Virtual Personas for Language Models Via an Anthology of Backstories
postSuhong Moon, Marwa Abdulhai, Minwoo Kang, Joseph Suh, Widyadewi Soedarmadji, Eran Kohen Behar, David M. Chan
Published: 2024-11-01

🔥 Key Takeaway:
The more “real” and nuanced you make your AI personas—with long, natural backstories and authentic quirks—the less control you have over their demographics and diversity, so you actually need a careful matching process and lots of sampling to avoid ending up with a synthetic audience that’s wildly unlike your real customers.
🔮 TLDR
This paper introduces Anthology, a method for generating virtual personas for large language models (LLMs) by conditioning them on open-ended, LLM-generated life backstories. Compared to prior approaches using demographic lists or short bios, conditioning LLMs with detailed backstories matched to target demographic distributions led to up to 18% better alignment with real human survey response distributions and 27% higher consistency across three nationally representative Pew Research Center surveys. The process involves (1) generating thousands of diverse backstories with LLMs, (2) estimating each backstory’s likely demographics via follow-up polling, (3) selecting a subset of backstories to match the real population, and (4) running surveys using these personas. Anthology consistently outperformed existing persona-conditioning techniques (bios, QA lists, or demographics-primed stories) in matching both overall and subgroup (race, age, education, gender) human responses, especially for underrepresented groups. The study also found that random or poorly matched persona selection degraded realism by 18-27% and that relying on fine-tuned LLMs (e.g., RLHF/chat models) hurt diversity and realism compared to using base models. The code and a set of 10,000+ synthetic backstories are made available. Actionable takeaways: use open-ended, naturalistic LLM-generated backstories as context when conditioning AI personas; match persona demographics to the real population using probabilistic survey-based assignment; avoid relying on overly fine-tuned LLMs for diversity; and sample enough backstories to cover demographic variety for more accurate synthetic survey or market research.
📊 Cool Story, Needs a Graph
Table 1
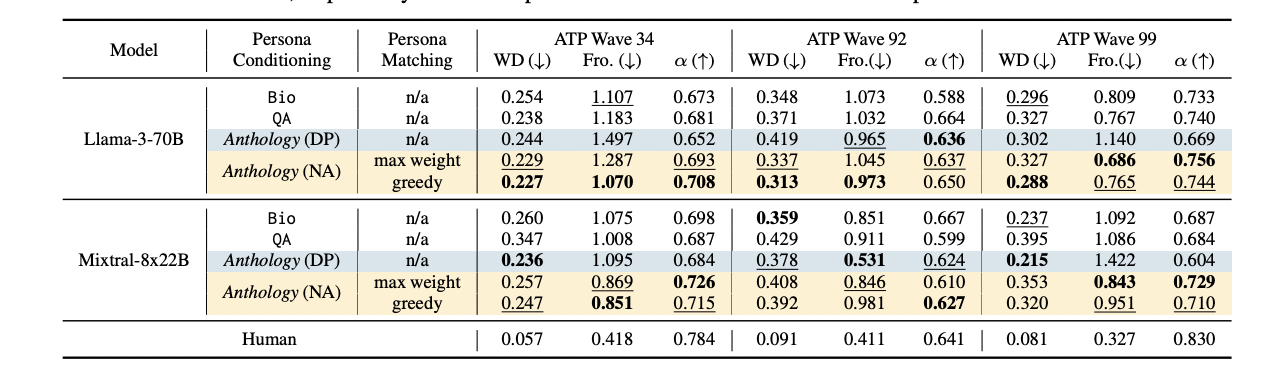
Head-to-head comparison of Anthology and baseline persona-conditioning methods across three surveys and metrics.
Table 1 presents a comprehensive side-by-side comparison of all persona conditioning approaches (Bio, QA, Demographics-Primed Anthology, and Natural Anthology with both max weight and greedy matching), evaluated using two LLMs (Llama-3-70B and Mixtral-8x22B) across three real-world Pew Research Center survey datasets. For each method and survey, the table reports three metrics: Wasserstein distance (distributional match), Frobenius norm (consistency), and Cronbach’s alpha (internal consistency), with human results as the baseline. This layout enables visual identification of the best-performing method and model for each scenario, highlighting the superiority of natural Anthology with greedy matching and the relative gap to both human results and other baselines.
⚔️ The Operators Edge
A detail that most experts might overlook is how the study handles the demographic matching of AI-generated backstories: instead of assuming the LLM will naturally produce a balanced or representative set of personas, the researchers explicitly measure and adjust the demographic distribution of their synthetic audience using a probabilistic matching algorithm. They show (in Table 6, page 34 and method sections) that left unchecked, LLM-generated personas skew heavily young, male, and highly educated—a distribution far from the real population. To counteract this, they estimate the demographic profile of each backstory (sometimes by repeated polling), then select a subset whose combined demographic probabilities best match the actual target (using optimization techniques). This careful curation—not just prompt engineering—is what lets the synthetic results align closely to real-world survey outcomes.
Why it matters: The effectiveness of synthetic research doesn’t hinge just on the creativity or realism of the AI personas, but on statistical representativeness. If you skip demographic adjustment, your simulated audience can be wildly biased without you realizing it, and your results will miss or misrepresent key subgroups. The hidden lever is treating persona composition as a data matching and sampling problem, not just a prompt design challenge.
Example of use: Suppose a CPG company wants to use AI personas to forecast reactions to a new snack among U.S. adults. Instead of generating 1,000 random backstories and running the test, they first classify each persona’s likely age, gender, income, and ethnicity, then sample and weight their “panel” so the aggregate matches U.S. Census targets. This way, when they see that Latinx parents or seniors have a unique response to the product, they can trust it’s not an artifact of model bias but a meaningful signal.
Example of misapplication: A SaaS product team, eager to run quick AI-based user research, generates a batch of “customer” backstories by prompting “Tell me about yourself” and proceeds straight to concept testing. Because the LLM’s default output is overrepresented by young, urban, tech-savvy males, the feedback skews optimistic and misses key pain points for older, less technical, or rural users. The team thinks their feature is a hit, but launch results are disappointing—because they ignored the need to actively sample and match their synthetic audience to the real user base.
🗺️ What are the Implications?
• Use rich, story-like personas instead of basic bios or demographic lists: Market research simulations are more accurate when virtual participants are created using detailed, open-ended life stories (backstories), not just lists of traits or canned bios. This approach led to up to 18% closer alignment with real-world survey results.
• Match your synthetic audience to your real target market: Don’t just generate a random mix of personas—use actual demographic data (from census or past studies) and select or sample AI personas to match the real population. Skipping this step reduced accuracy by as much as 27%.
• Don’t rely on chat-tuned or “helpful” AI models for diversity: The study found that models fine-tuned to be conversational or helpful (like most advanced chatbots) actually produced less realistic and less diverse simulated responses. Use base models and focus on your prompt design instead.
• Test your simulated results against real survey data when possible: Validating your synthetic market research against even a small sample of actual customer responses helps you catch blind spots and calibrate your virtual audience for future runs.
• Include enough personas to capture real-world variety: Accuracy improves when your simulated audience covers the full spectrum of customer backgrounds and experiences, not just a handful of “average” people. Use tools or techniques that generate and filter hundreds or thousands of distinct backstories.
• Personalization works best when it feels authentic: The most realistic AI personas responded more like real people when prompted with authentic, narrative-style backgrounds. For brand tests, ads, or concept feedback, this “human touch” in your virtual audience makes insights more trustworthy for business decisions.
• Quick wins: You don’t need to overhaul everything to benefit: Even swapping out simple bios or random attributes for richer, story-based personas and matching to your market’s real demographics can noticeably improve the value of your market research experiments—no major technical overhaul required.
📄 Prompts
Prompt Explanation: The AI was prompted to generate a virtual persona backstory using an open-ended, naturalistic instruction with no demographic constraints or imposed format.
Question:
Tell me about yourself. How old are you? Where did you
grow up? What events made you who you are? What
matters to you and what do you enjoy?
Answer:
Prompt Explanation: The AI was prompted to generate a backstory for a persona by first specifying answers to a fixed set of multiple-choice demographic questions, then expanding with a detailed narrative.
Below you will be asked to complete some demographic
questions, and then answer a question.
Question: What is your gender?
(A) Male
(B) Female
Answer with (A), or (B).
Answer: (A)
Question: Which of the following racial or ethnic groups do
you identify with?
(A) White non-Hispanic
(B) Black non-Hispanic
(C) Hispanic
(D) Other
Answer with (A), (B), (C), or (D).
Answer: (A)
Question: What is your age?
(A) 18-29
(B) 30-49
(C) 50-64
(D) 65+
Answer with (A), (B), (C), or (D).
Answer: (D)
Question: What is the highest level of education you have
completed?
(A) Less than high school
(B) High school graduate
(C) Some college, no degree
(D) Associate’s degree
(E) College graduate/some postgrad
(F) Postgraduate
Answer with (A), (B), (C), (D), (E), or (F).
Answer: (F)
Question: What is your annual household income?
(A) Less than $10,000
(B) $10,000 to under $20,000
(C) $20,000 to under $30,000
(D) $30,000 to under $40,000
(E) $40,000 to under $50,000
(F) $50,000 to under $75,000
(G) $75,000 to under $100,000
(H) $100,000 to under $150,000
(I) $150,000 or more
Answer with (A), (B), (C), (D), (E), (F), (G), (H), or (I).
Answer: (B)
Question: Tell me about yourself. Please describe in detail.
Answer:
Prompt Explanation: The AI was directed to use a concise, first-person demographic statement as context before prompting for a detailed persona backstory.
Below you will be asked to provide a short description of
your demographic information, and then answer a question.
Description: My annual income is $100,000 to under
$150,000. I consider my gender as male. I consider my race
as White non-Hispanic. My highest level of education is
postgraduate. My age is 30-49.
Question: Tell me about yourself. Please describe in detail.
Prompt Explanation: The AI was prompted to generate a detailed backstory for a specified persona using a biography-style demographic summary as the initial context.
Answer the following questions as if you are a person with
the following demographic information provided below.
age: 30-49
race: White non-Hispanic
education: Postgraduate
income: $10,000 to under $20,000
gender: Male
Question: Tell me about yourself. Please describe in detail.
Prompt Explanation: The AI was guided to simulate a persona by producing a free-text biography based on a randomized order of demographic traits, followed by survey-style questions.
Below you will be asked to provide a short description of your demographic information, and then answer some questions.
Description: I consider my race as White non-Hispanic. My highest level of education is some college, no degree. My age is
65+. My annual income is $30,000 to under $40,000. I consider my gender to be male.
Question: What is your age?
(A) 18-29
(B) 30-49
(C) 50-64
(D) 65+
Answer with (A), (B), (C), or (D).
Answer: (D)
Question: What is your gender?
(A) Male
(B) Female
(C) Other
Answer with (A), (B), or (C).
Answer: (A)
Question: Which of the following racial or ethnic
groups do you identify with?
(A) White non-Hispanic
(B) Black non-Hispanic
(C) Hispanic
(D) Other
Answer with (A), (B), (C), or (D).
Answer: (A)
Prompt Explanation: The AI was prompted to perform a demographic survey on a virtual persona, asking a series of fixed multiple-choice questions to elicit or estimate demographic traits for subsequent persona matching.
Question: What is your gender?
(A) Male
(B) Female
(C) Other (e.g., non-binary, trans)
(D) Prefer not to answer
Answer with (A), (B), (C), or (D).
Answer:
Question: What is the highest level of education you have
completed?
(A) Less than high school
(B) High school graduate or equivalent (e.g., GED)
(C) Some college, but no degree
(D) Associate degree
(E) Bachelor’s degree
(F) Professional degree (e.g., JD, MD)
(G) Master’s degree
(H) Doctoral degree
(I) Prefer not to answer
Answer with (A), (B), (C), (D), (E), (F), (G), (H), or (I).
Answer:
Question: What is your annual household income?
(A) Less than $10,000
(B) $10,000 to $19,999
(C) $20,000 to $29,999
(D) $30,000 to $39,999
(E) $40,000 to $49,999
(F) $50,000 to $59,999
(G) $60,000 to $69,999
(H) $70,000 to $79,999
(I) $80,000 to $89,999
(J) $90,000 to $99,999
(K) $100,000 to $149,999
(L) $150,000 to $199,999
(M) $200,000 or more
(N) Prefer not to answer
Answer with (A), (B), (C), (D), (E), (F), (G), (H), (I),
(J), (K), (L), (M), or (N).
Answer:
Question: Which of the following racial or ethnic groups do
you identify with?
(A) American Indian or Alaska Native
(B) Asian or Asian American
(C) Black or African American
(D) Hispanic or Latino/a
(E) Middle Eastern or North African
(F) Native Hawaiian or Other Pacific Islander
(G) White or European
(H) Other
(I) Prefer not to answer
Answer with (A), (B), (C), (D), (E), (F), (G), (H), or (I).
Answer:
Question: What is your age?
(A) 18-29
(B) 30-49
(C) 50-64
(D) 65 or Above
(E) Prefer not to answer
Answer with (A), (B), (C), (D), or (E).
Answer:
⏰ When is this relevant?
A consumer electronics company is preparing to launch a new smart home speaker and wants early feedback on marketing messages and product features from three types of customers: tech-savvy singles, value-focused families, and privacy-conscious seniors. The goal is to simulate realistic customer interviews using AI personas that match key segments and compare their reactions before investing in a full-scale product launch.
🔢 Follow the Instructions:
1. Define your audience segments: Write short, realistic descriptions for each target group, including details like age, living situation, attitudes, and shopping habits. Example:
• Tech-savvy single: 27, urban apartment, early adopter, streams music daily, values innovation.
• Value-focused family: 42, suburban, two school-aged kids, shops for deals, wants products that benefit the whole household.
• Privacy-conscious senior: 68, retired, lives alone, skeptical of new tech, concerned about data sharing.
2. Generate a backstory for each persona: For each segment, use an AI prompt like:
""Tell me about yourself. Where do you live, what’s your daily routine like, and what matters to you when shopping for home technology?""
Keep a few sentences of the AI’s response as the persona’s “backstory” to use in follow-ups.
3. Prepare the interview prompt template: Use a template that combines the persona’s backstory with the product concept:
You are [persona description].
Here’s a new product concept: ""The HomeSmart Speaker is a voice-controlled device that plays music, answers questions, controls smart devices, and helps you manage daily tasks. It offers customizable privacy settings and family-friendly features.""
As a potential customer, please answer in a natural, conversational way:
— What is your first reaction to this product?
— What would make you want to try or avoid it?
Respond as yourself, in 3–5 sentences.
4. Run the prompts through your AI model: For each persona, run the interview prompt 5–10 times, allowing the model to generate slightly different responses (by rewording the question, varying the tone, or changing one detail in the backstory).
5. Add follow-up questions: Based on initial answers, ask 1–2 deeper or clarifying questions (e.g., ""Would the customizable privacy settings make you more likely to trust the speaker? Why or why not?"" or ""Which feature best fits your household’s needs?""). Have the AI continue the conversation as the same persona.
6. Categorize and summarize feedback: Review the simulated interview transcripts. Tag responses with themes like ""enthusiastic about convenience,"" ""worried about privacy,"" or ""interested in price/value."" Note any common objections, standout phrases, or emotional reactions by segment.
7. Compare across segments: Create a short summary for each customer type, highlighting what messaging or features resonate most, what concerns come up, and any big differences between groups.
🤔 What should I expect?
You’ll get a clear, directional sense of how each customer segment perceives the new smart speaker, what drives their interest or hesitation, and which marketing angles are most promising. This allows you to quickly refine your messaging, prioritize product features, and decide whether to invest in further development or human testing before launch.



