content, reflecting biases in its training data. The observation underscores that LLMs are not neutral agents; instead, they echo and potentially amplify existing human biases, shaping the information they generate and transmit.
⏰ When is this relevant?
A national grocery chain wants to understand how customers from different regions (urban, suburban, rural) might respond to a proposed loyalty app that offers digital coupons, personalized deals, and mobile checkout. The team wants to simulate realistic customer interviews to identify barriers and motivators for app adoption before investing in a pilot rollout.
🔢 Follow the Instructions:
1. Define audience segments: Create three distinct AI persona profiles: (a) Urban young professional, (b) Suburban parent, (c) Rural retiree. For each, specify key traits such as age, tech comfort, shopping habits, and values.
2. Prepare the simulation prompt template: Use this format for each persona:
You are a [persona description].
Below is a new digital loyalty app concept from your local grocery store:
""[Insert app description: e.g., 'A new mobile app that gives you digital coupons, recommends deals based on your shopping, and lets you skip the checkout line by paying on your phone.']""
A market researcher is interviewing you. Please answer in 3–5 sentences, honestly and naturally as your persona.
First question: What is your immediate reaction to this new loyalty app?
3. Run the initial prompt through the AI model: For each persona, generate at least 8–10 responses by varying the opening question slightly (e.g., ""Would you consider using this app? Why or why not?"" or ""What would motivate you to try this new feature?"").
4. Add follow-up questions: Based on the initial answers, ask 1–2 follow-up questions for each persona type (e.g., ""What concerns, if any, do you have about using your phone for checkout?"" or ""Would digital coupons change where you shop?""). Continue using the same persona context.
5. Thematic coding and analysis: Review the responses and tag each with themes like ""privacy concern,"" ""interest in saving money,"" ""tech hesitancy,"" ""positive about speed,"" or ""prefers paper coupons."" Summarize key motivators and pain points for each group.
6. Compare and summarize insights: Identify which app features are most and least appealing in each segment. Note any recurring objections, and highlight any surprising motivators or barriers unique to one group.
🤔 What should I expect?
You'll receive a set of realistic, persona-specific interview transcripts revealing likely adoption drivers and obstacles for the loyalty app. This allows the business to quickly gauge which segments are ready for digital adoption, which features matter most, and what adjustments or communications might be needed before a market launch—all without the time or cost of live fieldwork.



