Retrieval-augmented Generation for Knowledge-intensive Nlp Tasks
postPatrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
Published: 2021-04-12

🔥 Key Takeaway:
The “secret weapon” isn’t giving your AI more training or bigger models—it’s letting it look things up, just like a human Googling in real time; the less you trust the AI’s built-in “knowledge,” and the more you force it to use fresh, external sources, the closer you get to real-world answers.
🔮 TLDR
This paper introduces Retrieval-Augmented Generation (RAG), a method that combines large pre-trained language models with an external, updatable knowledge base (like Wikipedia) to improve performance on knowledge-intensive NLP tasks. RAG models retrieve relevant documents for each query and use them as context for generating answers or classifying information, which allows them to be more accurate, specific, and less prone to hallucination than standard language models. On benchmarks like open-domain question answering, fact verification, and question generation, RAG outperforms both parametric-only models (like T5 and BART) and previous retrieval-based systems, achieving up to 44.5% exact match on Natural Questions (vs. 41.5% for previous best) and showing higher human ratings for factuality and specificity. Key actionable insights: (1) combining retrieval with generation is crucial for factual accuracy, (2) the retrieval index (knowledge base) can be hot-swapped without retraining to update model knowledge, (3) training with multiple relevant documents improves performance and diversity, (4) dense retrieval (using neural embeddings) generally outperforms keyword-based retrieval except for highly entity-centric tasks, and (5) using both parametric (model weights) and non-parametric (external memory) sources enables more scalable and updatable systems for tasks where models must mimic real-world knowledge access.
📊 Cool Story, Needs a Graph
Table 1
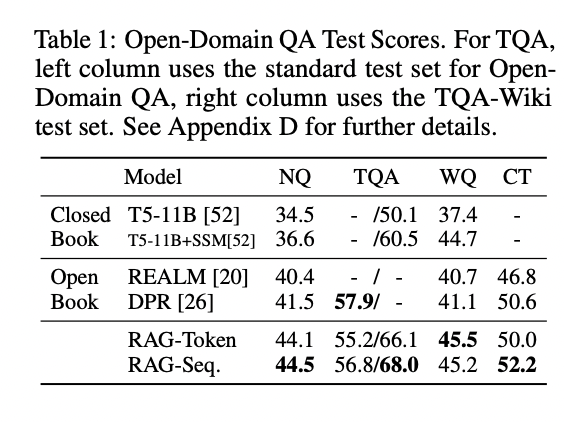
Side-by-side tables showing how RAG models outperform both parametric and retrieval-based baselines across QA, generation, and classification tasks.
Table 1 (Open-Domain QA Test Scores) and Table 2 (Generation and classification Test Scores) on page 6 together present a comprehensive numeric comparison of all major models, including the proposed RAG-Token and RAG-Sequence, closed-book baselines (T5-11B, BART), open-book retrieval baselines (REALM, DPR), and state-of-the-art results where available. They report exact match or accuracy on Natural Questions, TriviaQA, WebQuestions, CuratedTrec, MS-MARCO, Jeopardy Generation, and FEVER tasks. This side-by-side layout allows direct assessment of improvements and trade-offs in all settings, making it easy to see that RAG models consistently achieve the highest or near-highest scores across the board.
⚔️ The Operators Edge
One detail that’s easy to overlook—but crucial to why this method works so well—is that the document retriever is jointly fine-tuned with the generator during the actual downstream task, instead of being left frozen or used off-the-shelf. While the retriever starts with general-purpose knowledge (like Wikipedia or QA pairs), it’s the fact that it learns to fetch the most task-relevant evidence on the fly—guided by feedback from how well the generator answers questions or classifies claims—that dramatically increases the factual accuracy and specificity of the results.
• Why it matters: Most experts might assume the “magic” comes from the retrieval model’s initial quality or the sheer size of the index. In reality, it’s the *dynamic adaptation*—as the retriever is fine-tuned to pull what the generator actually needs for the task at hand—that keeps the system grounded, minimizes hallucinations, and makes the AI’s responses genuinely useful, even as the target domain shifts.
• Example of use: Suppose a team is running synthetic customer interviews for a new fintech app. By fine-tuning the retriever together with the response generator, the system learns to surface up-to-date regulations, recent customer reviews, or new feature documentation—so when the AI “persona” is asked about security or fees, it brings in highly relevant, timely references, making the simulated answers both realistic and trustworthy.
• Example of misapplication: If the team skips joint fine-tuning and just uses a generic, pre-trained retriever (or, worse, a keyword-matching search), the AI personas will often cite outdated, irrelevant, or generic information—leading to plausible-sounding but misleading or superficial answers. In product testing, this could result in simulated feedback that’s either too bland or outright wrong about current features, causing teams to miss market risks or overestimate product readiness.
🗺️ What are the Implications?
• Combine AI with external, real-world information for better accuracy: The study shows that AI simulations grounded in external documents or databases (not just relying on the AI’s internal “memory”) produce more factual, specific, and credible results. For market research, this means referencing up-to-date, relevant sources—such as news, reviews, or product descriptions—when running synthetic studies.
• Update your knowledge base easily to reflect new trends: With retrieval-augmented approaches, you can update what your virtual personas “know” simply by swapping in new data sources. This is much faster and more cost-effective than retraining an AI from scratch, making it practical to keep your synthetic audience current as the market evolves.
• Don’t rely solely on AI’s built-in knowledge for niche or recent topics: The model’s internal knowledge can be outdated or incomplete, especially for new products, social trends, or emerging issues. Supplementing with targeted retrieval ensures responses reflect the state of the market as it is today, not just as it was when the model was trained.
• Use multiple relevant sources for richer, more nuanced responses: The research found that pulling in several documents for each inquiry led to more diverse and robust answers, reducing the risk of “hallucinated” or generic output. For business studies, this means casting a wide net when selecting reference materials for your simulated audience.
• Fact-check synthetic results with a small human panel when stakes are high: Since AI models can sometimes generate plausible but incorrect statements, it’s wise to validate key findings from your virtual studies with a real human sample before making major business decisions.
• Test and calibrate the retrieval process: The way you select and present background information to the AI makes a measurable difference. Regularly review which sources are being used and adjust as needed for relevance and quality—think of this as curating the “reading list” for your virtual audience.
• You don’t need the largest or most expensive AI to see these benefits: The study shows that smart use of retrieval and external knowledge often matters more than the underlying model size, so resources are better spent on good data and process design than on the most advanced AI available.
📄 Prompts
Prompt Explanation: The AI was prompted to generate Jeopardy-style trivia questions based on a given entity, relying on factual knowledge and emphasizing specificity and factuality.
Generate a Jeopardy-style question given the answer entity: {entity}. The question should be specific, factually accurate, and refer to unique, verifiable information about the entity.


