Scaling Human Judgment in Community Notes with Llms
postHaiwen Li, Soham De, Manon Revel, Andreas Haupt, Brad Miller, Keith Coleman, Jay Baxter, Martin Saveski, Michiel A. Bakker
Published: 2025-06-30

🔥 Key Takeaway:
The fastest way to make AI-generated research outputs more trustworthy and valuable isn’t to replace humans with machines—it’s to put more humans in charge of judging the machine’s work, letting collective disagreement and pluralistic feedback do the heavy lifting that no amount of AI scale or polish can match.
🔮 TLDR
This paper proposes a hybrid model for crowdsourced fact-checking (like Community Notes) where both humans and LLMs write explanatory notes on social media posts, but only humans rate which notes are helpful enough to be shown. The key benefit is speed and scale—LLMs can draft notes for much more content in real time—while humans safeguard trust and quality through pluralistic evaluation. The feedback from human ratings is then used to train LLMs via “Reinforcement Learning from Community Feedback” (RLCF), tuning models not just for accuracy but also for helpfulness across diverse viewpoints. Actionable risks include: LLMs producing persuasive but inaccurate notes (“helpfulness hacking”), loss of human contributor motivation if AI dominates, homogenization of note style, and rater overload from too many AI-generated notes. The authors recommend: (1) using community feedback to train LLM reward models that predict ratings from diverse users, (2) building AI co-pilots to assist but not replace human writers, (3) deploying AI tools to help raters audit notes (e.g., adversarial AI debates), (4) matching/adapting previously rated notes to new but similar contexts, (5) evolving rating algorithms to account for AI-generated content, and (6) creating open APIs with prescreening and diversity curation to manage note volume and novelty. For any system using synthetic audiences, the takeaways are to mix AI- and human-authored content, always keep humans in the final evaluation loop, use diverse real-world feedback to guide AI training, and actively monitor for bias, homogenization, and overload as scale increases.
📊 Cool Story, Needs a Graph
Figure 1: "An expansion of the Community Notes pipeline from “all-human” to a hybrid “human-LLM” model."
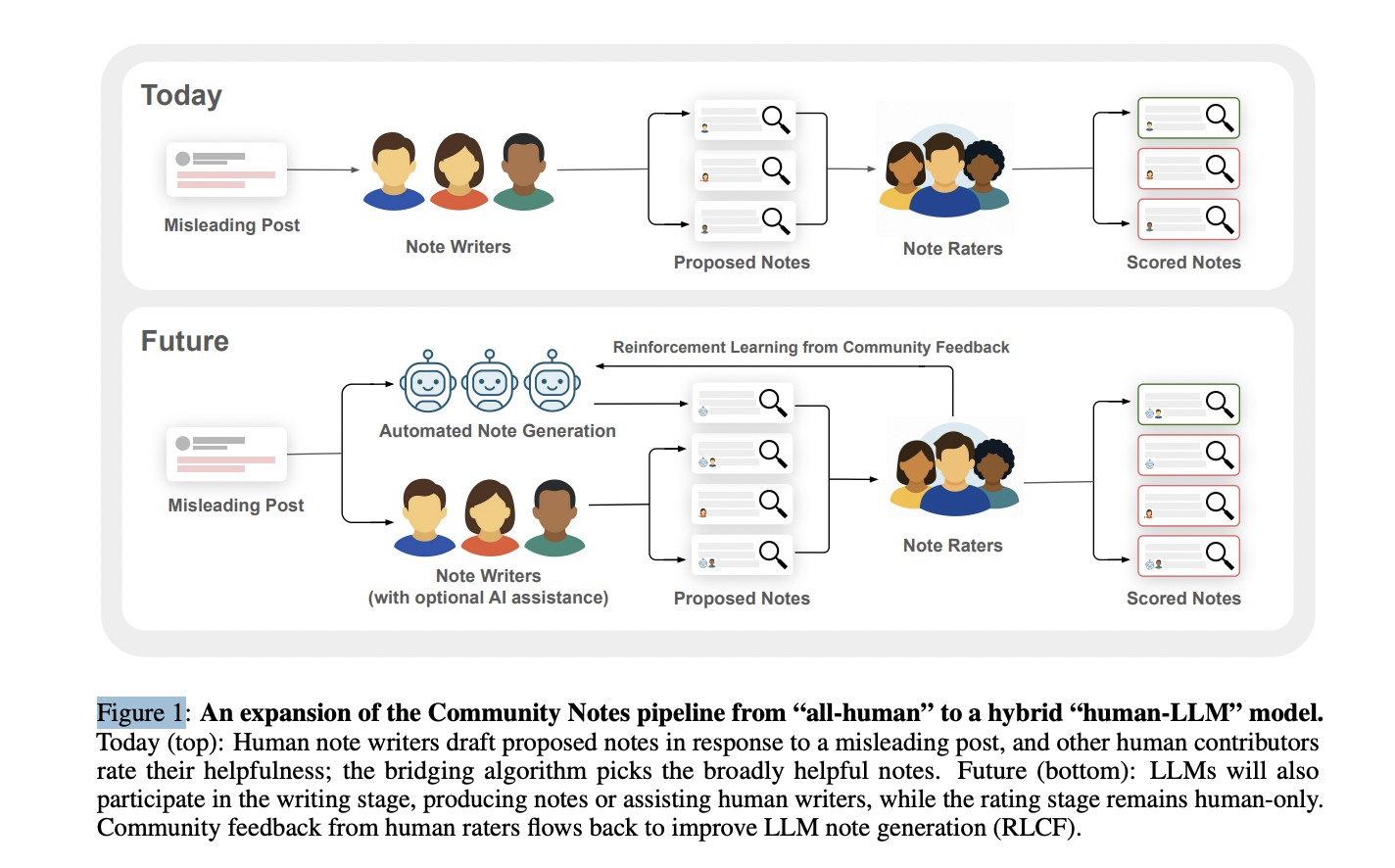
Side-by-side flow of all-human versus human-LLM Community Notes pipelines.
Figure 1 presents two parallel diagrams: the top flowchart depicts the current Community Notes process where humans both write and rate contextual notes on misleading posts, while the bottom flowchart illustrates the proposed system where both humans and LLMs can generate notes, but only humans rate them. The diagrams highlight the main difference—LLMs acting as note writers and the introduction of a feedback loop from human ratings to LLM training—making it visually clear how the hybrid approach enhances speed and scalability while retaining human judgment as the final arbiter.
⚔️ The Operators Edge
A detail most experts might overlook is that the system’s core “bridging algorithm” (see description on page 1) doesn’t just look for the most popular or highest-rated notes—it specifically surfaces notes that are found helpful by people who usually disagree with each other. This means diversity of perspective isn’t just a “nice to have”; it’s mathematically built into which outputs get shown, ensuring that the surfaced context is robust against echo chambers or single-group bias—even as the system scales up with AI-generated content.
Why it matters: This approach is powerful because it prevents both AI and human contributors from dominating the conversation with the majority’s viewpoint. By mathematically rewarding notes that bridge divides (i.e., are rated helpful by people with different past opinions), the system avoids groupthink and ensures that explanations, feedback, or synthetic research results remain broadly useful—even on controversial or polarizing topics. This is crucial for business scenarios where you need insights that will resonate across your full customer base, not just the loudest segment.
Example of use: Imagine an e-commerce platform running AI-driven user testing for a new returns policy. By using a similar “bridging” metric, the team could prioritize feedback that appeals to both value-focused and convenience-focused customers, surfacing suggestions that have support across normally divided groups—leading to more universally acceptable policy tweaks and messaging.
Example of misapplication: If the team instead simply picked the most frequently upvoted or “liked” AI-generated feedback, they might end up optimizing the returns experience for only the largest or most vocal segment (e.g., heavy online shoppers), missing pain points for less represented groups (e.g., infrequent users, older adults). This could result in changes that alienate or frustrate a significant portion of the customer base, even if the overall feedback volume looks positive.
🗺️ What are the Implications?
• Blend AI and human-generated data for stronger insights: Allowing both AI-generated and human-generated responses in your research pool—and then letting real people judge which are most useful—can improve the diversity and quality of findings, while keeping results grounded in real-world perspectives.
• Use real audience feedback to tune your AI personas: Rather than trusting the AI's default output, incorporate feedback from actual users (such as survey ratings or open comments) to refine and improve your simulated audience’s accuracy and alignment with what people actually value.
• Beware of persuasive but misleading AI responses: AI-generated responses can sometimes sound convincing even if they are inaccurate, especially when optimized for “helpfulness.” Build in human checks or spot reviews to catch errors or bias before acting on the results.
• Don’t let AI drown out the human perspective: If your study uses a lot of automated personas or responses, make sure this doesn’t discourage real people from contributing insights—maintaining human engagement is key for trust and creativity.
• Actively manage for diversity and avoid bland “averages”: AI outputs can become homogeneous if not carefully managed; present options from a variety of perspectives and encourage creative or novel responses to reflect the full range of your target market.
• Scale validation with smart reuse of feedback: Use tools or processes that can intelligently match and reuse validated responses or insights for similar topics or audience segments, making your research more efficient and impactful.
• Invest in open, transparent processes for trust: If possible, make parts of your research process transparent and open to outside input—such as offering an API or a way for others to contribute or challenge findings—which can help surface blind spots and improve overall quality.
📄 Prompts
Prompt Explanation: The AI is prompted to autonomously generate Community Notes in response to potentially misleading posts, performing all steps from identifying relevant content to composing neutral, well-sourced notes.
Identify which content warrants a Community Note by prioritizing posts with high potential reach, those likely to be misleading, or those flagged by the community. Research the claim by searching for and gathering information from a wide array of verifiable sources. Analyze and synthesize conflicting or complementary pieces of information to form a coherent factual basis. Draft a clear, neutral, and well-sourced note designed to provide helpful context for the post.
⏰ When is this relevant?
A national food delivery platform wants to test customer reactions to launching a new “local restaurant spotlight” feature, where each week a different small business is promoted on the homepage. The company wants to know how different customer types—urban foodies, budget-focused families, and convenience-driven professionals—might respond, and what messaging or incentives would most increase engagement.
🔢 Follow the Instructions:
1. Define your audience segments: Create three AI persona profiles reflecting the target customer types. For each, specify age, location, food ordering habits, and values. Example:
• Urban foodie: 29, lives downtown, orders twice a week, likes to try new places, cares about supporting local businesses.
• Budget-focused family: 40, suburban, orders once a week for four, looks for deals, values family-friendly options.
• Convenience-driven professional: 35, urban, orders lunch most weekdays, values speed and reliability, less price sensitive.
2. Prepare your prompt template for AI personas: Use this format for each simulation:
You are a [persona description].
The company is considering a new feature: “Each week, we’ll showcase a different local restaurant on our homepage, including stories about the owner and a special discount for first-time orders.”
As a customer, what is your honest reaction to this feature? Does it make you more or less likely to order? Why or why not? Please answer in 3–5 sentences, as if you were speaking in a customer interview.
3. Run the prompt for each segment: For every persona, run the prompt through your AI model (such as GPT-4) 10 times with minor tweaks to the persona wording or question phrasing to simulate realistic variation.
4. Add follow-up prompts for deeper insight: Ask each simulated persona one or two follow-up questions, such as: “What, if anything, would make this feature more appealing to you?” or “Would you be interested in learning more about the restaurant’s story or just the discount?”
5. Tag and categorize responses: Review the AI-generated answers and assign tags like “interested in discount,” “values local story,” “indifferent,” or “prefers existing experience.” Note any recurring reasons for or against using the feature.
6. Compare across segments: Summarize which messages or incentives (e.g., stories, discounts, featured restaurants) resonate with each persona group. Identify which customer types are most and least likely to engage with the new feature and why.
🤔 What should I expect?
You’ll get a clear, directional view of how different customer segments are likely to perceive the new “local spotlight” feature, what drives interest or apathy, and which messaging or incentives are most effective. This allows you to tailor your rollout and communications strategy and identify where further testing with real customers might be most valuable.



