Scaling Synthetic Data Creation with 1,000,000,000 Personas
postXin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, Dong Yu
Published: 2024-06-28

🔥 Key Takeaway:
The fastest way to make synthetic research more lifelike isn’t to add complexity—it’s to flood your AI study with hundreds or thousands of ultra-simple, single-trait personas; the sheer scale and randomness force the group to behave unpredictably and humanly, while carefully crafted or “balanced” personas actually make the results more predictable and fake.
🔮 TLDR
This paper presents Persona Hub, a system that automatically generates 1 billion diverse AI personas from web data to drive large-scale, highly varied synthetic data creation using LLMs. Instead of relying on limited seed datasets or hand-curated topic lists, the authors show that prompting LLMs with detailed personas—created by mapping web texts to likely readers/writers and then expanding through relationship graphs—can steer the generation of realistic, contextually varied outputs for nearly any data type (math and logic problems, user instructions, knowledge-rich texts, NPCs, tool requirements, etc.). The system’s scale and diversity are validated by deduplication methods and semantic similarity tests, showing that even with highly similar personas, the resulting outputs retain significant diversity. Experiments show that fine-tuning a 7B LLM on Persona Hub–generated math problems enables it to match or surpass the performance of much larger models (e.g., 64.9% on MATH, rivaling GPT-4-turbo-preview), and human review of sampled outputs gave a 96.5% validity rate. Actionable takeaways: using large-scale, automatically derived persona libraries (with both fine-grained and relational expansion), persona-conditioned prompting, and semantic deduplication are effective ways to drive diverse, high-fidelity synthetic market research or simulation; scaling up the number and diversity of personas directly improves the realism and coverage of simulated responses, and similar methodologies can be extended to simulate user behavior, market reactions, or tool needs in new domains. The authors caution that this approach can potentially extract and replicate much of an LLM’s training knowledge, raising ethical and IP concerns.
📊 Cool Story, Needs a Graph
Figure 9: "Accuracy on MATH with scaling the synthetic instances used for training Qwen2-7B"
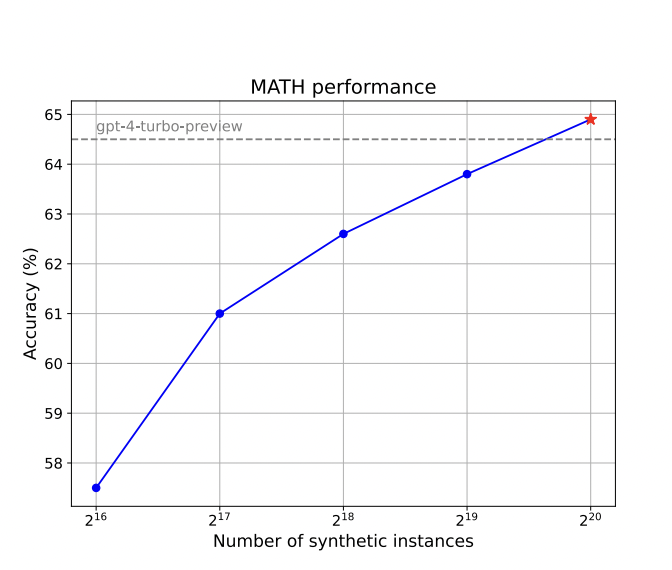
Performance of the persona-driven synthetic data method compared to baselines as training set size increases.
Figure 9 presents a line plot showing the accuracy of the Qwen2-7B model on the MATH benchmark as the number of persona-driven synthetic training instances increases, with a reference line for the performance of the gpt-4-turbo-preview baseline. This figure makes it easy to see how scaling up the proposed method (using more synthetic data generated with diverse personas) leads to improved model performance, eventually matching or surpassing the baseline of much larger or proprietary models. The overlaid comparison allows clear visual assessment of the benefit of the persona-driven approach relative to established baselines as dataset size grows.
⚔️ The Operators Edge
A detail that’s easy to overlook, but fundamental to why this study’s method works so well, is the use of aggressive, two-layer deduplication—first with surface-level MinHash on the persona descriptions, then with semantic embedding similarity—to prune the synthetic persona pool (page 5). This isn’t just about avoiding exact duplicates; it’s about making sure your simulated “crowd” is truly diverse at the level of meaning, not just wording.
Why it matters: Without this deep deduplication, even a massive persona set will quickly fill up with near-clones and trivial variations. That means your “audience” is actually echoing a handful of perspectives, inflating confidence in results and masking blind spots. The semantic step ensures the model samples from genuinely distinct viewpoints, so aggregate responses better reflect the unpredictable, edge-case-heavy nature of real-world groups—giving you robust findings, not just noise or consensus.
Example of use: A fintech company running synthetic A/B tests on a new loan application flow could use this approach to generate several thousand AI personas representing potential applicants. By deduplicating on both text and meaning, they avoid a fake “diversity” that’s just 500 versions of “tech-savvy millennial” with slightly different jobs. As a result, the simulated data reveals unexpected usability blockers for small but critical segments (e.g., non-native speakers, gig workers, retired applicants), prompting design changes before launch.
Example of misapplication: If the same company skips semantic deduplication and only filters out exact text matches, their persona pool ends up dominated by a few archetypes with minor rewording. Their A/B test “proves” the new flow works for everyone, but when it goes live, real users from overlooked backgrounds drop off in droves or find errors no one predicted. The team is blindsided, not because the AI was bad—but because they missed this critical lever for real representativeness.
🗺️ What are the Implications?
• Increase realism by scaling up persona diversity: The study shows that using a large, diverse pool of AI personas—rather than a handful of generic or random profiles—leads to outputs that better match real-world variety and nuance, making synthetic market research results more credible and actionable.
• Ground your personas in real user data and relationships: Automatically building personas from real web content and expanding them through social and professional relationships captures the complexity and interconnectedness found in actual markets, which helps avoid overly simplistic or stereotypical audience models.
• Use “few-shot” prompting to anchor accuracy: Providing a few realistic examples (few-shot prompts) that combine persona details with sample responses boosts the accuracy of simulated answers, especially compared to zero-shot (no example) or generic instruction-based approaches.
• Don’t just randomize—deduplicate and filter for uniqueness: Advanced deduplication (using both text and meaning) ensures each simulated persona adds new perspective, preventing “echo chamber” effects and making simulated survey results more robust.
• Test at scale to unlock emergent group behaviors: Effects like polarization, trend adoption, or group-level insight only appear when simulating hundreds or thousands of personas. Small-scale tests may miss the dynamics that drive real-world market shifts.
• Validate with spot-checks against human data: The approach achieved a 96.5% validity rate when spot-checked by experts. For business use, supplement large-scale synthetic surveys with a handful of human validations to build executive confidence before making decisions.
• Invest in study design over model complexity: The findings show that prompt design, persona detail, and diversity matter more than which specific AI model you use—so focus resources on these areas for the highest ROI.
📄 Prompts
Prompt Explanation: Math-Challenge — chemical-kinetics persona crafts a hard math problem to benchmark zero/few-shot generation.
Create a challenging math problem with the following persona:
a chemical kinetics researcher
Prompt Explanation: Geometry-Crossover — linguist persona embeds social-interaction context into a geometry question.
Create a geometry problem with the following persona:
A linguist with a particular interest in the intersection of language and social interaction
Prompt Explanation: Olympiad-Crossover — linguist persona delivers an Olympiad-grade problem for high-difficulty evaluation.
Create an Olympiad-level math problem with the following persona:
A linguist with a particular interest in the intersection of language and social interaction
Prompt Explanation: Teacher-Guide — high-school instructor persona poses a linear-function + definite-integral exercise in classroom style.
Create a math problem with the following persona:
A high school math teacher is teaching students the concepts of linear functions and definite integrals, helping them understand the relationships between functions and the methods for calculating the area of regions enclosed by curves.
Prompt Explanation: Group-Theory — professor persona designs an advanced subgroups/isomorphisms problem to probe expert depth.
Create a math problem with the following persona:
A mathematics professor who specializes in the study of group theory, particularly the concepts and theorems related to subgroups and isomorphisms. His research interests include, but are not limited to, the structure of finite groups, representation theory of groups, isomorphism problems, and the theory of group automorphisms.
Prompt Explanation: Logic-Play — golfer-philanthropist persona frames a sports-flavored logical-reasoning puzzle.
Create a logical reasoning problem with the following persona
An enthusiastic amateur golfer who is passionate about combining sports with philanthropic causes.
Prompt Explanation: Spatial-Impact — senior engineer persona builds a spatial-reasoning task that highlights algorithmic social effects.
Create a spatial reasoning problem with the following persona
A senior software engineer who encourages the undergraduate to consider the social impact of their algorithms
Prompt Explanation: Ruozhiba-Series — diverse personas spin whimsical, language-dense logic puzzles in Ruozhiba format.
Create a Ruozhiba-style logical reasoning problem with the following persona
An IT consultant specializing in network configuration
Create a Ruozhiba-style logical reasoning problem with the following persona
A local business owner interested in economic trends
Create a Ruozhiba-style logical reasoning problem with the following persona
A soccer fan who believes in toughing it out rather than making excuses
Create a Ruozhiba-style logical reasoning problem with the following persona
A cynical musician interested in the business side of music streaming
Prompt Explanation: Prompt-Inference — predicts the instruction a given persona would request using zero/few-shot cues.
You are a helpful assistant. Guess a prompt (i.e., instruction) that the following persona may ask you to do:
{persona}
You are a helpful assistant.
===Example 1===
Persona: A curious and analytical individual, likely with a background in mathematics or science, who enjoys exploring intriguing ""what if"" scenarios and is fascinated by the intersection of population demographics and geography.
Prompt: Is it possible for the global population to stand on Jeju Island?
===Example 2===
Persona: An astronomy enthusiast or a professional astronomer, likely with a strong interest in peculiar galaxy structures and a good understanding of celestial objects, seeking to gather specific information about the unique Hoag's object galaxy.
Prompt: Name the actual galaxy inside Hoag's object galaxy
———
Your task: Guess a prompt (i.e., instruction) that the following person may ask you to do: {persona}
Prompt Explanation: Knowledge-Article — horticulturist persona writes a Quora post on drought-resistant Australian flora.
Assume you are the persona described as follows. Write a Quora article using your knowledge, skills, experience, or insights.
A horticulturist interested in native Australian flora, exploring the introduction and cultivation of drought-resistant plants in arid and semi-arid landscapes
Prompt Explanation: NPC-Mapping — projects real-world personas into MMO lore to create lore-consistent NPCs.
Above is the introduction and background story of the game ""World of Warcraft (WoW)"".
Your task is to consider what NPC the following persona will become after they come to the world of WoW:
A nomadic photographer capturing the beauty of different cities, inspired by the diary writer's poetic musings
Above is the introduction and background story of the game ""MOONLIGHT BLADE"".
Your task is to consider what NPC the following persona will become after they come to the world of MOONLIGHT BLADE:
An avant-garde painter who experiments with unconventional materials and techniques
Prompt Explanation: Tool-Spec — drafts an interface enabling a Philippine cab-driver persona to access tasks beyond LLM reach.
Develop a tool (i.e., a high-level interface) for the given persona to help them access complex functionalities that an LLM struggles with.
As the first step, you only need to define the tool (i.e., interface).
A cab driver who frequently drives along N82 in the Philippines
⏰ When is this relevant?
A consumer electronics company wants to test reactions to a new smart home voice assistant, targeting three key customer segments: tech-savvy singles, busy families, and privacy-conscious seniors. The team wants to use AI personas to simulate in-depth user interviews, aiming to identify which features or concerns dominate for each segment and guide product messaging before launch.
🔢 Follow the Instructions:
1. Define customer segments and create AI personas: Build three concise persona profiles, each reflecting a real-world segment. For example:
• Tech-savvy single: 31, city apartment, early adopter, automates home, values integrations, little concern for privacy.
• Busy family: Parent, 42, two children, suburban home, values convenience, wants routines for kids, some tech friction.
• Privacy-conscious senior: 68, retired teacher, lives alone, cautious with new devices, values security and simplicity.
2. Prepare the product concept and prompt template: Draft a clear product description and an interview prompt. Example template:
You are [persona description].
Here is the new product: ""HomeGenie is a smart voice assistant that controls lights, appliances, and security, answers questions, and learns your routines. It offers voice recognition for each household member and can connect with most smart home devices. All data is processed in the cloud by default, but users can activate a local-only privacy mode. Price: $149.""
You are taking part in a market research interview. Please answer in 3–5 sentences, staying in character.
First question: What is your honest first reaction to HomeGenie? What do you like or dislike?
3. Run the prompts for each persona: For each segment, generate 5–10 responses to the initial question, varying the wording slightly (e.g., ""How do you imagine using HomeGenie in daily life?"" or ""What would make you consider or avoid this product?"").
4. Add follow-up questions: Based on initial answers, ask targeted follow-ups (e.g., ""Would the privacy mode influence your willingness to use HomeGenie?"" or ""What feature would make it a must-have for your household?""). For each persona, generate a threaded Q&A with 2–3 turns.
5. Tag and summarize response themes: Review all responses and tag key themes (e.g., ""mentions security concern,"" ""enthusiastic about automation,"" ""price worry,"" ""asks about compatibility,"" ""mentions distrust of cloud"").
6. Compare across segments: Summarize which features, objections, or selling points matter most to each segment. Note which segment is most positive, which raises objections, and what language or product tweaks might improve appeal.



