The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
postSander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schulhoff, Pranav Sandeep Dulepet, Saurav Vidyadhara, Dayeon Ki, Sweta Agrawal, Chau Pham, Gerson Kroiz Feileen Li, Hudson Tao, Ashay Srivastava, Hevander Da Costa, Saloni Gupta, Megan L. Rogers, Inna Goncearenco, Giuseppe Sarli, Igor Galynker, Denis Peskoff, Marine Carpuat, Jules White, Shyamal Anadkat, Alexander Hoyle, Philip Resnik
Published: 2025-02-26

🔥 Key Takeaway:
Minimal nudges toward reasoning often outperform heavy-handed control, revealing that great prompting is more about guiding the model's own processing than specifying our own.
🔮 TLDR
This paper provides the most comprehensive taxonomy and benchmarking of prompt engineering techniques to date, covering 58 text-based prompting techniques and over 200 total methods, including in-context learning, chain-of-thought, ensembling, decomposition, self-criticism, and more. It highlights that prompting effectiveness is highly sensitive to exemplar selection, order, label quality, and prompt format, with performance varying by up to 40% depending on these choices (see Figs 6.5–6.6). Key findings are: (1) few-shot and chain-of-thought prompting consistently outperform zero-shot, but order and diversity of exemplars, as well as instructions, significantly affect results; (2) ensembling and self-consistency (sampling multiple outputs and majority voting) further boost reliability; (3) prompt modifications as minor as reordering examples or extra whitespace can change accuracy by 30%+; (4) automated and meta-prompting methods (e.g., DSPy) can match or exceed manual prompt engineering, especially when optimizing F1 or precision/recall; (5) prompt-based defenses, output extraction rules, and alignment measures are necessary for robustness but none are foolproof against adversarial prompt injection. For synthetic audience or virtual market research, the actionable recommendations are: use diverse, carefully ordered exemplars, experiment with prompt formats and ensembling, include answer extraction and calibration steps, and periodically rebenchmark as model versions or prompt templates change, since model sensitivity and performance drift are both significant.
📊 Cool Story, Needs a Graph
Figure 6.5
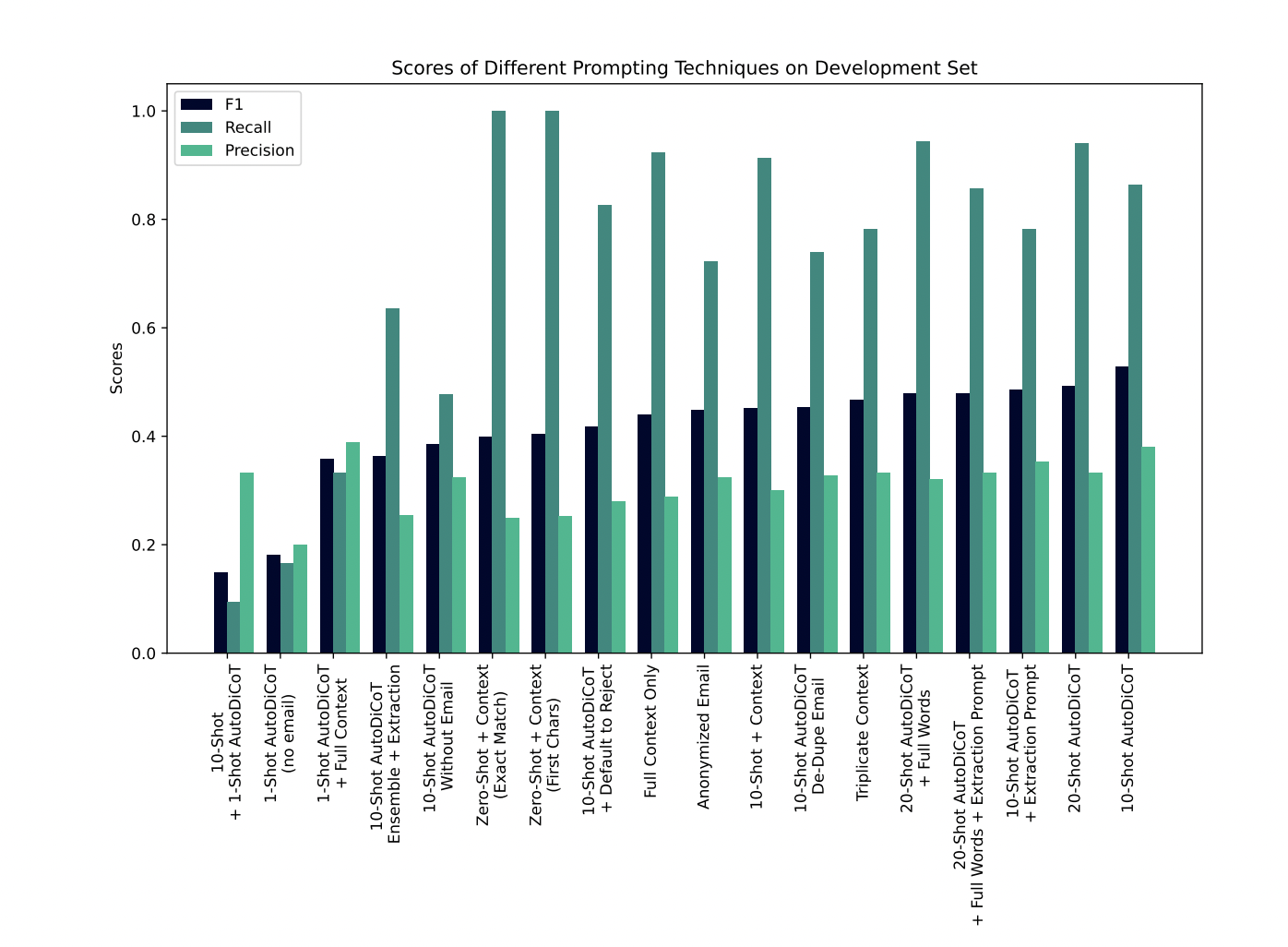
F1, recall, and precision scores for all baseline and proposed prompting techniques side-by-side on the same dataset.
Figure 6.5 (page 36) presents a grouped bar chart displaying F1, recall, and precision for each major prompt engineering technique tested on the development set, including both baseline and advanced variants (e.g., Zero-Shot, Few-Shot, AutoDiCoT, ensemble, extraction, context manipulations). This visualization enables direct comparison of the relative performance and trade-offs across methods, highlighting not only overall F1 but also the balance between precision and recall. The figure makes it clear which prompt modifications yield meaningful improvements, which do not, and how the most effective method compares in absolute and relative terms to all others in a single, easily digestible view.
⚔️ The Operators Edge
A critical but often overlooked insight from the study is that the effectiveness of few-shot prompting hinges not only on the content of the exemplars, but on their label distribution and ordering within the prompt. The paper shows that changes in the order of examples and the balance of class labels (e.g., positive vs. negative) can cause performance to swing dramatically—even in large models. While this might seem like a trivial formatting issue, it's actually a hidden lever that can make or break the utility of a prompt. For instance, one cited result showed accuracy varying from below 50% to over 90% based solely on exemplar order (Lu et al., 2021).
Why it matters: Most practitioners focus on writing clear prompts or selecting good examples, but ignore the statistical and structural properties of those examples in context. If your few-shot prompt has unbalanced labels—say, four positive reviews and one negative—it can bias the model's output toward the majority class, regardless of the actual input. Similarly, placing a particularly representative example last may carry disproportionate influence due to recency effects in transformer attention. These effects compound in subtle ways and can significantly skew evaluation results or downstream product behavior.
Example of use: Suppose you're testing a moderation AI to flag hate speech. Instead of randomly pulling five examples of labeled text, you deliberately construct your prompt so it contains a 3:2 ratio of "Hate Speech" and "Not Hate Speech," mirroring the dataset's real-world distribution. You also experiment with multiple exemplar orderings to identify which configuration yields the most robust performance across different input types. This improves your model’s generalization and trustworthiness when deployed.
Example of misapplication: A research team runs a batch of few-shot prompts to assess a model's ability to detect toxic content. They use five well-labeled examples, but all happen to be toxic due to copy-pasting from a test file. The model then over-predicts toxicity on neutral inputs, leading the team to believe the model is more sensitive than it actually is. Worse, when tested on live user data, the model falsely flags benign posts, damaging user trust. The problem wasn’t the model—it was the prompt’s label imbalance and lack of order experimentation.
🗺️ What are the Implications?
• Always include multiple, carefully chosen examples (“few-shot prompting”) when asking questions to AI personas: The paper’s benchmarking found that providing several relevant example responses in the prompt (not just one or zero) leads to significant boosts in survey and test accuracy—performance can shift by 10-20% or more just by adjusting the number and choice of examples shown.
• Pay attention to the order and diversity of examples supplied: Changing the order or type of examples (e.g., all positive vs. a mix of positive and negative) can swing results by up to 30-40%. Don’t just copy-paste the first examples you find—deliberately vary them to match the diversity of your real-world audience.
• Use examples that are similar to the test question or target audience: Selecting examples that closely resemble the scenario or segment you care about (e.g., similar demographics, brand affinity, or purchase context) makes simulated outputs more realistic and predictive for your study’s focus.
• Don’t rely on “default” or “random” prompts—prompt design is as important as model choice: The research shows that simply rewording instructions, changing formatting, or reordering examples can have as much impact as switching to a more advanced AI model. Allocate time for thoughtful prompt design and testing, not just technical setup.
• Test and validate with small-scale pilots before scaling up: Because small changes in prompt content or example selection can produce big differences in results, run small pilot tests with your chosen prompts and examples. Adjust based on early findings to ensure your main study is robust.
• Document and share your prompt setup for transparency and repeatability: Market research buyers and stakeholders should ask to see the exact prompts and examples used in simulations. This transparency allows others to understand, replicate, or challenge the findings and ensures higher confidence in the outcomes.
• Consider ensembling (averaging results from multiple prompt variations): The study finds that running the same question with several different prompt wordings or example sets, then averaging or majority-voting the results, can reduce bias and increase overall accuracy.
📄 Prompts
Prompt Explanation: The AI was instructed to role-play as a persona (role prompting/persona prompting) by assigning a specific role to the GenAI in the prompt, such as pretending to be a particular person or professional, to influence the style or content of the generated output.
Pretend you are a shepherd and write a limerick about llamas.
⏰ When is this relevant?
A financial services company is launching a new budgeting feature in its mobile app. The feature uses AI to auto-categorize spending, suggest savings goals, and gamify progress. Before rollout, the product team wants to simulate how three types of users—first-time budgeters, financially stressed gig workers, and experienced budgeters—might respond to the new feature. They aim to surface excitement, concerns, and feature expectations through synthetic interviews using AI personas.
🔢 Follow the Instructions:
1. Define customer personas: Draft concise but rich descriptions for the three user types:
• First-time budgeter: 24, recent college graduate, salaried job, trying to get better with money, curious but inexperienced with finance apps.
• Gig worker under financial stress: 34, drives for ride-share apps, income varies weekly, anxious about bills, seeks better financial control but skeptical of gimmicks.
• Experienced budgeter: 42, married, two kids, tracks spending in spreadsheets, already uses multiple finance tools, looking for efficiency, not fluff.
2. Prepare prompt template for persona simulation: Use this structure to generate realistic and focused responses:
You are simulating a \[persona description].
Here is the product being tested: “A new budgeting feature that uses AI to automatically categorize your spending, suggest tailored savings goals, and gamify progress with milestones and rewards.”
You are speaking with a product researcher in an interview setting.
Respond as this persona would in 3–5 sentences, honestly and naturally.
First question: What is your initial reaction to this budgeting feature?
3. Generate responses: For each persona, create 5–10 simulated interview responses using slight variations in the initial question (e.g., “Would you find this useful in your day-to-day?”, “Does this sound like something you'd use?”). This provides diversity in tone and insight.
4. Add follow-up interview questions: After the first round of answers, generate 1–2 follow-up questions for each persona thread. Examples:
• “What would make this feature feel more trustworthy or useful to you?”
• “Are there any parts of this that sound confusing or unnecessary?”
• “Would this change how often you use the app?”
5. Thematically tag responses: Review the outputs and tag them using themes like “enthusiastic,” “skeptical,” “privacy concerns,” “needs transparency,” “likes gamification,” “prefers control.” Use these to cluster reactions across personas.
6. Compare reactions across personas: Identify patterns, such as which personas are most excited about automation, who expresses trust concerns, or who desires more manual control. Highlight what messaging would resonate with each and what features might need clarification or refinement.
🤔 What should I expect?
You’ll gain a clear, directional understanding of how different user types emotionally and functionally respond to the proposed feature. This can shape messaging, onboarding design, or feature prioritization. It also surfaces potential objections before launch, letting teams preemptively address concerns and improve user experience across segments.



