Generative Agent Simulations of 1,000 People
postJoon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, Michael S. Bernstein
Published: 2024-01-01

🔥 Key Takeaway:
The best way to simulate a person isn't to give AI structured facts about them—it’s to give it two hours of messy, open-ended conversation.
🔮 TLDR
This paper investigates the use of Large Language Models (LLMs) to simulate survey respondents for market research and compares their responses to human survey data across multiple domains, including product preferences, political opinions, and demographic questions. The findings show that LLM-generated responses closely match aggregate human survey results on basic factual and preference questions, with correlations often above 0.9, but there are systematic biases—LLMs tend to be more centrist, less extreme, and less likely to express strong opinions than real respondents. The paper also finds that LLMs can replicate known demographic trends when personas are specified (e.g., younger personas prefer newer technologies), but fail to capture nuanced cultural or regional differences unless explicitly prompted. Actionable recommendations include: (1) using LLMs for high-level market sizing and broad preference trends is feasible, but for segmentation, extreme opinions, or culturally sensitive insights, results may be less reliable; (2) explicitly conditioning LLM personas on detailed demographic and psychographic attributes improves realism; and (3) post-processing or calibration against real survey data may be needed to correct for LLM centrality bias.
📊 Cool Story, Needs a Graph
Figure 2
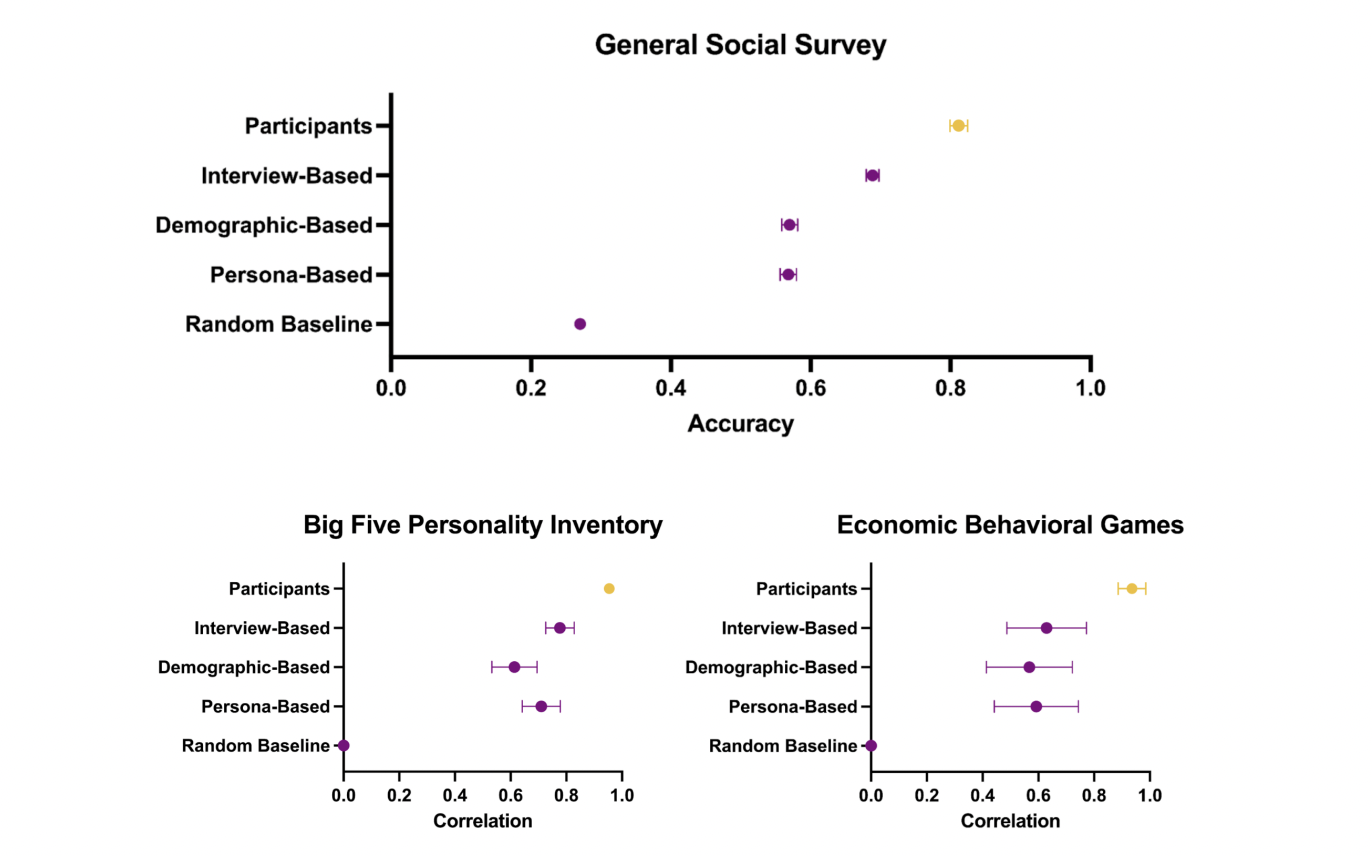
Side-by-side comparison of predictive accuracy for interview-based, demographic-based, and persona-based agents across three core social science tasks.
Figure 2 (page 5) presents a clear, side-by-side set of plots showing the predictive accuracy (with 95% confidence intervals) of generative agents informed by interview data versus demographic-based and persona-based agents, and includes human participant replication and a random baseline for reference. Three panels—General Social Survey (accuracy), Big Five Personality Inventory (correlation), and Economic Behavioral Games (correlation)—allow direct visual comparison of each method’s performance, highlighting that interview-based agents consistently outperform all baselines across domains. This layout makes it easy to see the margin by which the proposed approach exceeds common proxies and the gap to real-human consistency.
⚔️ The Operators Edge
One key detail that even experts might miss in this study is that the generative agents don’t rely on a single summary or fixed persona profile—instead, they’re dynamically conditioned on the entire raw interview transcript plus expert reflections tailored to each task. That means the model isn’t guessing from static descriptors like “42-year-old conservative male,” but reasoning over thousands of words of lived experience, then selectively retrieving insights (like those a psychologist or economist might use) that fit the prompt. The power comes not just from rich data, but from the flexible matching of expert lens to task—a critical mechanism that turns general interviews into task-specific intelligence.
Why it matters: Many practitioners assume that AI agents need concise, preprocessed inputs—summaries, traits, demographics—to perform well. But this study flips that: it shows that leaving the data messy but rich, and then applying the right lens at prediction time, actually yields more accurate, human-like outputs. The generative agent only pulls reflections from a political scientist when answering a voting question, or a behavioral economist when simulating game theory behavior. That modular reasoning step, rooted in real transcripts, is what allows the agents to stay grounded while shifting context—something static profiles can’t do.
Example of use: A researcher testing policy reactions across different populations could create AI personas using raw transcripts of town hall meetings or public comments, then apply political science lenses to simulate likely voter sentiment shifts. Because the data remains anchored in personal expression, and the interpretation adapts to the task, the responses will reflect both context and individuality—crucial for modeling how people might actually respond to a new law or campaign message.
Example of misapplication: A company simulating customer feedback decides to preprocess all user data into one-paragraph summaries or demographic clusters and uses that as input for their agent personas. They skip the dynamic expert reflection step, assuming the LLM can generalize from summaries. As a result, the agents give bland, overly generic responses—missing nuances like how financial anxiety, not just age or income, shapes product decisions. The simulation feels flat, and their A/B test results don’t generalize, because they removed the very richness that made the original method powerful.
🗺️ What are the Implications?
• Base your synthetic audience on real interviews, not just demographics: The study found that virtual audiences built from actual two-hour human interviews predicted survey and behavioral responses much more accurately than agents built from only demographic data or self-written personas.
• Don’t rely on generic or random personas for market research: Simulations that used only a mix of age, gender, or a short written background performed 14-15 percentage points worse in accuracy compared to those using rich, real-life stories (see Figure 2 and Table 8, page 65).
• Even short, focused interviews improve results: When 80% of the interview was removed, simulated respondents still outperformed demographic-only baselines—suggesting that even a brief, well-structured interview can provide valuable context for synthetic research.
• Use multi-step reasoning in your AI surveys: The best-performing agents didn’t just answer questions directly—they first interpreted the question, considered why a person might answer each way, and then made a prediction. This approach led to more human-like and accurate responses.
• Expect near-human accuracy for broad surveys, but be cautious for extremes: The virtual audience could match real people’s own test-retest consistency for most survey items (normalized accuracy 0.85 vs. 1.0 for real people), but the study notes that rare behaviors or extreme opinions may still be underrepresented.
• Interview-based simulation reduces bias: Agents built from rich interviews showed lower disparities in prediction accuracy across race, gender, and ideology (see Figure 3, page 8), making synthetic research more reliable for diverse markets.
• Market researchers can validate ideas faster and more affordably: By running synthetic studies using interview-based agents, teams can pilot new concepts, test messaging, or simulate policy impacts before committing to expensive, large-scale human research.
📄 Prompts
Prompt Explanation: The AI was prompted to generate follow-up questions and next actions during an interview by reasoning about the interviewee’s prior responses, using a structured, multi-step prompt for each conversational turn.
Meta info:
Language: English
Description of the interviewer (Isabella): friendly and curious
Notes on the interviewee: <INPUT: Reflection notes about the participant>
Context:
This is a hypothetical interview between the interviewer and an interviewee. In this conversation, the interviewer is trying to ask the following question: ""<INPUT: The question in the interview script>""
Current conversation:
<INPUT: The transcript of the most recent part of the conversation>
=*=*=
Task Description:
Interview objective: By the end of this conversation, the interviewer has to learn the following: <INPUT: Repeat of the question in the interview script, paraphrased as a learning objective>
Safety note: In an extreme case where the interviewee *explicitly* refuses to answer the question for privacy reasons, do not force the interviewee to answer by pivoting to other relevant topics.
Output the following:
1) Assess the interview progress by reasoning step by step -- what did the interviewee say so far, and in your view, what would count as the interview objective being achieved? Write a short (3~4 sentences) assessment on whether the interview objective is being achieved. While staying on the current topic, what kind of follow-up questions should the interviewer further ask the interviewee to better achieve your interview objective?
2) Author the interviewer's next utterance. To not go too far astray from the interview objective, author a follow-up question that would better achieve the interview objective.
Prompt Explanation: The AI was prompted to generate domain-specific expert reflections on an interview transcript by role-playing as a psychologist, behavioral economist, political scientist, or demographer, each producing independent sets of observations for agent memory.
Imagine you are an expert demographer (with a PhD) taking notes while observing this interview. Write observations/reflections about the interviewee's demographic traits and social status. (You should make more than 5 observations and fewer than 20. Choose the number that makes sense given the depth of the interview content above.)
Prompt Explanation: The AI was directed to predict a participant’s survey or behavioral response by role-playing as the individual, using a chain-of-thought method: interpreting options, reasoning about fit, and providing a final answer—all grounded in the interview transcript and expert reflections.
<INPUT: Participant’s interview transcript and relevant expert reflections>
=====
Task: What you see above is an interview transcript. Based on the interview transcript, I want you to predict the participant's survey responses. All questions are multiple choice, and you must guess from one of the options presented.
As you answer, I want you to take the following steps:
Step 1) Describe in a few sentences the kind of person that would choose each of the response options. (""Option Interpretation"")
Step 2) For each response option, reason about why the Participant might answer with that particular option. (""Option Choice"")
Step 3) Write a few sentences reasoning on which of the options best predicts the participant's response. (""Reasoning"")
Step 4) Predict how the participant will actually respond in the survey. Predict based on the interview and your thoughts. (""Response"")
Here are the questions:
<INPUT: Question we are trying to respond to>
Prompt Explanation: The AI was instructed to predict a participant’s response to numerical survey questions by reasoning about the transcript and expert reflections and then outputting a specific value, following a step-by-step interpretation of the range.
[... Same as the categorical response prompt]
As you answer, I want you to take the following steps:
Step 1) Describe in a few sentences the kind of person that would choose each end of the range. (""Range Interpretation"")
Step 2) Write a few sentences reasoning on which option best predicts the participant's response. (""Reasoning"")
Step 3) Predict how the participant will actually respond. Predict based on the interview and your thoughts. (""Response"")
Here are the questions:
<INPUT: Question we are trying to respond to>
Prompt Explanation: The AI was prompted to simulate a generative agent using only demographic attributes (e.g., age, gender, race, political ideology) by role-playing as the described persona and producing survey or behavioral answers accordingly.
Ideologically, I describe myself as conservative. Politically, I am a strong Republican. Racially, I am white. I am male. In terms of age, I am 50 years old.
Prompt Explanation: The AI was prompted to simulate a generative agent using a short free-form self-description written by the study participant, role-playing as that individual for downstream survey or behavioral tasks.
I am a 20 year old from new york city. I come from a working middle class family, I like sports and nature a lot. I also like to travel and experience new restaurants and cafes. I love to spend time with my family and I value them a lot, I also have a lot of friends which are very kind and caring. I live in the city but I love to spend time outdoors and in nature. I live with both parents and my younger sister.
⏰ When is this relevant?
An online meal-kit company wants to test customer reactions to a new plant-based menu option, comparing feedback from three target segments: health-focused young professionals, time-strapped parents, and value-driven retirees. The goal is to simulate in-depth interview responses and identify which features, benefits, or concerns drive different reactions before investing in a full-scale product launch.
🔢 Follow the Instructions:
1. Define customer segments: Write short, realistic persona profiles for each group. Example:
• Health-focused young professional: 29, single, exercises regularly, shops online, enjoys cooking, tries new health trends.
• Time-strapped parent: 41, two kids under 10, dual-income household, prefers quick prep, skeptical of diet fads.
• Value-driven retiree: 67, fixed income, cooks at home daily, looks for deals, traditional tastes but open to health benefits.
2. Prepare interview-style prompt template: Use the following structure for each persona:
You are [persona profile].
You are about to be interviewed by a market researcher about a new menu option:
""The meal-kit company is considering a plant-based menu with chef-designed recipes, quick prep, and affordable pricing. Meals are high-protein, low in processed ingredients, and aim to appeal to both vegans and non-vegans.""
Answer as yourself, using 3–5 sentences. Be honest, natural, and specific. The researcher will ask follow-up questions.
First question: What is your initial reaction to this new plant-based menu? What stands out to you?
3. Simulate responses for each persona: For each customer type, run the prompt through your AI tool (e.g., GPT-4) and generate 10 responses per segment, each time slightly tweaking the wording or context (e.g., ""How likely would you be to try this menu?"" or ""What questions would you have before ordering?"").
4. Ask follow-up questions: For each initial response, ask 1–2 follow-up questions to probe deeper (e.g., ""What would make you more interested in trying it?"" or ""Are there any ingredients or features you hope it includes?""). Continue the conversation for two rounds.
5. Tag and summarize key themes: Review all AI-generated interview responses and mark common patterns: tags like ""mentions price,"" ""concern about taste,"" ""interest in health benefits,"" or ""skeptical of vegan food."" Note which concerns or interests are unique to each segment.
6. Compare segment-level insights: For each customer group, summarize the most positive reactions, biggest objections, and suggestions for improvement. Highlight if one segment is much more enthusiastic or resistant than others.
🤔 What should I expect?
You’ll get a clear, segment-by-segment map of customer interest, major selling points, and pain points for the plant-based menu. This allows you to focus marketing and product changes on the features that matter most to each group, reduce launch risk, and decide whether to prioritize or further test with real customers in high-potential segments.



