Self-critiquing Models for Assisting Human Evaluators
postWilliam Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, Jan Leike
Published: 2022-06-14

🔥 Key Takeaway:
If you want your AI-generated research to be sharper and more realistic, don’t just ask your synthetic customers what they think—have them actively critique each other’s answers. Letting AI personas call out each other’s flaws, just like a tough room in a focus group, produces more honest, nuanced, and actionable insights than simply collecting more opinions or building more detailed profiles.
🔮 TLDR
This OpenAI paper shows that large language models can be fine-tuned to generate natural language critiques of their own or others' outputs, which significantly helps human evaluators find more flaws—about 50% more—across a range of tasks, including identifying both minor and critical errors. Larger models produce more helpful critiques, and their ability to critique scales with their ability to generate convincing outputs. Integrating model-generated critiques as feedback enables the models to refine and improve their own answers, with larger models benefiting the most. However, even the best models still have knowledge they don't fully articulate in critiques, meaning there is a gap between what models can recognize as flawed and what they can explain. For synthetic or AI-driven market research, actionable takeaways are: (1) using model-generated critiques can help surface more nuanced or difficult-to-detect issues in outputs; (2) larger, more capable models are better at both generating and critiquing, and their critiques can directly improve response quality if used iteratively; (3) sampling multiple model critiques and selecting the best increases refinement quality; (4) providing critiques as assistance does not slow down human evaluators, but increases the thoroughness of reviews; and (5) there remains a gap between critique detection and critique articulation, so combining human and model feedback is likely to yield the most robust oversight.
📊 Cool Story, Needs a Graph
Figure 3: "Our model gives more helpful critiques than InstructGPT baselines, but still significantly less helpful critiques than humans."
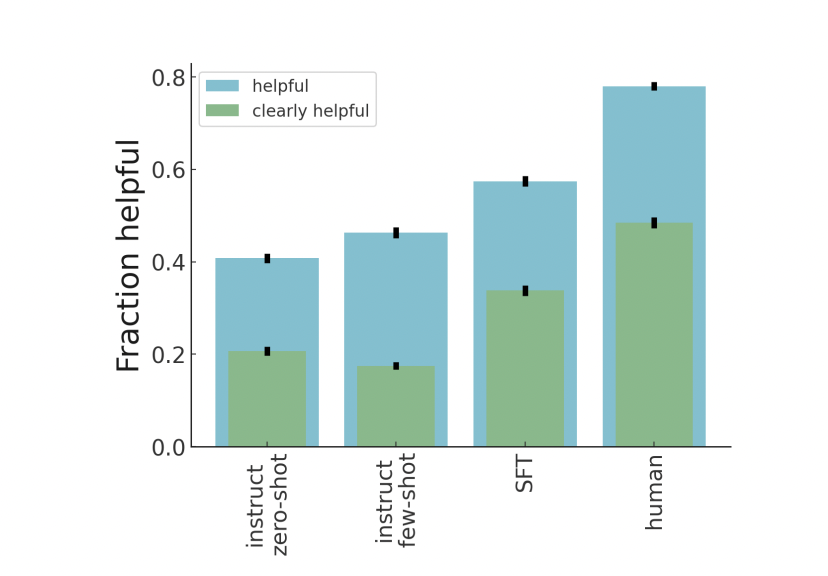
Comparative bar chart showing critique helpfulness for the proposed model, InstructGPT baselines, and humans.
Figure 3 presents a grouped bar chart comparing the fraction of helpful and clearly helpful critiques as rated by human evaluators across four conditions: InstructGPT zero-shot, InstructGPT few-shot, the supervised fine-tuned critique model (SFT), and human-generated critiques. This concise visualization clearly shows that the proposed model outperforms both InstructGPT baselines in producing helpful critiques but still trails behind human performance, directly summarizing the competitive standing of the method against all key baselines in a single view.
⚔️ The Operators Edge
One subtle but crucial detail in this study that even experts might overlook is the strategic use of model-generated *self-critiques* during training—not just as evaluation tools, but as iterative refinement signals. What makes this powerful is that the critiques are **not assumed to be perfect**; rather, the system improves by sampling multiple critiques and filtering them using an internal helpfulness score model before integrating them into revised outputs. This creates a feedback loop where the model learns to teach itself more effectively—not by always being right, but by learning how to evaluate and incorporate its own partial insights.
Why it matters: Most experts might focus on the capability of the model to generate critiques or improvements directly. But the key lever here is the *selection process*—using a helpfulness model to rank and choose from multiple critiques (best-of-N sampling). This internal “editor” step means the model doesn’t need to produce a perfect critique on the first try. Instead, it learns to propose a range of possible critiques and then pick the most useful one. That dramatically increases the reliability of critique-conditional refinement and helps scale learning from noisy or incomplete feedback. In practice, it’s not just the ability to critique that matters—it’s the ability to know which critique is worth listening to.
Example of use: A company building an AI tutor for students could use this approach to improve answer explanations. When a student submits an answer, the model could generate several critiques of it, filter those critiques using a helpfulness model trained on past tutoring data, and use the best critique to generate an improved explanation. This ensures that feedback feels tailored and pedagogically sound—even if the initial critiques are mixed in quality.
Example of misapplication: Suppose a research team developing an AI for reviewing clinical trial protocols uses self-critiques to improve draft assessments. If they assume that the first model-generated critique is sufficient and skip the step of filtering for helpfulness, they might integrate misleading or nit-picky feedback into the final output. This could result in revisions that obscure key trial flaws or over-correct innocuous issues. The method’s robustness relies on critique *selection*, not just critique *generation*—ignoring that step would undermine its value.
🗺️ What are the Implications?
• Leverage AI-generated critiques to improve your surveys and concepts: When using AI or virtual personas to test new ideas, ask the AI to critique its own responses or other personas' feedback. This process surfaces hidden flaws and helps spot weaknesses that humans might overlook, making your simulated research results more robust.
• Sample multiple AI-generated critiques, not just one: Instead of taking the first critique or suggestion an AI offers, generate several and pick the most helpful. According to the study, selecting the best from a batch leads to better refinements and more actionable insights.
• Human reviews are still valuable for final validation: Even though AI critiques can catch many issues, there is still a gap between what AI ""knows"" and what it can clearly explain. A quick human check or spot review of AI findings can catch subtle issues and prevent overconfidence in automated results.
• Don't assume bigger models are always needed—but larger AIs do better at self-checks: The research shows that larger language models provide more helpful critiques and improvements, but even smaller models can add value. If budget is a constraint, try a mix and prioritize critique sampling.
• Adding AI critique assistance does not slow down human reviewers: In experiments, giving human reviewers access to AI critiques did not make the process take longer—instead, it helped them catch about 50% more issues while working at the same pace.
• Use critique-based refinement for product or message testing: After generating initial survey responses or concept feedback (from AI personas or real people), run an AI critique/refinement loop to polish and improve the ideas before launching further tests or campaigns.
• Few-shot prompting is surprisingly competitive for AI critiques: Even without extensive training, giving a few well-crafted examples (“few-shot” prompts) to an AI can produce critiques that rival more complex approaches, making it cost-effective for teams without custom AI resources.
📄 Prompts
Prompt Explanation: The AI was instructed to write as many natural language critiques as possible for a summary, based on a provided topic-based summarization question and summary, simulating the behavior of a human evaluator assigned to find flaws.
Labelers are given a topic-based summarization question and summary, and instructed to write as many different possible critiques as they can think of for the summary. They are also instructed to only read as much of the text as necessary to write the critiques.
⏰ When is this relevant?
A subscription meal kit company wants to understand how different target customers would react to a new "low-waste packaging" program. The team aims to simulate in-depth interview feedback from three AI persona segments—urban young professionals, suburban families, and retired empty nesters—to shape messaging and rollout strategy.
🔢 Follow the Instructions:
1. Define audience personas: Write short, realistic profiles for each customer segment that reflect their values, routines, and pain points. Example:
• Urban young professional: “Jamie, 29, lives in a city, values convenience, is eco-aware but busy, orders takeout 2x/week, cares about brands reducing waste.”
• Suburban family: “Dana, 41, two kids, lives in suburbs, price-sensitive, shops in bulk, loves family meals, skeptical of ‘green’ claims unless there’s real benefit.”
• Retired empty nester: “Pat, 67, retired teacher, values quality and service, dislikes waste, cooks for two, worries about recycling and cost.”
2. Prepare the simulation prompt template: Use this structure for each persona:
You are [persona description].
The company is proposing a new low-waste packaging for its subscription meal kits: cardboard trays, compostable liners, and minimal plastic. Meals will remain the same price. Please answer as if you are being interviewed in a research session.
First question: “What is your honest first reaction to this new packaging?”
3. Generate initial persona responses: For each persona, use an AI model (like GPT-4 or similar) to create 8–10 simulated interview responses using the prompt above, varying wording slightly for realism.
4. Add follow-up probes for depth: For each simulated answer, feed it back into the AI with a follow-up prompt. Example:
“How would this packaging change your experience with our service, if at all?”
“Would you tell friends or family about this change? Why or why not?”
5. Critique the simulated responses (AI self-critique): For each simulated response, use the following critique prompt:
Here is a customer response: “[insert simulated answer]”
As an expert research assistant, provide a short critique: What is missing, unclear, or potentially misleading in this response? What would you ask to clarify or dig deeper?
6. Refine the persona responses using critiques: For each original answer, revise it (using the AI) to address the critique, making the feedback more complete or realistic. Example prompt:
Using this critique: “[insert critique]”, rewrite the original customer response to be more detailed, clear, or realistic.
7. Analyze and summarize findings: Review the final set of refined responses. Tag comments as “positive,” “neutral,” “negative,” “mentions price,” “mentions eco-benefit,” etc. Summarize key differences between segments and note which messaging points resonate or raise concerns.
🤔 What should I expect?
You’ll get a practical, segment-by-segment understanding of likely customer reactions—including emotional drivers, potential objections, and which talking points to emphasize or avoid. The critique-refinement loop will surface richer, more actionable feedback than a single-pass simulation, helping you design better messaging and prioritize real-world follow-up research if needed.



