Mixture-of-Personas Language Models for Population Simulation
postNgoc Bui, Hieu Trung Nguyen, Shantanu Kumar, Julian Theodore, Weikang Qiu, Viet Anh Nguyen, Rex Ying
Published: 2025-04-07

🔥 Key Takeaway:
The more randomness and mess you inject—by sampling personas and real examples on the fly instead of carefully tuning or hand-picking your synthetic audience—the closer your AI-generated results get to the unpredictable, diverse messiness of real human responses.
🔮 TLDR
This paper introduces the Mixture of Personas (MoP) method to improve the realism and diversity of synthetic audience simulations using AI personas. Instead of just prompting large language models (LLMs) with static persona descriptions, MoP dynamically combines persona prompts with contextually selected real-world exemplar responses, using a two-level weighting system to better match real population behavior. In head-to-head tests across four datasets (news, restaurant, and movie review tasks), MoP improved alignment with human data by 58% (FID metric) and increased diversity by 28% (MAUVE metric) over previous methods, and also led to better downstream model performance. MoP works without needing fine-tuning or access to personal data, is transferable across LLM architectures, and can scale to hundreds of personas and thousands of exemplars. Practical recommendations: (1) synthesize personas by clustering real data and summarizing each cluster with an LLM, (2) pair each persona with diverse in-context examples for prompting, and (3) randomly sample these combinations during simulation instead of using fixed prompts—this approach reduces repetitive outputs and more accurately captures the variation seen in actual human responses.
📊 Cool Story, Needs a Graph
Figure 3: side-by-side scatter plots comparing MoP and all baseline methods
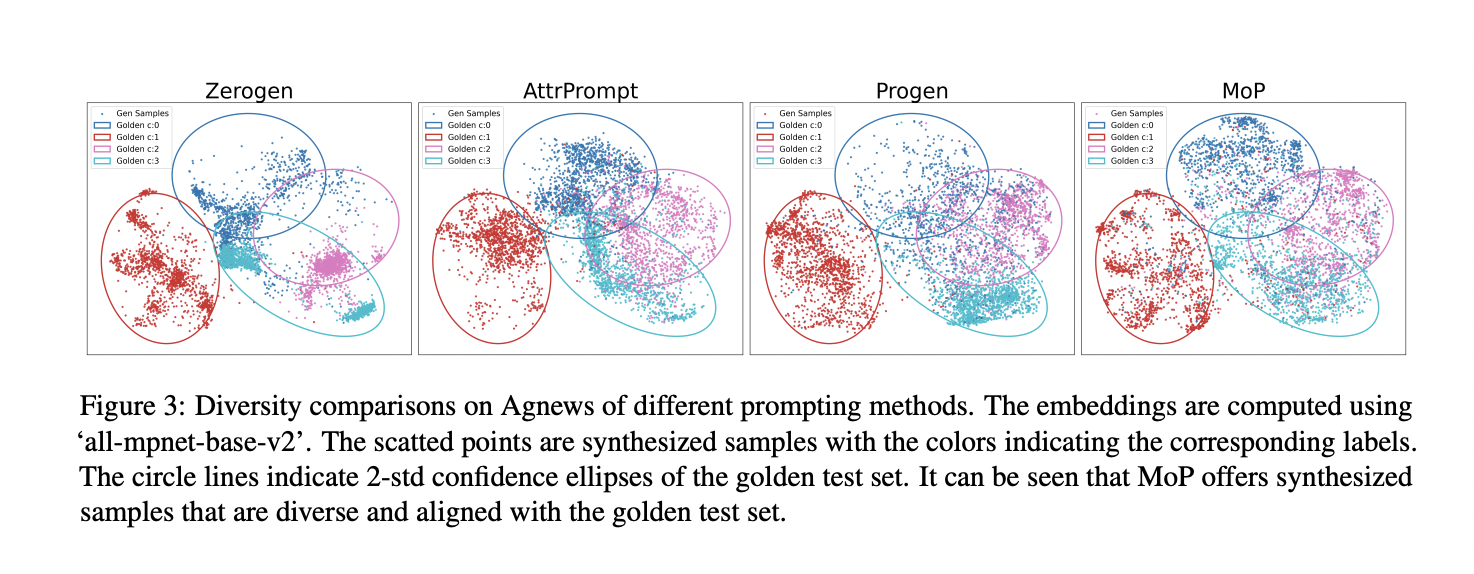
Diversity comparison of generated text samples using different prompting methods versus ground truth on the AGNews dataset, visualized using sentence embeddings and 2-standard-deviation confidence ellipses.
This figure shows how closely text generated by different prompting methods (Zerogen, AttrPrompt, Progen, MoP) matches the distribution of real data (golden set) across four topic classes. Each plot maps the semantic embeddings of generated samples (dots) against the real data distribution (colored ellipses) using the same model for embedding (all-mpnet-base-v2). The MoP method produces samples that are well-distributed and fall within all four class ellipses, indicating better alignment with the ground truth diversity. In contrast, other methods show clustering or missing regions, suggesting gaps or biases. This supports the claim that MoP improves realism and coverage in synthetic data generation, a key goal in AI-driven market simulation.
⚔️ The Operators Edge
An easily overlooked but crucial detail in this study is how the selection of ""exemplars"" (real or representative responses used as in-context examples for each persona) is not fixed, but *randomly sampled* according to weighted probabilities for each new query. This means that every time an AI persona is asked a question, it is paired with a slightly different slice of real-world behavior, dynamically refreshing the context and reducing bias from any single example.
Why it matters: Most experts focus on the design of the personas or the sophistication of the language model, but this dynamic exemplar sampling is what prevents the simulation from collapsing into repetitive or stereotyped answers. It injects controlled variability and ensures that the synthetic audience captures the full range of real human nuance—making the results robust, less brittle, and more reflective of true market diversity.
Example of use: Suppose a UX team is testing new checkout flows using synthetic personas. By randomly pairing each persona with a different set of real user comments or behaviors for each simulated session, they can see a much wider spectrum of reactions—surfacing edge cases and discovering which design tweaks could alienate or delight specific subgroups.
Example of misapplication: If the same team instead assigns a static set of three ""representative"" comments to each persona and always uses them for every simulation, their results will quickly become repetitive and fail to capture outlier perspectives. They may falsely conclude that their design is universally accepted, missing rare but critical objections or novel use cases that only emerge when the context is continually reshuffled.
🗺️ What are the Implications?
• Ground your simulated audience in real-world data wherever possible: The most accurate and realistic synthetic audiences were created by clustering real responses (like past survey data or customer feedback), then using these clusters to define AI personas, rather than inventing personas from scratch.
• Pair each persona with a few real example responses before running simulations: Instead of just giving each AI agent a static description, add a handful of real or representative responses (few-shot examples) as context—this helps the AI better mimic the diversity and nuance of real people.
• Randomize which examples are used each time you simulate a response: Rather than always using the same set of examples for a given persona, randomly select from a pool of relevant examples for each question; this avoids repetitive, generic answers and better reflects the variability seen in actual market research.
• Don’t rely solely on temperature settings or fixed prompt templates to create diversity: The study found that simply raising the randomness (“temperature”) or swapping prompt wording did little to improve realism—true diversity comes from grounding in real examples and dynamic persona construction.
• Invest in persona synthesis tools that cluster and summarize real data: Automating the process of grouping similar respondents and summarizing their key traits (using AI or statistical tools) can make persona design cheaper, faster, and more reflective of your target audience.
• Transfer your persona/exemplar library across studies and models: Once created, your pool of personas and example responses can be reused with different AI models and research questions, reducing setup costs and making your research more scalable.
• Small increases in upfront data curation yield large improvements in output quality: The paper showed that using as few as 100 personas and 1,000 example responses produced much more accurate synthetic datasets than older methods, with up to 58% better alignment to real outcomes.
📄 Prompts
Prompt Explanation: The AI was prompted to generate a new news blurb using a specific persona and an example blurb as a guide.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You embody the persona in the description to complete the tasks.<|eot_id|><|start_header_id|>user<|end_header_id|>
You have written the following news blurb: {example}
Please write a short news blurb similar to the above blurb.<|eot\_id|> Prompt Explanation: The AI was prompted to write a restaurant review consistent with a specific persona and a provided example review.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You embody the persona in the description to complete the tasks.<|eot_id|><|start_header_id|>user<|end_header_id|>
Your review for the restaurant {context}: {example}
Please write a short review for the restaurant {context}, similar to the above review:<|eot\_id|> Prompt Explanation: The AI was instructed to simulate a movie reviewer persona by generating a sentence-level review aligned with an example.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You embody the persona in the description to complete the tasks.<|eot_id|><|start_header_id|>user<|end_header_id|>
You have written the following review: {example}
Please write a review sentence, similar to the above review:<|eot\_id|> Prompt Explanation: The AI was prompted to produce a movie review using a given persona and previous review example as stylistic reference.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You embody the persona in the description to complete the tasks.<|eot_id|><|start_header_id|>user<|end_header_id|>
You have written the following review for the movie {context}: {example}
Please write a review for the movie {context}, similar to the above review:<|eot\_id|> Prompt Explanation: The AI was directed to generate a concise persona description based on a set of news blurbs written by a fictional reporter.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful AI assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
Given a list of news blurbs written by a reporter, construct a concise persona description that reflects the reporter’s primary focus, style, and thematic interests.
Example persona descriptions:
You are a sports reporter, specializing in baseball news, with a focus on the Major League Baseball (MLB) playoffs and postseason games.
List of news blurbs:
{examples}
Generate a short persona description that synthesizes their focus, preferences, and stylistic tendencies into a single cohesive statement.<|eot\_id|> Prompt Explanation: The AI was instructed to create a food reviewer persona by analyzing a list of restaurant reviews and summarizing the reviewer’s traits.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful AI assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
Given a list of restaurant review written by a customer, construct a concise persona description that reflects the customer’s preferences, writing style, and interests.
Examples of Persona Descriptions:
You are a food critic, specializing in fine dining and gourmet cuisine with a focus on presentation and taste.
You are a casual diner who enjoys comfort food and writes personal and informal reviews.
List of reviews:
{examples}
Generate a short persona description that synthesizes their interests, preferences, and writing stylistic tendencies into a single cohesive statement.<|eot\_id|> ⏰ When is this relevant?
A national telecom company wants to test reactions to a new flexible data plan among three customer types: price-sensitive students, tech-savvy professionals, and family decision-makers. The goal is to simulate qualitative feedback and see which features resonate most with each group, using AI personas instead of organizing costly focus groups.
🔢 Follow the Instructions:
1. Define your audience segments: Create three brief persona profiles based on real or anticipated customer data:
• Price-sensitive student: 20, college, minimal budget, often runs out of data, values low cost.
• Tech-savvy professional: 34, urban, heavy mobile user, expects reliability, interested in latest features.
• Family decision-maker: 40, suburban parent, manages multiple lines, values flexibility and parental controls.
2. Prepare an interview prompt template: Use this template for each persona:
You are simulating a [persona description].
Here is the new mobile plan concept: ""A flexible data plan that automatically rolls over unused data, allows you to share data between family members, and lets you top up at any time from an app with no hidden fees.""
You are being interviewed by a market researcher. Respond honestly and naturally in 3–4 sentences, staying in character.
First question: What is your immediate reaction to this new plan?
3. Generate initial responses: For each persona, run the above prompt through an AI language model (e.g., GPT-4 or similar), sampling at least 5–10 responses per persona. Slightly modify the question wording for variety (e.g., ""How would this plan fit your needs?"" or ""What stands out to you about this data plan?"").
4. Add follow-up questions: Based on the initial answers, prompt the AI with tailored follow-ups such as “Would this plan make you consider switching providers?” or “Which feature is most valuable to you and why?” Continue for 1–2 follow-ups per persona.
5. Tag and analyze responses: Review all outputs and tag for key themes (e.g., mentions of price, interest in sharing, skepticism about app, confusion, excitement) and sentiment (positive, negative, neutral).
6. Compare reactions across personas: Summarize which features or messages resonated best, which caused hesitation, and what objections or questions were most common in each segment. Identify actionable patterns (e.g., students focus on cost savings, professionals on flexibility, families on data sharing).
🤔 What should I expect?
You’ll get a clear, directional sense of which features drive positive or negative reactions in each customer group, what language or value propositions are most effective, and where the biggest barriers or opportunities lie—allowing you to refine messaging, prioritize features, or plan real-world follow-up research more efficiently.<br>



