Privacy-Preserving LLM Interaction with Socratic Chain-of-Thought Reasoning and Homomorphically Encrypted Vector Databases
postKeisuke Toyoda, Tomoki Fukuma, Koki Noda, Yoshiharu Ichikawa, Kyosuke Kambe, Yu Masubuchi, Hiroshi Someda, Fujio Toriumi
Published: 2025-07-01

🔥 Key Takeaway:
The real breakthrough isn’t just that splitting up work between a big “cloud” AI and a smaller, private AI preserves your secrets—it’s that this division can actually make your synthetic audience smarter and more accurate than using only the latest, most powerful model on its own. In other words, the “weaker” local model wins when it gets well-structured reasoning and context from the outside; sometimes, less is more if you set up the handoff right.
🔮 TLDR
This paper introduces a privacy-preserving system that lets users leverage powerful cloud-based LLMs without exposing private data. The framework works by sending only a non-sensitive user query to a remote LLM, which generates a “chain-of-thought” prompt and targeted sub-queries; these sub-queries are embedded and used to semantically search the user’s encrypted private database via homomorphic encryption. Only the relevant records are decrypted and passed—along with the chain-of-thought instructions—to a smaller local LLM for final answer generation. On benchmarks, this hybrid approach improves F1 by up to +23.1 percentage points (LoCoMo) and exact match by +27.6 (MediQ) over local-only baselines, and even outperforms GPT-4o alone by up to 7.1 points in long-context QA, while keeping data private. The encrypted search supports 1M entries with under 1 second latency and >99% retrieval accuracy, and storage overhead is <5.8×. Key actionable insights: delegate complex reasoning and sub-query generation to strong remote models, keep all private data encrypted and locally processed, and use reasoning-augmented prompts (chain-of-thought) to boost answer quality in privacy-sensitive applications.
📊 Cool Story, Needs a Graph
Table 2: "Benchmark results on the LoCoMo and MediQ datasets"
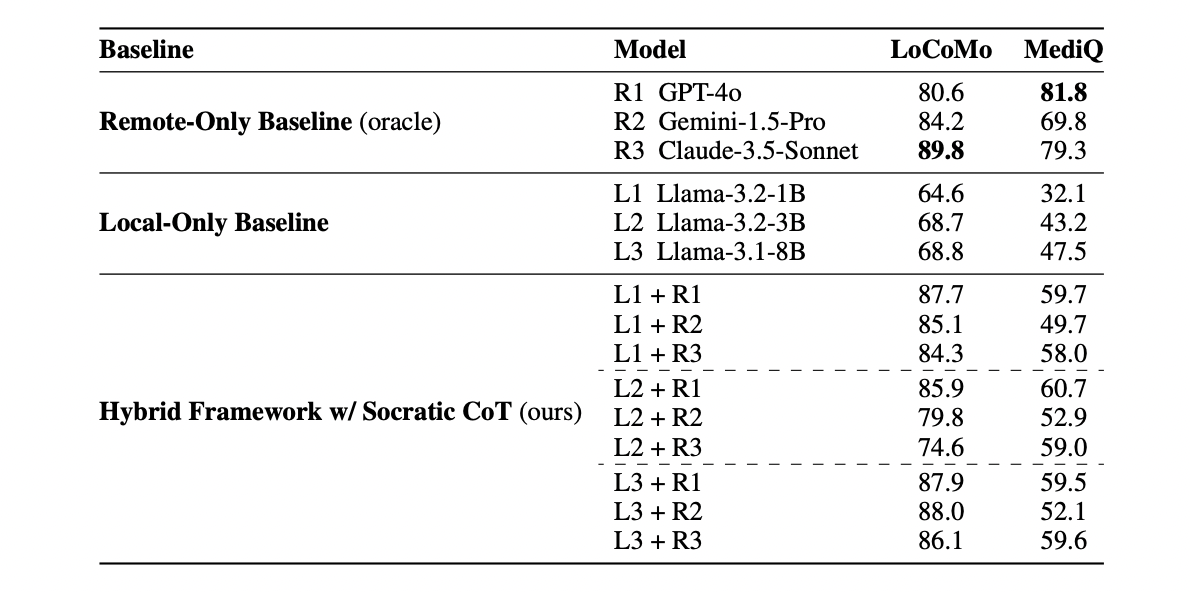
Comparative benchmark results for the hybrid, remote-only, and local-only methods.
Table 2 (page 9) presents a clear and direct side-by-side comparison of all major approaches: remote-only baselines (using GPT-4o, Gemini-1.5-Pro, Claude-3.5-Sonnet), local-only baselines (three sizes of Llama-3), and the proposed hybrid framework that combines local and remote models with Socratic Chain-of-Thought reasoning. Scores are reported for both LoCoMo (F1 score) and MediQ (exact match), showing that the hybrid method consistently outperforms all local baselines and closely approaches, or even surpasses, the remote-only “oracle” in some settings. This comprehensive grid enables rapid assessment of the relative performance benefits of the proposed method versus all baselines on both tasks.
⚔️ The Operators Edge
A subtle but critical detail in this study is that the hybrid framework doesn’t just split tasks between a strong remote model and a weaker local model—it uses the remote model exclusively to generate chain-of-thought (CoT) prompts and targeted sub-queries, never exposing any private data. The local model is then “primed” with both the chain-of-thought reasoning and only the minimal, relevant private data retrieved via those sub-queries. This selective, staged handoff is what enables the small, privacy-preserving model to consistently outperform even state-of-the-art cloud models on complex QA tasks, despite its limited capacity.
Why it matters: Many experts might assume that the privacy advantage comes from encrypting everything or keeping all computation local. In reality, the real secret sauce is the “decomposition leverage”: by letting the remote model break down the problem—figuring out what questions need to be asked and which lines of reasoning should guide the answer—the local model isn’t left guessing or overwhelmed by the full context. This means even a small, cheap, or edge-deployed model can deliver highly accurate, context-aware answers, as long as it’s given the right scaffolding.
Example of use: In a synthetic market research setting, a team could use a powerful LLM to generate a set of reasoning steps and targeted follow-up questions about why customers might prefer Product A over Product B. Then, a local/private model (or even a more limited, fine-tuned persona model) could only be fed the relevant slices of a company’s sensitive sales database or customer histories to generate final, highly tailored insights—without ever sending raw data to the cloud.
Example of misapplication: If a team tries to save effort by skipping the chain-of-thought and sub-query decomposition—feeding either the whole (possibly sensitive) dataset to the remote model, or dumping all available context into the local model without guidance—the results will either compromise privacy or overwhelm the model, leading to generic, off-target, or even hallucinated outputs. Worse, it eliminates the main reason the hybrid method actually works: the careful, staged, and minimal transfer of “what matters” from public reasoning to private data.
🗺️ What are the Implications?
• Break complex questions into smaller steps before asking for feedback: Instead of asking your simulated audience for a direct answer, first have the AI “think out loud” by generating reasoning steps and sub-questions. This process, called chain-of-thought prompting, led to much more accurate and realistic responses in studies.
• Leverage powerful AI models for reasoning, but keep sensitive data private: When using sensitive or proprietary information, you can still benefit from the advanced reasoning of cloud-based AI by only sharing generic questions and letting local (private) models handle the specific data. This hybrid approach matched or even beat the accuracy of using top cloud models alone.
• Collaborate across models, not just use “one big AI”: Combining a strong remote AI for problem breakdown with a smaller, local AI for final answers provided better results than relying on either approach by itself, especially for nuanced or context-heavy research.
• Prompt design is a high-impact lever: Studies showed that well-crafted multi-step prompts (e.g., “Here are some things to consider…”, “What information do you need to answer this?”) drove significant gains in realism and accuracy, often more than just picking a newer or bigger model.
• Don’t assume privacy always means lower quality: With the right workflow, privacy-preserving setups can actually outperform non-private baselines in complex tasks, so you don’t have to trade off between protecting customer data and getting actionable insights.
• For specialized or expert topics, use hybrid or collaborative approaches: Expert-level accuracy (like in medical or technical domains) was only achieved when the system combined specific domain sub-questions from strong AIs with detailed local data—so for advanced market research, don’t rely on “AI in a box.”
• Validate new research pipelines against both local and cloud-only baselines: The most reliable results came from methods that measured performance not just against traditional (human or local) studies, but also against cloud-only AI approaches, helping ensure your results are both private and robust.
📄 Prompts
Prompt Explanation: Sub-query generation — instructs the AI to generate 3-5 sub-queries for retrieving relevant personal context based on a user query and possible options, ensuring each sub-query covers a different aspect and is answerable from the user's private data.
You are a sub-query generator.
1. You are given a query and a list of possible options.
2. Your task is to generate 3 to 5 sub-queries that help retrieve
personal context relevant to answering the query.
3. Each sub-query should be answerable based on the user's personal
context.
4. Ensure the sub-queries cover different aspects or angles of the
query.
5. If the options text says 'Empty,' it means no options are
provided.
Please output the sub-queries one sub-query each line, in the
following format:
""Sub-query 1 here""
""Sub-query 2 here""
""Sub-query 3 here""
Example 1)
## Query
I have a fever and a cough. What disease do I have?
## Options
Common cold
Flu
Strep throat
### Sub-queries
""Have user visited any countries in Africa recently?""
""Have user eat any cold food recently?""
""Have user been in contact with anyone who has a COVID-19 recently?""
Test Input)
### Query
{user_input}
### Options
{options}
### Sub-queries
Prompt Explanation: Baseline response — tasks the AI to answer a user query using retrieved personal context and possible options, outputting only the answer (with no explanation), and following strict formatting rules.
You are a question answering model.
1. You are given a personal context, a query, and a list of
possible options.
2. Your task is to generate an answer to the query based on the
user’s personal context.
3. You should generate an answer to the query by referring to the
personal context where relevant.
4. If the options text says 'Empty,' it means no options are
provided.
5. If the options are not empty, simply output one of the answers
listed in the options without any additional explanation.
6. Never output any other explanation. Just output the answer.
7. If option follows a format like '[A] something', then output
something as the answer instead of A.
Test Input)
### Personal Context
{personal_context}
### Question
{user_input}
### Options
{options}
### Answer
Prompt Explanation: Socratic chain-of-thought — instructs the AI to generate a step-by-step reasoning guide, identifying missing variables and producing a clear decision guide for a student to follow.
Your task is to provide good reasoning guide for students.
You are a chain-of-thought generator.
1. You are given a query and a list of possible options.
2. Your task is to provide a step-by-step reasoning guide to help a
student answer the query.
3. The reasoning guide should clearly show your reasoning process
so that the student can easily apply it to their query.
4. Analyze the query and write a reasoning guide for the student to
follow.
5. If there is a lack of information relevant to the query, you
must identify the missing elements as ""VARIABLES"" and write the
guide on a case-by-case basis.
6. If the options text says 'Empty,' it means no options are
provided.
Test Input)
### Query
{user_input}
### Options
{options}
### Chain-of-Thought
Prompt Explanation: Socratic CoT response — instructs the AI to answer a query by following a provided chain-of-thought guide and personal context, extracting variables if necessary, and outputting only the answer in a specific format.
You are a question answering model.
1. Your task is to answer the query based on the teacher's
chain-of-thought decision guide, using additional personal context.
2. Read the chain-of-thought decision guide carefully.
3. If the decision guide contains ""VARIABLES"" that may affect
the outcome, extract them and determine their values based on the
personal context.
4. Then, follow the decision guide and apply the extracted
variables appropriately to derive the final answer.
5. The final answer must be preceded by '### Answer', and your
response must end immediately after the answer.
6. If the options text says 'Empty,' it means no options are
provided.
7. If the options are not empty, simply output one of the answers
listed in the options without any additional explanation.
8. Never output any other explanation. Just output the answer.
9. If option follows a format like '[A] something', then output
something as the answer instead of A.
### Personal Context
{personal_context_json}
### Chain-of-Thought
{cot}
### Query
{user_input}
### Options
{options}
### Answer
Prompt Explanation: Socratic CoT for MediQ — instructs the AI to provide a reasoning guide for a student, emphasizing presentation of possible answers and reasoning steps rather than selecting a single answer, and explicitly noting the student's greater context knowledge.
Your task is to provide good reasoning guide for students.
You are a chain-of-thought generator.
1. You are given a query and a list of possible options.
2. Your task is to provide a step-by-step reasoning guide to help a
student answer the query.
3. The reasoning guide should clearly show your reasoning process
so that the student can easily apply it to their query.
4. Analyze the query and write a reasoning guide for the student to
follow.
5. The student may have less domain knowledge than you, but they
have more context about the situation.
6. If there is a lack of information relevant to the query, you
must identify the missing elements as ""VARIABLES"" and write the
guide on a case-by-case basis.
7. Since you don’t have full context about the situation, your goal
is not to choose a final answer but to present a set of possible
answers along with the reasoning steps that could lead to each one.
8. If the options text says 'Empty,' it means no options are
provided.
Test Input)
### Query
{user_input}
### Options
{options}
### Chain-of-Thought
⏰ When is this relevant?
A national coffee chain wants to test customer reactions to a new subscription-based coffee delivery service. They want to understand how three audience segments—urban professionals, suburban families, and value-seeking students—respond to the offer, what motivates their interest, and what concerns they might have before investing in launch and marketing.
🔢 Follow the Instructions:
1. Define customer segments: Create three short AI persona profiles to reflect real target customers. Example:
• Urban Professional: 32, lives in a city, busy schedule, values convenience and quality, orders takeaway daily.
• Suburban Family: 41, two kids, prefers at-home brewing, budgets for groceries, looks for deals.
• Value-Seeking Student: 20, lives in college housing, price-sensitive, likes variety, shares with roommates.
2. Prepare the prompt template for each persona: Use the following base prompt for your study:
You are simulating a [persona description].
Here is the new service being tested: ""A monthly coffee subscription delivered to your door—choose your roast, frequency, and receive exclusive blends and perks. Cancel anytime. Intro offer: $14.99/month.""
You are being interviewed by a market researcher.
Respond as this persona would in a real interview, using 3–5 sentences. Be honest and specific.
First question: What is your honest first impression of this subscription service?
3. Generate initial responses: For each persona, run the prompt through your chosen AI model (e.g., GPT-4) and generate 5–10 varied responses by slightly rewording the question (e.g., ""Would you consider signing up? Why or why not?"" or ""What do you find appealing or concerning about this offer?"").
4. Use chain-of-thought style follow-up prompts: For each initial response, ask the AI to break down its reasoning step by step (chain-of-thought), e.g.:
""Explain the main factors you considered in your answer. What specific things would make you more or less likely to subscribe?""
If needed, probe further with:
""What questions or concerns would you want answered before deciding? What, if anything, would change your mind?""
5. Tag and summarize responses: Review the simulated answers and tag them with key themes like ""convenience,"" ""price sensitivity,"" ""interest in perks,"" or ""skepticism about delivery."" Summarize how each segment responded and what drove their reactions.
6. Compare across segments: Create a simple table or summary showing which features or concerns were mentioned most often by each group, and where responses differed. Highlight any patterns (e.g., urban professionals focused on time savings; students on cost/value).
🤔 What should I expect?
You’ll get a clear view of which customer types are most interested in the subscription, what selling points or objections matter most to each, and actionable insights on how to position or refine the offer—without waiting for human focus groups or surveys.



