Quantifying the Persona Effect in Llm Simulations
postTiancheng Hu, Nigel Collier
Published: 2024-08-11

🔥 Key Takeaway:
The more you try to engineer realism in synthetic audiences by piling on detailed persona traits, the less it actually matters—most of the time, these demographic details barely move the needle, and your simulation will be just as accurate (or inaccurate) if you keep it simple and focus on the scenarios where real people genuinely disagree.
🔮 TLDR
This study finds that adding persona variables (like demographics, attitudes, behaviors) to LLM prompts only explains a small fraction (<10%) of the variation seen in how real humans annotate subjective NLP tasks (like rating toxicity or sentiment), with most variance attributed to the content itself or unexplained factors. Including persona information in prompts gives statistically significant but modest improvements in LLM simulation accuracy, especially in cases where human annotators disagree, but only within a narrow range (high entropy-low standard deviation). The benefit of persona prompting is directly proportional to how much persona variables actually influence the real outcome; in datasets where personas matter more (like certain political surveys), LLMs with persona prompting can capture up to 81% of explainable variance, but for most real-world tasks, gains are minimal. The main actionable recommendations are: (1) don't assume persona prompting will yield highly realistic simulations unless you've validated that persona variables explain a meaningful amount of human response variance in your context; (2) for better simulation fidelity, collect richer and more targeted persona data (not just basic demographics); (3) use regression analysis on available human data to estimate in advance whether persona conditioning is likely to help before scaling up simulation runs.
📊 Cool Story, Needs a Graph
Figure 2: "Mean improvement in MAE with persona prompting across four 70b models in annotations characterized by low/high entropy and standard deviation, with darker colors denoting more substantial improvement in predictions."
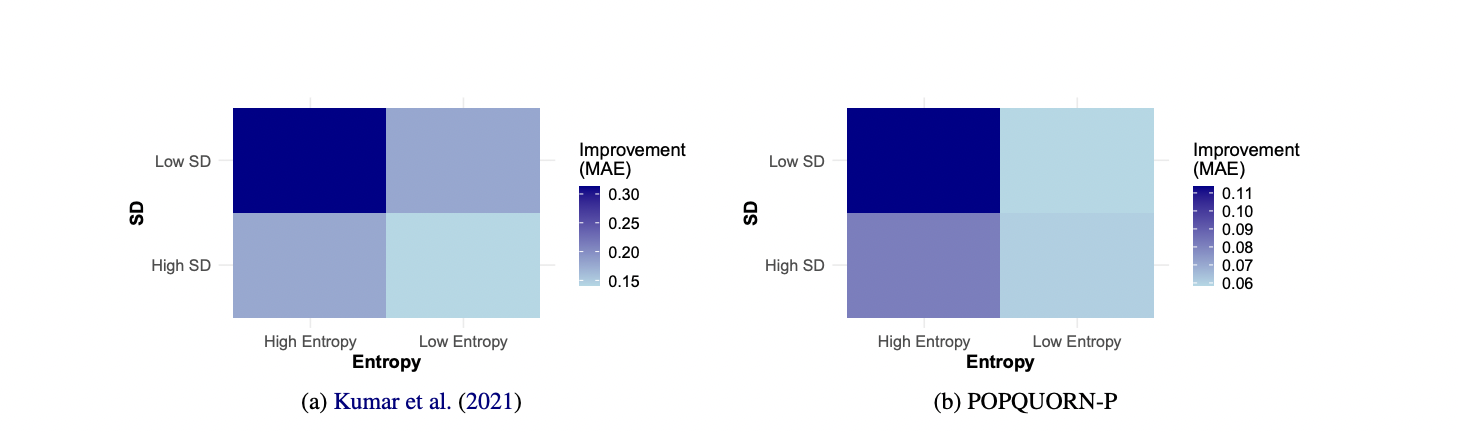
Persona prompting yields the greatest predictive improvement in high-entropy, low-standard deviation cases across all models.
Figure 2 presents two heatmaps (for two different datasets) showing the mean reduction in mean absolute error (MAE) achieved by persona prompting compared to the baseline (no persona) for four 70b-scale LLMs, across four types of annotation samples classified by entropy and standard deviation. Each cell's color intensity reflects the magnitude of improvement for a model/sample-type pair, allowing a direct, at-a-glance comparison of the benefit of persona prompting versus the baseline for each model and scenario. This visual clearly demonstrates that the improvement from persona prompting is most pronounced for samples where annotators disagree frequently but within a narrow range (high entropy, low SD), and that the effect is consistent across all tested advanced models.
⚔️ The Operators Edge
A detail that even experts might overlook is how the study isolates the effect of persona variables from the effect of the text itself by using mixed-effect linear regression with random intercepts for each text sample (see page 3–4 and Table 1). In plain English: the researchers didn’t just compare whether AI personas matched humans—they controlled for the fact that some survey questions or content pieces naturally provoke more disagreement, so any measured effect from persona variables is really about the persona, not just the context.
Why it matters: This approach is crucial because in synthetic research, it’s easy to conflate “personality-driven” disagreement with “content-driven” disagreement. By statistically separating these, you can see whether adding persona actually explains how people differ, or if the question itself is just polarizing. Without this, you might mistakenly attribute disagreement to your synthetic personas when it’s really caused by the underlying topic or scenario.
Example of use: Imagine a brand testing several ad slogans with synthetic personas. If you apply this study’s approach, you’d analyze which reactions are truly driven by persona traits (e.g., eco-conscious vs. price-sensitive) versus which slogans are simply divisive regardless of audience. This lets you refine your persona targeting and messaging strategy more precisely, knowing where audience segmentation genuinely matters.
Example of misapplication: A product team runs AI persona simulations for new feature ideas but skips controlling for the inherent divisiveness of each feature. They see lots of disagreement and assume their persona design is capturing nuanced human diversity—when actually, the disagreement is just because some features are controversial for everyone. As a result, they overestimate the value of synthetic segmentation and might make misleading claims about audience targeting, potentially wasting resources on false insights.
🗺️ What are the Implications?
• Don’t over-rely on AI personas to explain real customer differences: The study finds that adding demographic or behavioral details to AI personas only explains a small part of how real people respond in most survey or feedback settings, so simulated audiences can miss important real-world variation.
• Use persona prompts mainly for “gray area” questions, not black-and-white ones: AI personas offer the most value in situations where real people disagree, but only by a little (e.g., questions with subtle emotional or subjective elements, not strictly factual or obvious ones).
• Validate with pilot human data before scaling up: Before investing heavily in synthetic market research, run a small human study to check if demographic or persona factors actually influence responses for your topic; if they don’t, AI persona conditioning is unlikely to add much accuracy.
• Collect richer persona data if realism is critical: If your business case truly depends on simulating different types of people, go beyond basic demographics—adding attitudes, experiences, or beliefs can make simulations more lifelike, but this takes extra effort and planning.
• Be cautious with small predicted effects: Even with advanced AI and detailed prompts, improvements in accuracy tend to be modest; don’t expect persona-based simulations to deliver highly precise forecasts without ongoing validation.
• Prioritize sample diversity and question design over technical tweaks: The way you choose your sample and craft your survey questions has a bigger impact on result quality than which AI model or prompting technique you use.
• Use simulations to explore broad scenarios, not fine-grained predictions: These tools are best for exploring general trends or “what-if” scenarios, not for making confident, group-specific forecasts or decisions that require high-fidelity segmentation.
📄 Prompts
Prompt Explanation: Annotation Baseline — prepends persona profile, then elicits a one-token offensiveness rating via multiple-choice.
**Your Profile**: You race/ethnicity is %s. Your gender identity is %s. You are %s years old. In terms of your political orientation, on a five-point Likert scale of -1 (Strongly liberal) to 1 (Strongly conservative), you are %s.
**Question**: How toxic/hateful/disrespectful or offensive does this post seem to you? (Note: The purpose is to understand how disrespect/offense can show up in language, not making statements about the actual content of the posts.) ""%s""
(A) not offensive at all
(B) mildly inappropriate
(C) somewhat offensive
(D) moderately offensive
(E) very offensive
**Answer**: (
Prompt Explanation: Rich-Persona Stress-Test — answers a toxicity scale after loading an extensive demographic-behavior profile.
**Your Profile**: You race is %s. Your gender is %s. You %s describe yourself as transgender. You consider yourself to be %s. You are %s years old. The highest degree or level of school that you have completed is %s. Religion is %s in your life. Generally speaking, you consider yourself politically %s. You %s a parent. You %s use social networking sites (Facebook, Twitter). You %s use video sites (YouTube, Twitch). You %s use news sites (CNN, Fox, NYT, WSJ). You %s use community forums (Reddit, Craigslist, 4chan). In general, you rate the impact of technology on peoples lives as %s. Based on your experience, toxic posts or comments are %s.
**Question**: How toxic do you personally find this comment? ""%s""
(A) Extremely toxic
(B) Very toxic
(C) Moderately toxic
(D) Slightly toxic
(E) Not at all toxic
**Answer**: (
Prompt Explanation: Irony Calibration — persona annotator labels replies as ironic/not after definition-based examples.
**Your Profile**: You ethnicity is %s. Your gender is %s. You are %s years old. Your country of birth is %s. Your country of residence is %s. You are a national of %s. You %s a student. You are %s.
Irony is a figurative language device that conveys the opposite of literal meaning, profiling intentionally a secondary or extended meaning.
For instance,
message: ""if ur homeless u probably wouldn’t have a phone.""
reply: ""Yes, and all your belongings would be in a handkerchief tied at the end of a stick."" --> irony: yes
message: ""if ur homeless u probably wouldn’t have a phone.""
reply: ""Yes, you’re right.""--> irony: yes
**Question**: Is the reply ironic in the following message and reply pair?
message: ""%s""
reply: ""%s""
(A) Ironic
(B) Not ironic
**Answer**: (
Prompt Explanation: Workplace Politeness — employee persona scores email civility on a 5-point scale.
**Your Profile**: In terms of race or ethnicity, you are %s. You are a %s. You are %s years old. Occupation-wise, you are %s. Your education level is %s.
**Question**: Consider you read this email from a colleague, how polite do you think it is?
**Email:**: ""%s""
(A) not polite at all
(B) barely polite
(C) somewhat polite
(D) moderately polite
(E) very polite
**Answer**: (
Prompt Explanation: 2012 Opinion-Poll (full) — retro respondent with ideology, emotion, and religion fields answers U.S. survey items.
**It is 2012. Your Profile**: Racially, you are %s. You are a %s. You are %s years old. Ideologically, you are %s. Politically, you are %s. It makes you feel %s when you see the American flag flying. You %s attend church. You are %s interested in politics and public affairs.
Prompt Explanation: 2012 Opinion-Poll (lean) — retro respondent sans ideology fields answers U.S. survey items.
**It is 2012. Your Profile**: Racially, you are %s. You are a %s. You are %s years old. It makes you feel %s when you see the American flag flying. You %s attend church. You are %s interested in politics and public affairs.
⏰ When is this relevant?
A food delivery app wants to understand how three customer types—urban young professionals, suburban families, and retired empty-nesters—would react to a new feature that automatically suggests healthy meal swaps. The business team wants to simulate qualitative feedback interviews to see which value propositions resonate and what objections or interests emerge in each group.
🔢 Follow the Instructions:
1. Define customer segments and personas: Write simple profiles for each type, capturing key attributes:
• Urban young professional: 29, lives in a city, values convenience and health, tech-savvy, typically orders lunch at work.
• Suburban family: 40, married with two kids, lives in suburbs, budgets for family meals, values ease and variety.
• Retired empty-nester: 68, retired, lives with spouse, cooks at home often but orders for variety or when guests visit.
2. Prepare prompt template for AI persona simulation: Use this structure for each simulated customer:
You are a [persona description].
The delivery app you use is now testing a new feature: ""Smart Swaps""—it automatically suggests healthier alternatives for your usual orders, like swapping fries for a side salad or a soda for flavored water, at no extra charge.
A market researcher is interviewing you about your honest reaction to this feature.
Respond in 3–5 sentences, staying in character and giving your natural response.
First question: What is your first impression of the ""Smart Swaps"" feature?
3. Generate simulated responses: For each persona, run the above prompt through your preferred AI model (such as GPT-4, Claude, or Llama-3), generating 5–10 responses per persona to reflect a range of opinions.
4. Ask follow-up questions: Take a sample of each persona's initial responses and prompt again with follow-ups, such as:
- Would you be more or less likely to use the app because of this feature? Why?
- What concerns or hesitations do you have, if any?
- How would you like to control or customize these suggestions?
5. Tag and group responses: Review all outputs and tag themes like ""welcomes health focus,"" ""prefers control,"" ""concerned about taste,"" or ""worried about change.""
6. Compare feedback across personas: Summarize which benefits or objections are common or unique to each segment (e.g., young professionals mention ""time-saving,"" families mention ""kids’ preferences,"" retirees note ""set in habits"").
🤔 What should I expect?
You'll get a clear, organized view of how each customer type reacts to the new feature, what messaging might drive adoption, and what barriers or fine-tuning are needed to make the launch successful. This will help your team prioritize communication strategies and identify which segments to target for pilot programs or further research.



