Evaluating Persona Prompting for Question Answering Tasks
postCarlos Olea, Holly Tucker, Jessica Phelan, Cameron Pattison, Shen Zhang, Maxwell Lieb, Doug Schmidt, Jules White
Published: 2024-06-01

🔥 Key Takeaway:
The more “collaborative” you make your AI audience—by adding roundtable debates or multi-agent panels—the less accurate and realistic their answers become; single, well-chosen expert personas actually outperform fancy group simulations for open-ended, human-style questions.
🔮 TLDR
This paper tested how different persona-based prompting strategies affect large language model (LLM) performance on over 4,000 question-answering tasks, using both single-agent and multi-agent (roundtable) setups and comparing ChatGPT-3.5-turbo and ChatGPT-4. The main finding is that using auto-generated expert personas for single agents gives a clear accuracy boost on open-ended tasks (like advice, brainstorming, and creative writing), with mean score improvements of 0.3–0.9 over control prompts, especially on high-openness datasets (e.g., finance advice, creative brainstorming); for closed tasks (multiple choice, factual recall), persona use made little or no difference. Multi-agent methods (where several expert personas discuss and revise answers) did not outperform single-agent setups and sometimes introduced more hallucinations unless advanced prompt engineering (like voting or example-based reasoning) was added. The key actionable insights are: (1) use detailed, contextually relevant personas for open-ended or creative tasks to improve LLM output; (2) for multi-agent or ensemble querying, additional engineering (e.g., voting, anti-hallucination checks) is required to see gains; (3) for standard factual or multiple-choice queries, persona prompting is unnecessary. These lessons support tailoring prompt and persona strategies to the openness and complexity of the research question to maximize fidelity in synthetic audience simulations.
📊 Cool Story, Needs a Graph
Figure 2: Score Differences from Control for Each Prompting Style on Datasets with Free Response Answer Keys
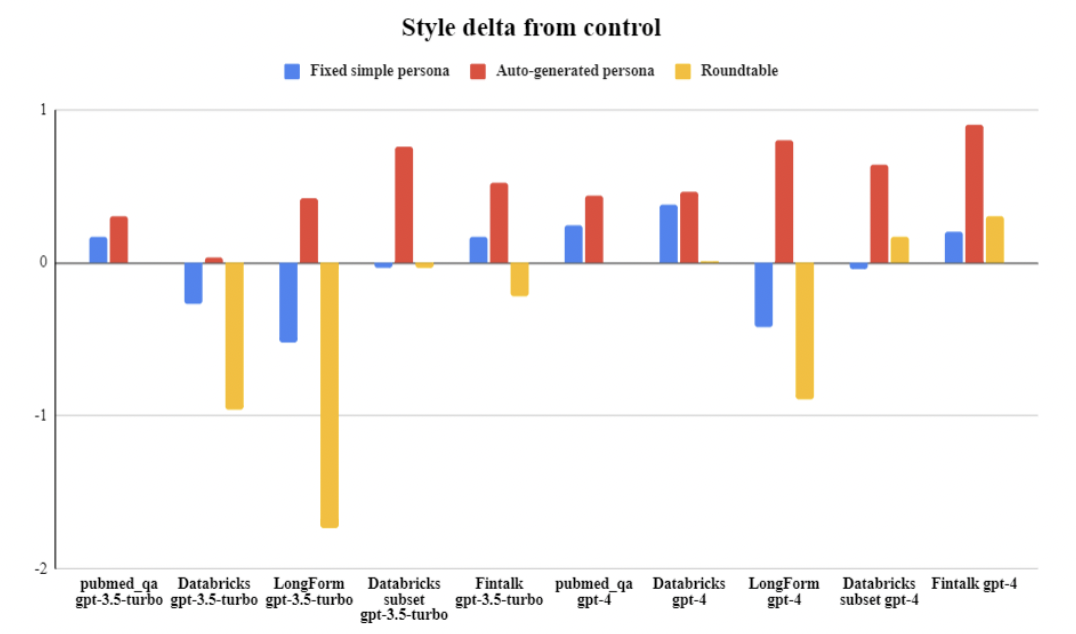
Relative score improvements of each persona prompting method over the control, across all datasets and LLM versions.
Figure 2 presents a grouped bar chart where each bar shows the mean score difference (delta) from the control for three prompting strategies—fixed simple persona, auto-generated persona (the proposed method), and roundtable (multi-agent)—across multiple datasets, with results shown separately for both ChatGPT-3.5-turbo and ChatGPT-4. This single view succinctly highlights which methods outperform the baseline, in which contexts, and to what degree, providing a clear, direct comparison of all strategies and illustrating that auto-generated personas are most beneficial for high-openness tasks, while multi-agent methods sometimes underperform.
⚔️ The Operators Edge
A subtle but crucial detail in this study is that *the biggest performance gains from AI personas happened only when the questions themselves were “open”—with multiple valid answers and room for interpretation—not for factual or tightly constrained prompts.* This “openness” of the question, not just the persona design or AI model, was the real multiplier for accuracy and realism in synthetic responses.
Why it matters: Many practitioners focus on crafting rich personas or picking the best AI, but overlook that the *type of question* you ask is what unlocks the value of persona simulation. When the prompt is too narrow or factual, personas add little; when it’s broad or interpretive, the AI’s ability to channel nuanced, differentiated responses kicks in, making the simulation more useful for market research or creative testing.
Example of use: A marketing strategist running synthetic interviews for a new campaign could deliberately pose open-ended questions to AI personas—like “What concerns would you have about switching brands?” or “Describe how you’d feel if a company changed its packaging”—to surface diverse emotional drivers and barriers, rather than just yes/no or preference checks.
Example of misapplication: A product manager might invest in elaborate persona generation and prompt engineering, but then use those personas on a survey full of simple multiple-choice or factual questions (e.g., “Would you buy this?” “What price point is acceptable?”). The simulation results will look bland and offer little beyond what a direct model or spreadsheet could provide, missing the richer insights that come from letting personas “reason” on open questions.
🗺️ What are the Implications?
• Focus on open-ended, creative, or advice-style questions for synthetic audiences: AI personas demonstrated the most realistic and accurate responses when studies involved brainstorming, storytelling, or advice—making these areas the best candidates for virtual audience testing.
• Use detailed, context-aware personas for each study: Automatically generating an expert persona relevant to each question led to noticeably better results than generic or fixed personas, especially for tasks with many possible answers.
• Don’t expect improvements for basic factual or multiple-choice questions: For straightforward, fact-based queries (like simple product facts or yes/no questions), adding personas did not improve accuracy—conventional survey methods or direct querying may be equally effective.
• Be cautious with multi-persona “roundtable” simulations: Creating panels of AI experts debating a question did not produce better results than single, well-designed personas and sometimes increased mistakes unless carefully engineered.
• Invest effort in prompt design over model selection: The way questions and personas were presented had a bigger impact on output quality than using the newest or most expensive AI model—good prompt engineering yields better value.
• Apply more advanced techniques for complex group simulations: If simulating group decision-making or panels, extra features like voting, step-by-step reasoning, or anti-error checks are needed to avoid “groupthink” or AI hallucinations.
• Validate AI studies with small human samples where possible: While AI personas can provide rapid, scalable feedback, checking a small subset of results with real people helps spot where the simulation might be unrealistic.
📄 Prompts
Prompt Explanation: The AI was given minimal persona and role-play instructions to answer test questions as an expert, either by providing a numbered choice or a brief sentence.
Act as an incredibly intelligent researcher that is an expert at problem solving, common sense reasoning, and strategy. You are taking a test. Provide your answers by responding only with the number of the appropriate answer for the presented question
Act as an incredibly intelligent researcher that is an expert at problem solving, common sense reasoning, and strategy. You are taking a test. Provide your answers by responding with one to two sentences.
Prompt Explanation: The AI was instructed to first generate a detailed expert persona tailored to the question, then role-play as that persona when answering.
persona generator Describe a detailed persona of an expert who would be able to answer the following question including their background and a detailed description of their capabilities and qualifications:[question is inserted here]
You are taking a test. Act as the persona provided and provide your answers by responding only with the number of the appropriate answer for the presented question
You are taking a test. Act as the persona provided and provide your answers by responding with one to two sentences.
Prompt Explanation: The AI was prompted to simulate a multi-agent roundtable, with different step-wise roles for answering, critiquing, revising, and deciding on answers using auto-generated personas.
roundtable admin initial You are taking a test. Provide your answers by responding with the number of the appropriate answer for the presented question as well as your reasoning for choosing it.
roundtable expert You are [insert expert name].You are assisting the administrator in taking a test by offering useful critique and information. Provide feedback on the most recent answer given by the administrator, as well as their reasoning and offer suggested changes if you think the answer is incorrect, as well as your reasoning why. Pay attention to the feedback of any other experts and correct any incorrect information or suggestions. ((Be succinct and only suggest answers that are provided by the question. Do not provide overly long feedback. Do not exceed 1500 characters in your response))
roundtable admin revisor You are taking a test. Revise the previous answer according to the feedback provided by the experts you are collaborating with. ((You are not allowed to change the answers to the question, only the choice of answer you make.))
roundtable admin decider You are taking a test. Decide the best answer given the feedback and revisions that have been made. ((Provide your answers by responding only with the number of the appropriate answer for the presented question.))
roundtable admin decider You are taking a test. Decide the best answer given the feedback and revisions that have been made. ((Provide your answers by responding with one to two sentences.))
persona generator You are an expert at creating useful personas. You create detailed personas of useful experts for answering the questions you are given including their background and a detailed description of their capabilities and qualifications. ((When you return the personas, be sure to separate them with a sequence of two newlines, followed by 5 dashes, followed by two newlines. For example:
Persona description 1
—–
Persona description 2))
⏰ When is this relevant?
A national restaurant chain wants to gauge how three key customer types—family diners, young professionals, and health-focused individuals—would react to a new plant-based menu item. The team wants to simulate customer interviews to compare concerns, motivators, and likely purchase intent using AI personas instead of live focus groups.
🔢 Follow the Instructions:
1. Define audience segments: Write short profiles for each target persona. Example:
• Family diner: 42 years old, two kids, values convenience and kid-friendliness, moderate price sensitivity.
• Young professional: 29, urban, dines out frequently, open to trends, values taste and speed.
• Health-focused individual: 35, fitness enthusiast, reads nutrition labels, values ingredient transparency.
2. Prepare persona prompt template: Use this for each segment:
You are simulating a [insert persona description here].
A new plant-based menu item is being introduced at [Restaurant Name]: ""[Insert menu item description]"".
You are being interviewed by a market researcher.
Respond in 3–5 sentences as this persona—share your honest first impression, what stands out, and how likely you would be to try it.
First question: What is your initial reaction to this new menu item?
3. Run the initial prompt through the AI model: For each persona, generate multiple responses (e.g., 10 per persona) by running the prompt with the same persona description but slightly different wording of the question or context to simulate real interview variety.
4. Ask follow-up questions: Based on each initial response, ask 1–2 follow-ups such as ""Would this menu item change how often you visit our restaurant?"" or ""What concerns or hesitations do you have about plant-based options?""
5. Tag and summarize responses: Review the AI-generated answers and label them with key themes (e.g., ""mentions taste,"" ""concerned about price,"" ""positive toward health benefits,"" ""neutral/negative"").
6. Compare across segments: Summarize which features or concerns are raised most often by each persona group. Look for patterns—such as young professionals mentioning trendiness, families focusing on value or kids’ acceptance, and health-focused diners discussing nutritional content.
🤔 What should I expect?
You'll get a clear, theme-based summary of how each customer type might respond to the plant-based menu item, which benefits or objections are most common, and which group is most likely to drive trial and repeat purchase—helping prioritize messaging, menu placement, and follow-up testing without running a costly or time-consuming human study.



